

The GPT Era
A look back at the timeline from ~GPT-3.5 to today.

This post is based on a talk I gave to a cohort of YC founders, as part of a 6-week course on getting up to speed on LLMs. It’s been edited/updated for easier written consumption.
When ChatGPT launched, I instinctively felt this was going to be a big deal. I'd seen some rumblings around GPT-3 and Stable Diffusion, but ChatGPT felt different. My day job had nothing to do with AI1, but I wanted to learn and document that journey publicly. That led to this publication, Artificial Ignorance.
"Ignorance" isn't just a play on "Artificial Intelligence." It reflects something fundamental about this moment: we're all ignorant about this technology. Even the researchers at OpenAI, with all their benchmarks and internal testing, aren't fully aware of everything these systems are good at or bad at. Ethan Mollick calls this "The Jagged Frontier." We're all learning as we go.
That learning curve has taken us through one of the most remarkable technological transitions in recent memory. Looking back, the story of the last few years breaks down into distinct chapters: the explosive boom of 2023, the maturation and competition of 2024, and now the uncertain but promising landscape of 2025.
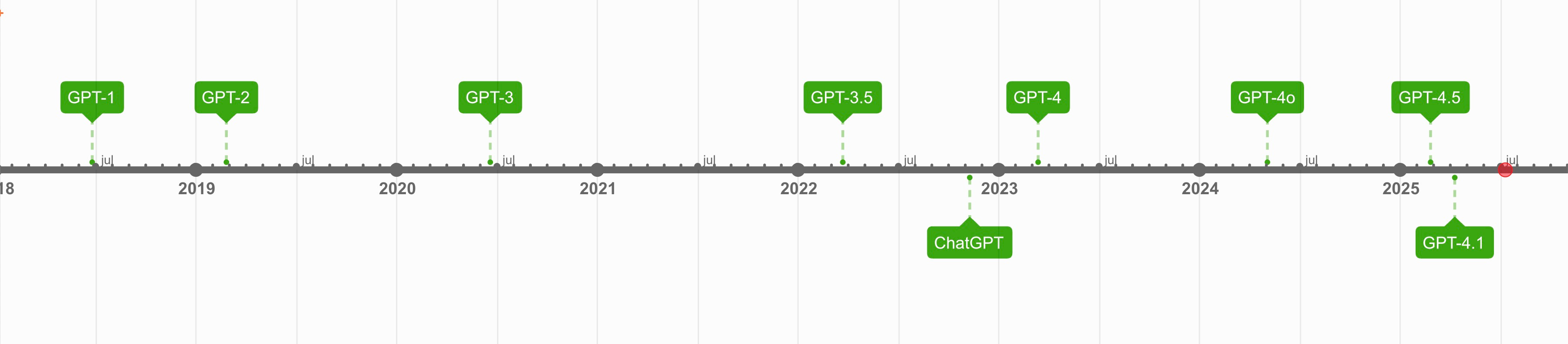
The GPT Timeline
To understand where we are, it helps to trace the lineage of GPTs, since OpenAI has largely set the stage for this modern era of generative AI. GPT-1 traces back to June 2018, but GPT-3 in June 2020 was the first to get serious attention from developers and startups because it was available as an API. Companies like Jasper and Copy.ai were already experimenting with GPT-3, learning what would come to be known as "prompt engineering" and building with LLMs long before most people had heard of any of this.
Fun fact: GPT-3.5 actually came out several months before ChatGPT itself. But it took that final step of baking in reinforcement learning from human feedback (RLHF) to turn it into a compelling product. The gap from GPT-3 to 3.5 was about knowledge and intelligence. The gap from 3.5 to ChatGPT was about UX and usability.
Then came the one-two punch that really kicked off the AI boom: ChatGPT in November 2022, followed by GPT-4 in March 2023. If ChatGPT was the Terminator, GPT-4 was the T-1000.

2023: The Boom and the Backlash
ChatGPT's growth was unlike anything we'd seen - zero to 100 million monthly active users in just two months. But GPT-4 was what blew everyone away. If you haven't seen the original demo video, Greg Brockman (among other things) sketches a website mockup on a napkin, takes a photo, and GPT-4 turns it into working HTML and CSS. The model scored in the top 10% on a simulated bar exam2. Microsoft researchers claimed to see "sparks of AGI."
As good as it was at launch, it also proved surprisingly hard to beat. GPT-4 held the top spot on almost every benchmark for over a year - an eternity in generative AI terms. OpenAI really made something remarkable with this model.
Unsurprisingly, people freaked out.
Suddenly, everyone was concerned. IP holders filed class-action lawsuits. AI-generated Drake songs went viral, making record labels nervous. User-generated content companies like Reddit and Stack Overflow decided to paywall their data. Politicians got involved - Sam Altman testified before Congress, senators unveiled AI frameworks, and President Biden signed a sprawling AI executive order.

Fear hit an all-time high. AI CEOs literally went before Congress and said this technology could lead to the end of humanity; though looking back, it seems like that was when the hysteria peaked.
Meanwhile, Big Tech scrambled to respond. There was this prevailing narrative of "What is Google doing? They're supposed to be the AI company!" Even now, Siri and Alexa still don't have many LLM-powered features, creating this perception that some teams can't get it together on generative AI.
Meta took the outlier position of releasing open models. The first version of Llama was leaked via 4chan, and then they embraced that momentum and structured subsequent releases as proper open source.
But, ultimately, nearly every single company (or so it felt) started adding "AI" to its product, with some even going so far as to get stock market pops by "pivoting to AI."

2024: Model Mayhem and Incremental Improvements
As 2024 unfolded, things didn't necessarily settle down, but we got more clarity. A clear competitive landscape emerged around a few leading players: OpenAI, Anthropic, Google DeepMind, and xAI3, while the open-source world flourished with Meta's Llama, DeepSeek, Mistral, and many others.
We also saw something resembling an oligopoly. Companies like Inflection, Adept, and Character.ai - which were the hot AI startups in 2023 - saw their founding teams get “acquired” (i.e., poached) by Big Tech, leaving the rest of these companies in limbo4.
But the real story of 2024 was how much better everything got, across three key dimensions:
Models Got Better

The competition finally caught up to GPT-4, with multiple rivals arriving: Claude 3.5 Sonnet and Gemini 2.5 Pro, then Llama 3.3 and DeepSeek V3. We hit widespread benchmark saturation - many metrics we used to map AI progress lost much of their utility very quickly.
This created a real problem: how do you make complex tests for ever-improving AI systems? Some tests are being written by a handful of PhDs at the top of their fields; others (like ARC-AGI) find areas of generalized knowledge that LLMs are still bad at, like spatial reasoning.
Context windows exploded from 16K to 2 million tokens - you can now feed half a dozen novels into the latest Gemini models without issue. Multimodality added video: you can give Gemini a YouTube link, and it will watch the video in real time and tell you what's happening. GPT-4o introduced true multimodal training across text, images, and audio, enabling features like advanced voice mode, where you can ask it to talk faster or in a British accent, and it actually understands what that means (or, more recently, you can ask it to Studio Ghibli-fy almost anything).
We saw realistic image generation reach the point where the old joke of "just look for the hands" is no longer reliable. Tool usage evolved into agentic workflows. Costs dropped dramatically - about 10x decrease in token cost per year, with faster models for more use cases and features like prompt caching.
New frontiers opened up: world models, robotics models, reasoning models, browser-use models. Each of these represents entire categories of capability that barely existed a year earlier.
Products Got Better
The consumer experience also became much richer. We got artifacts and canvases, memory features, web search integration, and breakthrough products like NotebookLM and Deep Research. These weren't necessarily dependent on 10x smarter models - they depended on much better product sense and design.
I’ve written about some of this before:
The basic capabilities of AI systems are becoming standardized across providers, so whether you're using Claude, GPT, Gemini, or Grok, you can increasingly expect similar core functionality. This is good news for users, as it means less lock-in to any individual AI ecosystem.
But it does mean that there’s more pressure to improve the productization of these models, as we’re seeing above. Research breakthroughs are difficult, if not impossible, to keep secret in the long run. Therefore, the differentiating innovations are happening on the product (not research) side.

AI Engineering Got Better
The developer experience became more powerful too. Structured outputs and JSON mode solved reliability problems that had plagued LLM applications. Model Context Protocol (MCP) servers enabled better integration. AI-powered IDEs like Cursor emerged, offering coding experiences that feel magical when they work well.
We figured out how to build better AI applications. Prompt engineering matured from "please be helpful" to sophisticated techniques for getting reliable outputs. Evaluation design and implementation became standard practice. RAG (Retrieval-Augmented Generation) pipelines evolved into production-ready systems.
LLM monitoring and observability tools emerged to help teams understand what their models were actually doing. Fine-tuning and inference platforms made it easier to customize models for specific use cases. Agentic frameworks started appearing to help build more sophisticated AI workflows.
All of this happened alongside massive investment surges. Nvidia hit a $3 trillion valuation. Project Stargate announced a $500 billion investment plan. Big Tech committed tens of billions to data center infrastructure. The long tail of AI funding continued - YC's Fall 2024 batch was nearly 90% AI startups.

The Trillion Dollar Question
But as we reached the end of 2024, one question was on everyone's mind: Has AI progress hit a wall? As Ilya Sutskever put it, "We've achieved peak data, and there'll be no more." And it's still unclear whether we can continue scaling parameters and training data by 10x every year.
For pre-training text, the answer is probably no - not unless we hit real breakthroughs in synthetic data generation. Many companies are experimenting with AI to generate training data for better AI, but my intuition is that it probably won't work. LLMs predict the most likely next token, which tends toward least-common-denominator outputs. What makes training data good is diversity and realism of potential situations, not the smoothed-out averages that LLMs tend to produce5.
But we also opened up this new frontier of reasoning models, where instead of baking all the compute and training upfront, we can spend compute to have the model "think" longer or harder. It's not a complete solution to the scaling problem, but it bought us time.
I think of reasoning models as the difference between thinking in pencil versus pen. Previous models were locked into their first answer - if they started generating something, they would justify whatever they initially said, even if they said something contradictory later. Reasoning models can do the equivalent of crossword puzzles in pencil: they can make a guess, then, based on other clues, backtrack and try a different route.
2025: Where We're Headed
Reasoning models are already seeing intense competition. We have OpenAI's o-series, Anthropic's Claude 4, Google's Gemini variants, DeepSeek's R1, and xAI's Grok. If anything, reasoning models are quickly becoming table stakes for AI labs, and the default choice for serious AI users. The next frontier will undoubtedly be hybrid models that automatically figure out when to use more thinking time, similar to how current models decide when to use tools.
This year has also been widely dubbed "The Year of Agents" - though there's been a lot of hype around this concept since AutoGPT in 2023. There's still some time left in the year, but I suspect that much of the hype will fail to materialize in the short term. So many companies and products rushed to put "agent" in their landing pages and pitch decks, when most folks likely don't even have a consensus definition of what an agent is. Zapier fits many people's definition - it's software that takes actions on your behalf, optionally using an LLM - but I wouldn't necessarily call it an agent.
I think about agents as having three key characteristics: autonomy, adaptability (including planning), and action orientation. We're already seeing narrow agents that work really well. I use Cursor's coding agent almost daily, and as I've pointed out, we're rapidly moving from coding agents on your computer, to coding agents in the cloud, to fleets of agents at your disposal.

Deep Research also seems to be a valuable agentic use case, though as with any AI product, it's essential to know its limitations. General-purpose agents - like browser-based agents where you tell it what to do - are still a way out if benchmarks are any indication. Still, you can build powerful agentic experiences tailored to specific domains.
On the regulatory front, the US has taken a dramatic turn with the change in administration. President Biden's AI Executive Order has been mostly undone, as the Trump administration is taking a more hands-off approach. While there may be a more opinionated AI framework to come, only time will tell.
At the state level, the regulatory landscape has been quite active. While dozens of state-level AI bills have emerged, mostly targeting deepfakes and specific use cases, the most significant proposed legislation (California's SB 1047, a far-reaching AI safety bill) was vetoed by Governor Newsom. With federal oversight decreasing, states are increasingly looking to fill the regulatory gap, but the SB 1047 veto suggests even California - traditionally a leader in tech regulation - is hesitant to move too aggressively.
And all that said, there’s still an enormous amount of anxiety over the rapid changes being brought about by AI - with many thorny questions around deepfakes, copyright, job displacement, and AI slop still lacking satisfying answers.

The Practical Reality
One insight that's emerged from watching this space closely: the business use case should be to focus on building a great product, and then swap out the engine when better technology comes along. There are cases where building your own model makes sense - Cursor trained a model specifically on creating diffs between ChatGPT outputs and files, which became an advantage - but it wasn't about teaching a model to write better code, it was about training a model to create a better user experience.
The highest-feedback-loop way to build AI products may be to start with internal tools. Build prototypes, give them to actual users, learn where they break in unexpected ways, and then bake those learnings back into better prompts or evaluations.
As we navigate this landscape, I think maintaining a practical perspective is key. Human decision makers still have to decide to buy software and replace humans with AI. That transition will take longer than most AI enthusiasts imagine, even if the technology continues improving rapidly.
We're living through a remarkable technological transition, but we're also all learning as we go. The future is uncertain, but it's being built by people figuring it out one experiment, one product, and one breakthrough at a time. That's both humbling and exciting - and exactly why I started writing Artificial Ignorance in the first place.
I was running a merch company for influencers, spending my days thinking about t-shirt designs and shipping logistics
This claim has since come under some fire - while GPT-4 definitely "passed the bar," grading irregularities have undermined the specific "top 10%" headline.
One standout story is xAI's execution speed. They stood up a 10,000 GPU supercomputing cluster in about six months - an almost unbelievable timeline that most attribute to Elon Musk's approach to removing roadblocks. There was an interview where he talked about data centers having 18-month lead times, which would be death for an AI company. So they found abandoned factories that could support the power draw, brought in Tesla's battery infrastructure to smooth out power needs, and diverted Nvidia chip shipments originally meant for Tesla. He's probably one of the few people in the world who could have pulled that off.
Funnily enough, Mark Zuckerberg and Meta are repeating this strategy, paying unfathomable sums of money to recruit AI leaders from companies like Scale.
That said, I'm certainly not an AI researcher! Just an engineer who keeps up with the space - so take all this with a grain of salt.
Great piece. Thank you so much!
I really needed to read this overview. Thanks.
In your concluding image of problems/concerns, you list "societal impacts" and thus, I think, importantly miss "psychological impacts." My entire Substack is dedicated to demonstrating that we are overlooking, at our peril, that AI will alter our interior worlds at least as much as our external worlds.
See if you agree--and I'd be very interested to learn why you do not, if you do not!
https://mindrevolution.substack.com/p/ai-is-launching-a-fourth-revolution?r=2cybp