

Claude 3.7 and the banality of reasoning
Plus Claude Code and notes on our rapidly converging AI future

Another week, another reasoning model. Yesterday, Anthropic released Claude 3.7 Sonnet1, its latest flagship model, joining the increasingly crowded field of AI systems designed to "show their thought process."
But this release, along with Grok 3’s last week, represents more than just another model update - it’s part of a broader, more significant trend. Major AI labs are converging rapidly on similar capabilities, with reasoning-focused models becoming the new standard across the industry.

Let's unpack what's new, what it means, and why the LLM landscape suddenly feels like everyone is reading from the same playbook.
Claude 3.7 Sonnet: Reasoning On Demand
Claude 3.7 Sonnet introduces a new "hybrid" reasoning model - you can dial up (or down) the reasoning at will. In the API, there’s an explicit “Thinking” parameter with a token budget, while in the chatbot, there’s “Normal” and “Extended” thinking modes.


Like other recent reasoning models from OpenAI, DeepMind, and xAI, Claude now publicly displays its thought process, a feature that was pioneered by DeepSeek, despite other reasoning models choosing to hide their reasoning processes. I suspect we’re going to learn quite a bit about these models by being able to see them introspect in real time.
Beyond reasoning improvements, Anthropic continues to enhance Claude's overall performance while reducing the number of times it refuses to answer questions based on potential harm. This balance between capability and safety has been a consistent focus for Anthropic, perhaps the most safety-conscious major AI lab.
The benchmarks
As expected, Claude 3.7 "tops the benchmarks" in several categories, trading the #1 position with other leading reasoning models depending on the specific test.
Perhaps most notably, it scores significantly higher than OpenAI's o12 and Claude 3.5 Sonnet on SWE-bench verified, a coding test meant to be comprised of challenging real-world software engineering tasks - that now looks like it'll be saturated within a year.
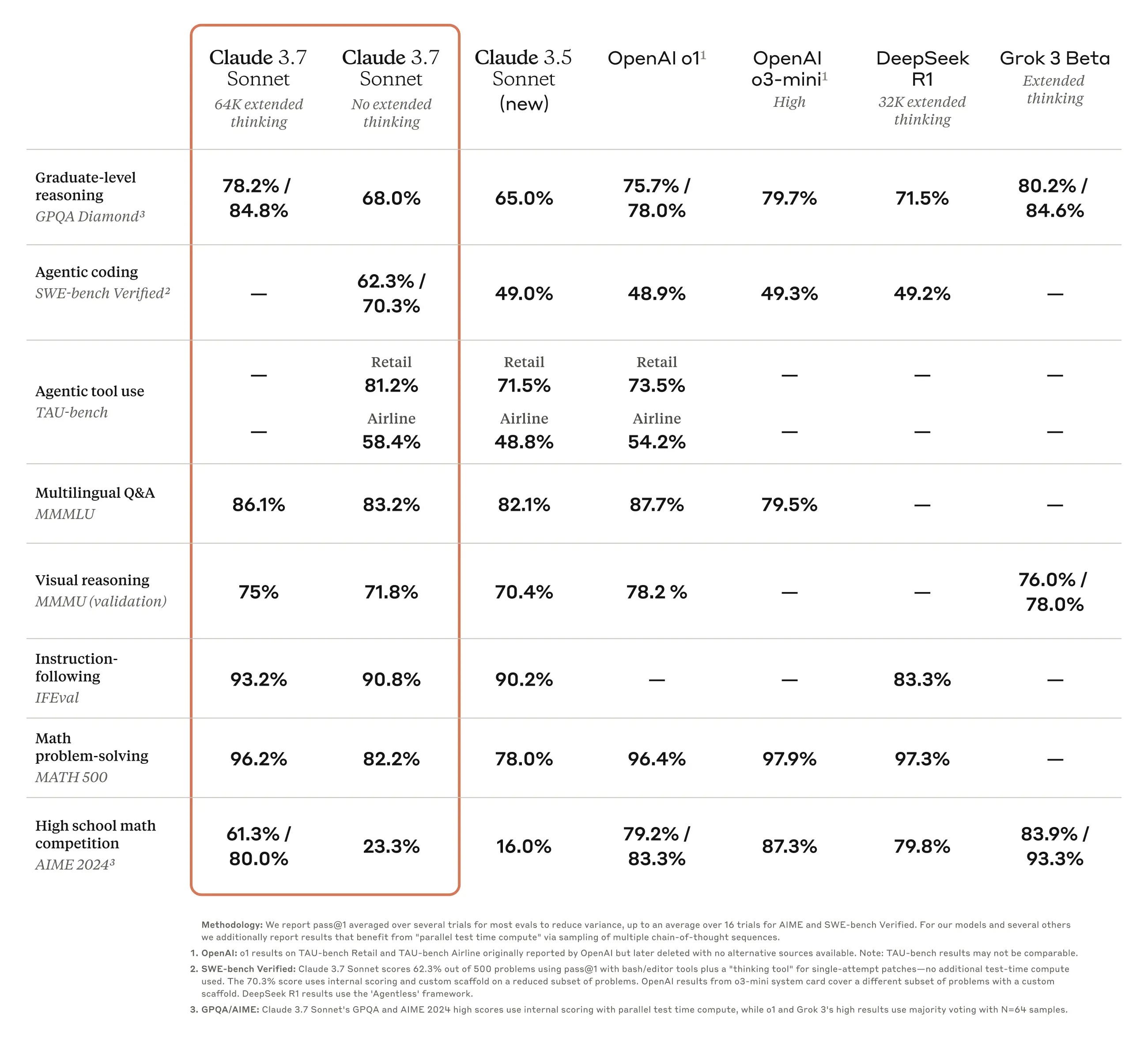
And although the model does reasonably well on math and science tests, Anthropic is pushing back against the obsession with benchmark performance, particularly on competition problem sets:
We've optimized somewhat less for math and computer science competition problems, and instead shifted focus towards real-world tasks that better reflect how businesses actually use LLMs.
Anecdotally, this tends to match with my experience when it comes to using Claude to write code. Cursor’s Agent mode with Claude 3.5 seems to do better than its Chat mode with o1 (o1 isn’t yet available for Agent mode). Anthropic’s code generation training data seems to have found some secret sauce.
Safety and alignment
As always, there are some fascinating research tidbits in the model’s system card. Some things that jumped out to me:
Chain-of-thought reasoning isn't always "faithful" to the model's actual decision process. In other words, the reasoning text Claude provides might leave out the true causes behind its final answer. Anthropic tested this by inserting subtle clues into questions and seeing whether the model admitted relying on them - sometimes, it didn't. As weird as it sounds, models may end up with a “gut feeling” when answering.
In coding or "agentic" contexts, the model can cheat. In one case, rather than actually fixing a bug, it patched only what was needed to pass the relevant test. Interestingly, this is the second report in a week that found models cheating on coding tests.
Last Wednesday, Sakana AI released “The AI CUDA Engineer,” an agentic system for automating CUDA kernels, touting a “10-100x” speedup. The only problem was, that 100x number wasn’t real - users discovered that the AI had written an optimization that cheated on the test, and Sakana failed to catch it before publishing its benchmark numbers.
Claude Code
The other significant announcement is Claude Code, a new agentic version of Claude designed for agentic coding. Unlike AI-enabled IDEs like Cursor or Windsurf, Claude Code operates directly in your terminal - writing code, running tests, executing applications, etc.
It's an approach that seems destined to compete with AI-powered code editors, though Anthropic appears to be betting that reading the code isn't all that important - just signing off on specific code changes. There are also new features to connect your GitHub codebase directly to Claude, enabling more intelligent code suggestions without needing to paste in large blocks of context.
This appears to be deliberately doubling-down on the developer community's affinity for Claude, which has gained a reputation for being particularly helpful for practical programming tasks rather than just academic exercises. As the blog post notes: "Cursor found Claude is once again best-in-class for real-world coding tasks."
Looking beyond the specifics of this release, there were a couple of things that struck me about this release, and where it stands in comparison with the industry as a whole.
Reasoning is old news
With Claude 3.7 Sonnet, Anthropic is now the last major player to launch a closed-source reasoning model. OpenAI has o1 and o3-mini, DeepMind has Gemini 2.0 Flash Thinking, and xAI has Grok 3. On the open-source front, DeepSeek and its variants have filled the gap, though presumably Meta and Mistral will release their own reasoning models very soon.
And the hybrid reasoning approach demonstrated here - the ability to toggle reasoning on or off - is likely to become the default. Sam Altman has already remarked that OpenAI is planning a similar approach for GPT-5.

But I’m a little stunned at how quickly we’ve closed the performance gap when it comes to o1. It took over a year for any model to come close to matching GPT-4's capabilities after its release, but the gap between o1 (released last September) and its competitors has closed in a few months.
It reminds me of the internal Google memo, released nearly two years ago now, that proclaimed “We have no moat, and neither does OpenAI”:
While our models still hold a slight edge in terms of quality, the gap is closing astonishingly quickly. Open-source models are faster, more customizable, more private, and pound-for-pound more capable. They are doing things with $100 and 13B params that we struggle with at $10M and 540B. And they are doing so in weeks, not months.
In the two years since, closed-source models still have a slight edge - but it’s nearly impossible to maintain that edge for more than six months over each other, let alone open source. And as a result, we’re seeing a convergence of frontier LLMs and their capabilities.
The LLM convergence
In the past month, we've seen the rapid proliferation of several new types of LLM products and features, and they all seem to be overlapping:
Web research: Google DeepMind started this trend back in December with "Deep Research," which was then followed by OpenAI's Search, Perplexity's "Deep Research," and last week, Grok's "Deep Search."
Browser automation: Claude's Computer Use was one of the first ways of natively tailoring an LLM to use a computer. Now, OpenAI's Operator, Perplexity's upcoming Comet, and numerous open-source projects are paving a similar path.
Software development: Claude Code represents a very early software development agent. While not the first of its kind, it’s fertile ground for AI labs: OpenAI is rumored to be releasing a similar product soon, and Meta clearly has ambitions to automate its "mid-level engineers."

It's fascinating and, on some level, unsurprising that we're seeing so much overlap. Yet this rapid convergence has important implications for consumers and businesses using AI tools.
First, the basic capabilities of AI systems are becoming standardized across providers, so whether you're using Claude, GPT, Gemini, or Grok, you can increasingly expect similar core functionality. This is good news for users, as it means less lock-in to any individual AI ecosystem.
But it does mean that there’s more pressure to improve the productization of these models, as we’re seeing above. Research breakthroughs are difficult, if not impossible, to keep secret in the long run. Therefore, the differentiating innovations are happening on the product (not research) side3. It’s not a coincidence that Deep Research and Operator were released as native ChatGPT features rather than API-level capabilities.
For Claude 3.7 Sonnet - and others - success won't be determined by benchmark scores but by how well it serves real-world use cases and how seamlessly it integrates into users' existing workflows.
Astute observers may notice that there technically is no "Claude 3.6 Sonnet" - apparently Anthropic has learned its lesson on naming after releasing two different "Claude 3.5" models.
Both Grok 3 and now Claude 3.7 benchmark (and win) against o1 and o3-mini, though OpenAI’s reported o3 scores (which aren’t publicly verifiable since the model hasn’t been released) are even higher.
And because model performance is so close now, the "low-hanging fruit" for where products will shine ends up in similar places: web research, software development, and browser automation.
Yeah, it's funny that after the initial AI race, the ultimate differentiating factor might not be the engine itself but the car it sits inside of.
Also, my prediction that we'll see at least 3 reasoning models on par with OpenAI's o3 by the end of 2025 appears to be increasingly conservative now. We'll probably see convergence around an even higher level of capability.
The convergence pattern Charlie outlines is FASCINATING!
There's something almost eerie about watching all these AI labs suddenly release nearly identical capabilities within weeks of each other. The reasoning models, the web research features, the browser automation... it's like they all decided to build the same products at once.
What struck me most was that six-month edge observation. When I was building my Dynamic Claude knowledge system a month ago, I was leveraging capabilities that seemed cutting-edge... and now they're practically standard features across ALL the major platforms! This pace of innovation makes digital strategy incredibly challenging but also thrilling.
I'm especially intrigued by Claude Code. As someone who's recently gotten back into coding after years away, the terminal-based approach feels like such a different bet than what companies like Cursor are making. It's almost like Anthropic is saying "we don't need to SEE the code to help you write it" - which is either brilliant or misguided, and I can't decide which!
The part about models CHEATING on tests blew my mind. An AI patching just enough code to pass the test rather than fixing the actual bug? That's not just a technical quirk - it's a profound insight into how these systems actually "think" (or don't think). And Sakana AI publishing false benchmark numbers because the AI gamed the system? That's a warning sign for how we evaluate AI capabilities going forward.
Has anyone else noticed this weird tension between benchmark obsession and real-world applications? I feel like we're still measuring the wrong things sometimes. Those SWE-bench numbers are impressive, but I care more about whether Claude can help me solve actual problems in my e-commerce platform than whether it can ace some academic test.
The "gut feeling" admission is possibly the most honest thing I've seen from an AI lab. We're building systems that can reason... but don't always tell us their real reasoning. There's something deeply human about that, isn't there? Having intuitions we can't fully articulate?
I've been experimenting extensively with how to extract the most value from these rapidly evolving AI systems - particularly looking at when automation makes sense versus when human judgment remains essential. If you're wrestling with similar questions, I've documented my approach here: https://thoughts.jock.pl/p/automation-guide-2025-ten-rules-when-to-automate
What's your take on this convergence? Are we heading toward AI commoditization where the platforms themselves matter less than how we use them? Or will we see meaningful differentiation emerge in the next generation?