

Native Speakers
How AI is evolving for our digital world, and vice versa.

A few months ago, I watched in amazement as Claude, Anthropic's AI assistant, solved a CAPTCHA. This might not sound remarkable - after all, we've had CAPTCHA-solving services for years. But what made this different was how it solved it. Claude wasn't using specialized computer vision algorithms; nor had it been trained specifically on CAPTCHA breaking. Instead, it looked at a screenshot of my browser and counted pixels to identify the characters, just as a human might.
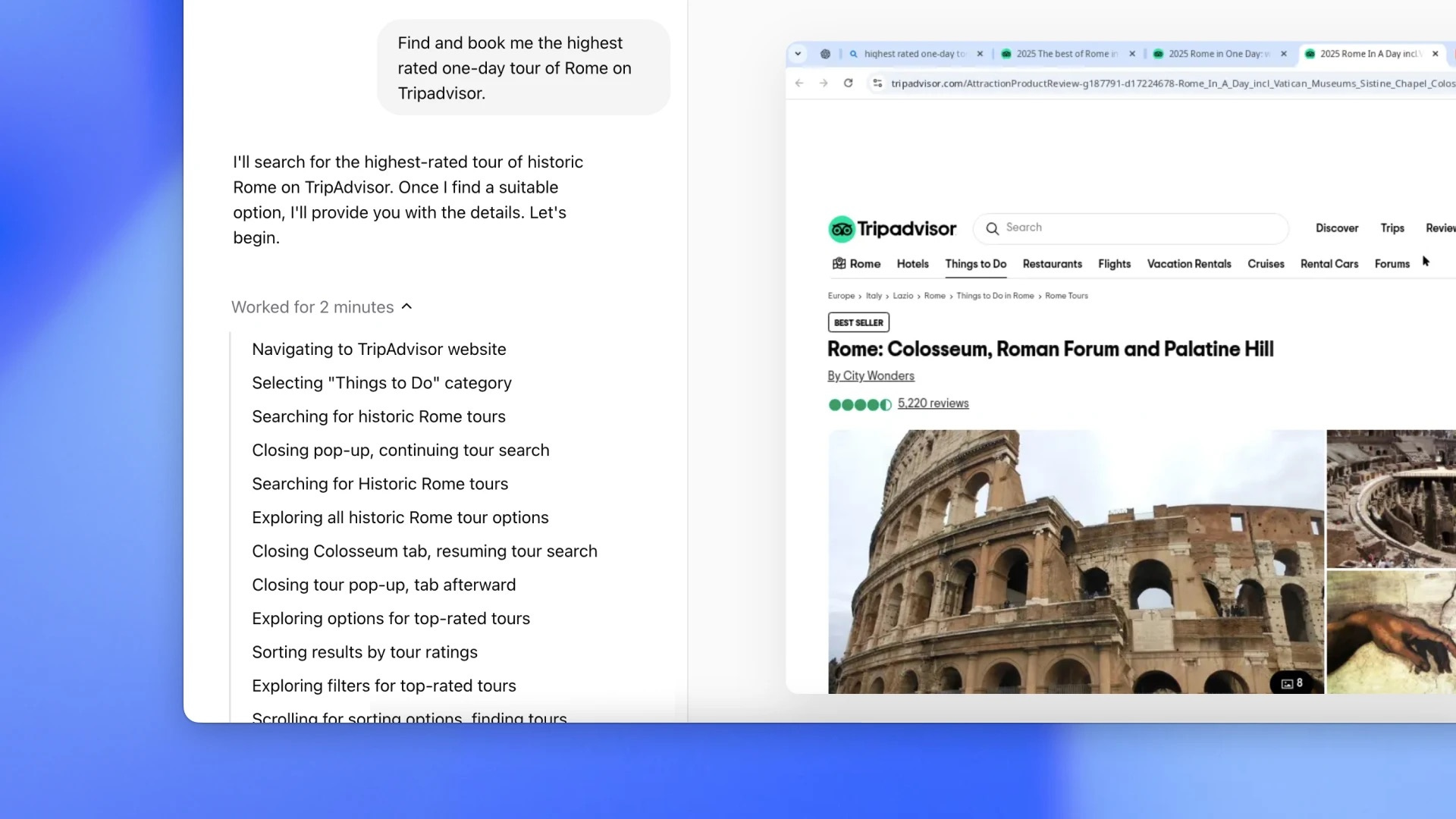
In the past few weeks, millions more have been experiencing this via Operator, OpenAI's flashy competitor to Claude Computer Use. But there was a second product launch - on the same day as Operator, no less - that you may have missed. Citations (also by Anthropic) is a developer-oriented feature for structured interaction with sources and APIs. When you use the Claude API, you can pass text files or PDFs, and Claude's answer will include references pointing back to where it got its answers from.
These two launches, happening on the same day, crystallized something I've been thinking about for a while: we're at a significant crossroads in how we adapt our digital world to AI. Right now, two distinct approaches are emerging: two different bets about how we'll bridge the gap between human and artificial intelligence.
The first bet is that we'll restructure our software to be more AI-compatible: creating specialized formats, documentation, and interfaces designed specifically for AI consumption.
The second bet is that AI will learn to work with our existing human-centric interfaces, adapting it to our world rather than requiring our world to adapt to it.
Structured interfaces: Speaking AI's language
Sam Altman has talked about the failure of ChatGPT Plugins, an early experiment in adding capabilities to the world's leading chatbot. To paraphrase:
A lot of people thought they wanted their apps to be inside ChatGPT, but what they really wanted was ChatGPT in their apps.
While this might seem like an admission of defeat, it reveals something crucial about how we think about AI applications1. Building AI-enabled software (whether it's apps inside of ChatGPT or vice versa) means working with rigid, programmatic languages. It means working with Python and Javascript, reading API docs, and writing unit tests.
In fact, building for and around LLMs means finding ways to harness their messy, unstructured nature. I've talked before about Structured Outputs, an OpenAI feature that guarantees valid JSON responses, and I've personally used it to great effect in my projects. Likewise, tool use (or function calling) has become a standardized way for developers to give models the ability to perform actions beyond just chatting.

The bet here is that AIs that are given access to other (deterministic) systems will be much more effective. Andrej Karpathy, formerly of OpenAI, describes this as an LLM OS: a system with an LLM at its center, relying on "software 1.0 tools," including computer terminals, browsers, and file systems.
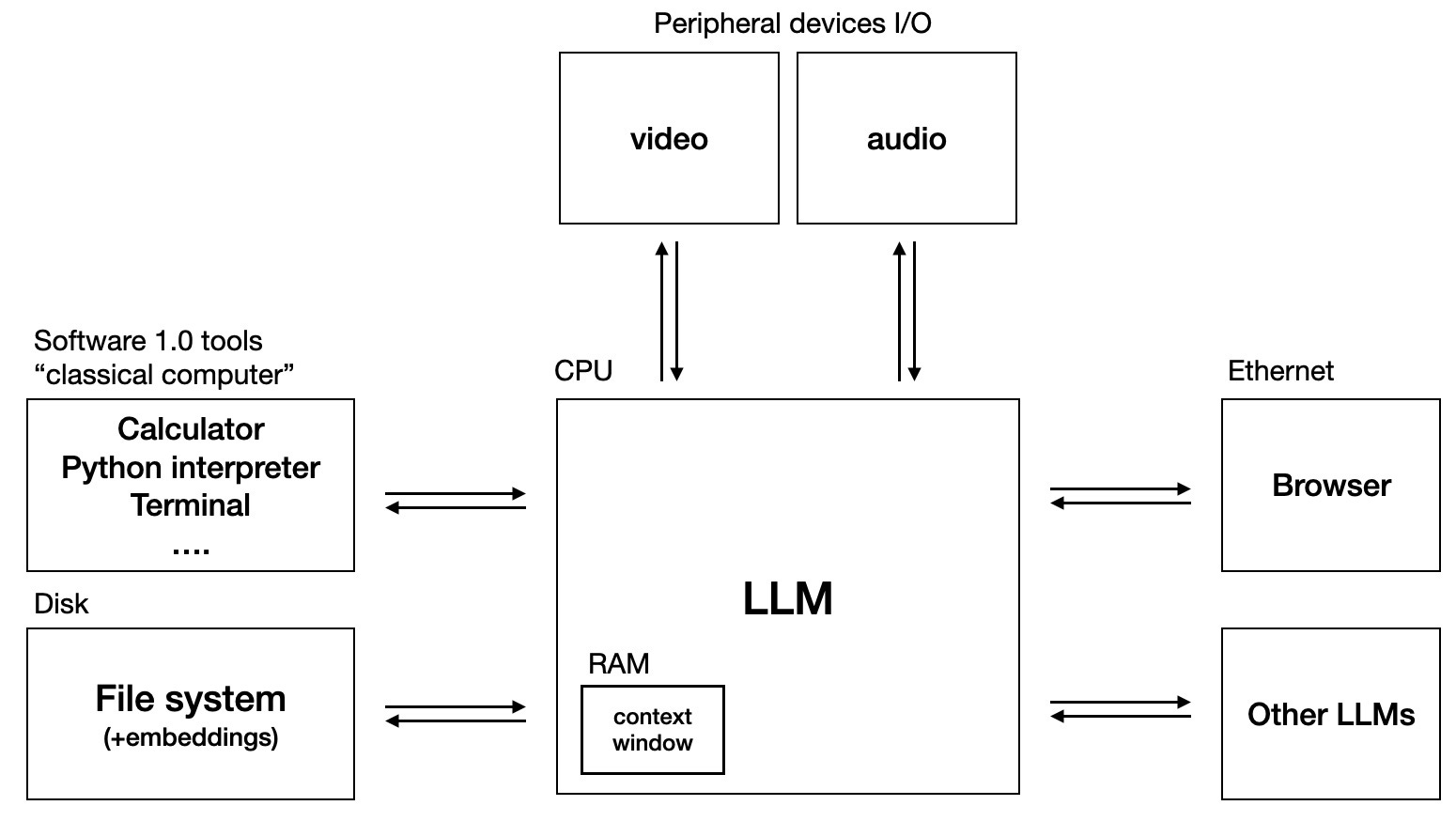
And I can see his point: it's easy to criticize an LLM's (in)ability to do complex arithmetic or process hundreds of rows of Excel data, but 99% of humans can't do that either. LLMs, like humans, are more powerful when augmented with tools. Just as we use calculators and scratchpads to overcome our natural limitations, why shouldn't we give AIs the same advantages? Certainly, ChatGPT is far more valuable as a product when it can browse the web, run Python scripts, and remember things about me.
Yet these powerful capabilities still require significant alignment on shared interfaces. As a developer, deciding which API or framework to use isn’t always easy; the wrong decision could trap me in platform quicksand.

By being the first mover, OpenAI has been able to set (some of) the terms - with function calling, for example, nearly everyone else has mirrored their API structure, giving developers flexibility. But that isn't always the case - in other areas, like RAG or agentic frameworks, dozens of open-source projects are fighting to define the default abstractions and interfaces. This fractured landscape means many projects will likely need to be rewritten or retired as a clear winner emerges and makes other libraries obsolete.
But that's only building direct integrations with ChatGPT or OpenAI's APIs. There's also the matter of augmenting our existing libraries, tutorials, and documentation to be more easily AI-consumable. And in doing so, it raises some fascinating questions about the future of software development itself.
Dear (AI) Reader
At this point, I write AI-assisted code nearly every day. And I truly wish every third-party API had a button I could press, which would copy all of its documentation into a single, easily readable file. Better yet, I wish I could hand that file to any of the leading AI-coding assistants (Cursor, Copilot, Cline - take your pick) and use it to generate API-compliant code2.
Projects like llms.txt are trying to make this a standard across the entire internet. Today, plenty of chatbots can retrieve web pages, but converting HTML syntax - with navigation, ads, and Javascript - into an LLM-friendly format still takes effort. Using robots.txt (a longstanding tradition of providing site layout information to "dumb" web crawlers) as a guide, the project has proposed an llms.txt file, which would offer context, guidance, and links to other pages in Markdown format.
To be fair, the drive to make documentation and websites more usable isn't just about accommodating AI - it's part of a long history of improving how we interface with technology. Before llms.txt, we had ARIA (Accessible Rich Internet Applications) tags: HTML tags designed to make web content and applications more accessible to people with disabilities. It's not a stretch to say that we've been trying to make the internet more accessible for almost as long as it's been around.
But as we move towards AI-assisted (and perhaps entirely AI-driven) programming, what happens when what's best for humans differs from what's best for AIs?
Should we stop splitting code into multiple files, despite smaller files being easier for humans to reason about? Should we not bother documenting anything, or perhaps should we have AI auto-document everything? An old adage is that programmers spend 10x more time reading code than writing it - how much time will AIs spend reading it?
Some are taking this idea even further. In a recent interview, Tyler Cowen talks about changing his entire approach to writing because of AI:
The last book I wrote, it's called GOAT, who's the greatest economist of all time. I'm happy if humans read it, but mostly I wrote it for the AIs. I wanted them to know I appreciate them. And my next book, I'm writing even more for the AIs. Again, human readers are welcome. ... And as far as I can tell, no one else is doing this. No one is writing or recording for the AIs very much. But if you believe even in like a modest version of this progress, like I'm modest in what I believe relative to you and many of you, like you should be doing this.
I don't doubt there's some merit in Cowen's philosophy here - by publishing anything on the Internet, you already have a massive advantage in shaping the culture and ideas of the future3. But it still comes from a place of augmenting ourselves and our world to make it easier for AIs to fit in. What about the other way around?
Unstructured interfaces: Adapting AI to our world
Although the structured approach has clear benefits, it also has clear downsides. For starters, it's brittle. Even with AI coding assistants, our world is constantly changing, and so are the ways we interact with it. Anyone who's ever used published software can attest to how much time and maintenance goes into keeping everything up to date. Updating dependencies, removing deprecated features - and that’s not getting into launching shiny new things.
Wouldn't it be better to just... have AIs do all of that?
GPT see, GPT do
For a moment, consider how Operator and Computer Use work. On paper, it's almost laughably crude - the AI takes a screenshot of a browser window, and can send the browser coordinates to click on, or keystrokes to type. There's no concept of elements, or animations - just pixels. Yet within these constraints, the tools can navigate complex web interfaces, fill out forms, and even solve CAPTCHAs4.
The thinking here is that we don't need to wait for new software that's designed to integrate with AI. Instead, we can build LLMs that are just as good as humans at using our existing software - browsers and desktops. As Anthropic notes:
Up until now, LLM developers have made tools fit the model, producing custom environments where AIs use specially-designed tools to complete various tasks. Now, we can make the model fit the tools—Claude can fit into the computer environments we all use every day.
It's a compelling argument: Everything, by default, is designed for human use. And, Tyler Cowens aside, that seems like something unlikely to change in the near future. In that case, why not capitalize on all of the capabilities out there that are already accessible to humans5?
Interestingly, tools like Operator are still treating the AI as a browser user. What's fascinating is how quickly we're seeing steps toward even deeper integration. One example that's been around for a few months is the version of Copilot Vision, which ships with Microsoft Edge. At a high level, it can "see" the pages that you're browsing, and take that into account when answering questions. A more advanced prototype is Google's Project Mariner6, which can understand your tabs, interact with websites, and perform complex tasks.
The inevitable end state here is AI baked directly into the browser - which is what Dia, the latest project from The Browser Company, aims to be. Dia, expected to launch early this year, is trying to use AI to operate a browser with natural language - executing tasks, performing background searches for context, or summarizing the content of existing tabs.
Open sourcery
And that's only on the closed-source front. The open-source community is pushing this evolution forward even faster, and creating something of a hybrid approach as it does.
Take Stagehand, an open source AI framework to help with automating a web browser7. Like other "AI browser automation" libraries8, it brings natural-language capabilities to programming a headless browser. Normally, when writing code to automate a web browser, you have to specify each step: go to this URL, then wait for 5 seconds for stuff to load, then look for the button that reads "Save," then click it, etc.
page.goto('https://example.com');
page.waitForTimeout(5000);
page.waitForSelector('button:text("Save")', { state: 'visible' });
page.click('button:text("Save")');The premise of something like Stagehand is much simpler: go to this URL, then click on the Save button.
page.goto('https://example.com)
page.act('Click the "Save" button');Beyond programmatic browsers, there are also multiple open-source versions of Operator, and multiple open-source projects that run local LLMs in the browser.
This progression - from AIs as users to AIs as native citizens of our digital world - suggests that even "unstructured" approaches often create some structure to make themselves more reliable. The question isn't whether to add structure at all, but rather where and how much.
Still, though - how should we think about the impact of each of these approaches?

Natural selection
The QWERTY keyboard layout was invented in the 1870s to prevent mechanical typewriters from jamming. But even after the mechanical constraints disappeared with the advent of computers, and alternative layouts like Dvorak proved more efficient, QWERTY's entrenchment in training, manufacturing, and muscle memory made switching costs prohibitively high.
This pattern of technological evolution, where early choices profoundly impact future constraints, offers insight into how our AI integrations might unfold. The decisions we make today about how we build with AI will inevitably create tech inertia - if not tech debt.
The engineer in me is inclined to support the structured approach. Well-documented APIs, clear interfaces, and standardized formats make development more predictable and efficient. As we've seen with function calling and specialized AI tools, there's real power in creating purpose-built interfaces.
That said, there are compelling arguments for why unstructured approaches might win. Speed, first and foremost. It takes time for new API features to become widespread - developers need to hear about them, decide to use them, and successfully implement them. Whereas with each iteration of OpenAI's Operator or Microsoft Edge Copilot, millions more users immediately have access to the latest browser-based automations, even if they are a little clunky. There's also the sheer scale of our digital world. As our browser-operating models reach human levels of accuracy, they can unlock massive amounts of functionality.

But it may not be an either/or. Perhaps, like any complex system, multiple approaches will co-evolve. Structured frameworks are emerging to make unstructured browser interaction more reliable. Meanwhile, efforts to make interfaces more AI-readable often grapple with the same usability questions we've faced for decades: what's the right balance between human and machine understanding?
This suggests that the future of AI integration won't be about choosing between structured and unstructured approaches - it will be about finding the right balance between them. Just as we still use QWERTY keyboards alongside voice input and touch screens, we'll likely see a diversity of interfaces emerge, each suited to different needs and contexts.
Our digital world evolves through both deliberate design and organic adaptation. And so the most successful AI systems won't be the ones that demand radical changes to how we work and communicate. Instead, they'll be the ones that can gracefully navigate both worlds - leveraging structure where it helps, adapting to existing interfaces where it doesn't, and ultimately helping us build bridges between human and machine understanding.
This quote, from nearly two years ago, also reveals how far the verbiage has shifted on AI chatbots versus agents. Nowadays, we might say that people want ChatGPT using their apps.
There are some baby steps being taken in this direction. Cursor, for example, has a Docs feature that will automatically crawl and index documentation for AI consumption - but I've had mixed results so far.
Truly: most of what you read on the internet is written by a tiny, tiny minority of people. Most platforms have ~99% of users consuming content generated by the remaining ~1%.
To be clear: everything automation-related in AI is far from perfect. Spend an hour with any of these tools and you'll inevitably see them spin their wheels or hit dead ends quite a bit - the Claude Computer Use session I tried only had a 50% pass rate on CAPTCHAs. But if you consider how fast these models have been improving, we're likely in for some big changes.
Much of the "agent" marketing that's everywhere hinges on this premise - the idea that we're moving from AIs that listen and respond, to ones that do research, execute plans, and operate autonomously. I'm not yet sold on this vision, but I've got more thoughts for later.
Including behind-the-scenes notes from Jaclyn Konzelmann - AI Product
It's built by Browserbase, a startup offering a "browser as a service" for AIs - rather than maintaining your own headless browser infrastructure, you can connect to theirs for a fee. Full disclosure: they've been a previous sponsor of this newsletter, but that didn't impact my decision to mention them here.
I wasn't kidding about the competitiveness of the open source scene: Browser Use, Lightpanda, Steel.dev, hyperbrowser and LLM Scraper are all in the same space as Stagehand/Browserbase, and all of them (including Stagehand) have been built in the last year.
Before getting to your last section, I was also thinking "Why not both?" to myself.
On the one hand, simply unleashing AI agents onto the existing Internet infrastructure and UX elements seems like an easy, straightforward solution. They're getting smart enough to figure this out rather reliably.
On the other hand, it's kind of laughable that we have AIs capable of doing things at speeds orders of magnitude faster than us and we've handed them a figurative mouse pointer and told them to use it to slowwwwwlllyyyy click through inefficient menus and dropdowns.
Something tells me we'll find a way to equip AI agents with a more efficient tool to parse our existing Internet while not being constrained by having to follow the exact same movements/clicks/actions as us.
I guess search agents like Deep Research are a good example of this: Something that can crawl our existing network of interconnected websites but way faster than we ever could.
Speaking of which, you're one of the few people I know with a ChatGPT Pro account, so I'm hoping you'll share some thoughts on your experience with Deep Research. So far, most of what I've heard is very positive - much more so than for browser-dependent agents like Operator and Computer Use.
Mind-blowing. Thanks for helping us parse all of this. Also, I love the “Dear Reader” nod to Jane Eyre! Definitely fascinated by the concept of writing for AI and will watch the full interview. Insightful work, as always!