

R1 is reasoning for the masses
Why everyone's focused on DeepSeek's new R1 model - and what it means for AI geopolitics.

In the AI landscape, it takes something truly remarkable to unite researchers, developers, and industry watchers in collective amazement. Yet that's exactly what's happening with DeepSeek's latest release of their "reasoning model" family, R1. On Substack alone, you can find quite a few breakdowns of the model already.
I'll admit - I was hesitant to jump on the bandwagon here with my own piece. However, after reading the research papers and initial reports of R1 myself, I wanted to organize my thoughts and see if I couldn't decompose some of the (somewhat justifiable) hype.
But upfront, I wanted to mention a big caveat: much of what we'll discuss relies on benchmarks, which are inherently imperfect metrics. While benchmarks can be gamed and don't always translate to real-world performance, they represent our best tool for making apples-to-apples comparisons in AI capabilities.

Understanding R1 and DeepSeek
R1 belongs to a new category of AI models known as "reasoning models," with OpenAI's o1 being the most well-known example. What makes reasoning models special is their approach to problem-solving. Rather than generating immediate responses, they employ an internal reasoning process that mirrors human trains of thought.

The o1 models, for example, break down problems into steps, try different approaches, and refine their thinking before providing an answer. And while you can't see exactly what they're thinking, you can see a summary of their thought process, and any corrections they make along the way.
Who is DeepSeek?
Behind R1 stands DeepSeek, a Chinese AI company that might be unfamiliar to many in the West. Based in Hangzhou, DeepSeek recently emerged as a significant player in the open-source AI space despite being founded in 2023. The company's backing comes from High-Flyer, a Chinese hedge fund specializing in ML-driven trading strategies.
And R1 isn't DeepSeek’s only impressive achievement. You may remember back in December when it released DeepSeek V31, a chat model hitting benchmarks on par with Claude 3.5 Sonnet and GPT-4o - but at roughly one-tenth of the price. This dual achievement suggests that DeepSeek isn't just getting lucky with one model; it appears to have developed genuine expertise in building frontier LLMs.

Three reasons behind the hype
As far as I can tell, there are three main reasons why everyone is amped up about R1. First, it's performance as an open-weights model. Second, the research paper detailing the training architecture used. And third, the fact that it's a Chinese company releasing everything.
Benchmarks and open weights
The first reason for all the excitement comes down to raw performance and accessibility. R1 reportedly matches o1's performance across several incredibly difficult benchmarks, including the AIME, Codeforces, and SWE-bench Verified.
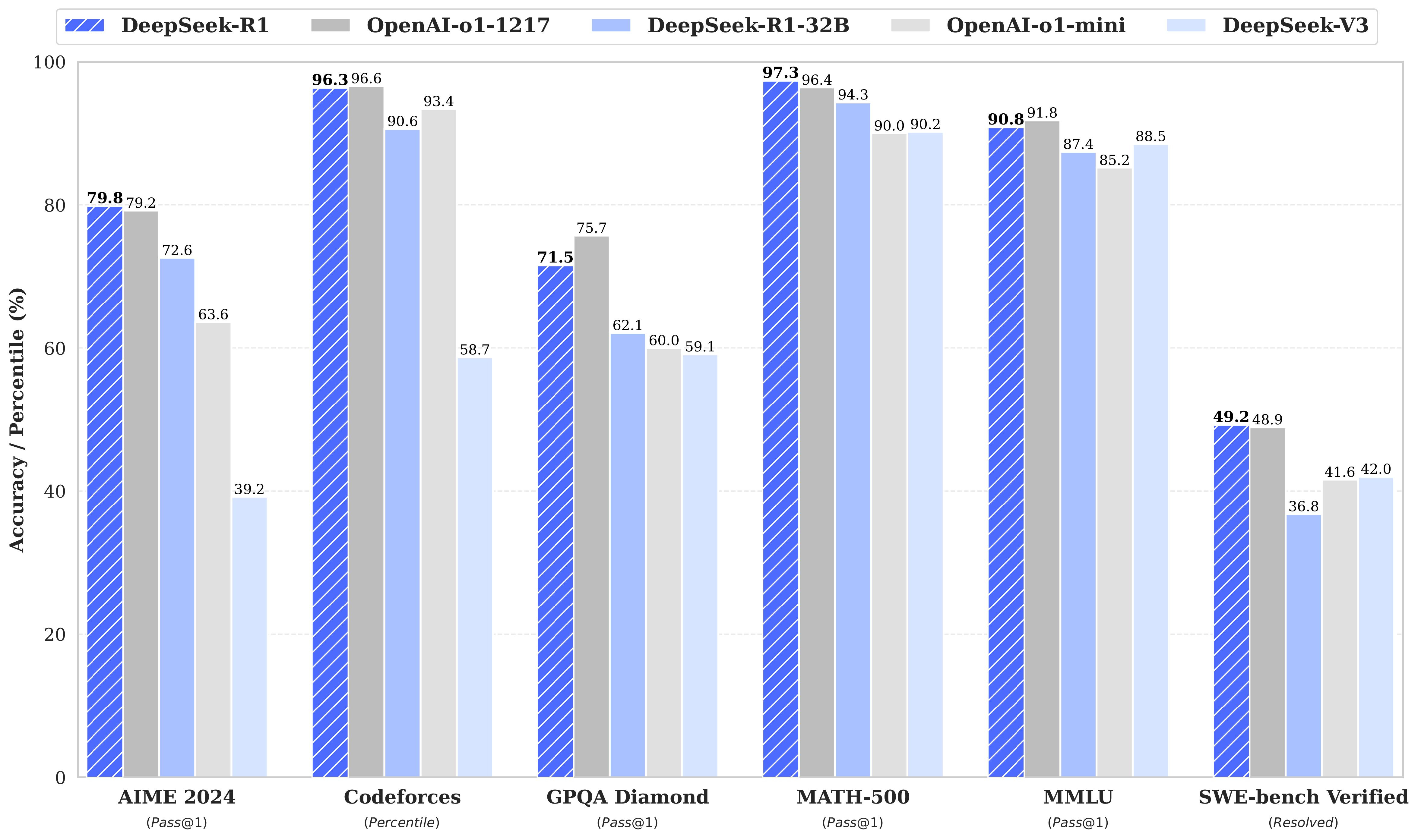
OpenAI has been the undisputed reasoning-model leader with o1 (and their upcoming o3). Before R1, the closest competitor was Gemini 2.0 Flash Thinking Experimental, which performed significantly worse on these benchmarks.
And so not only is R1 getting top marks, it's also open for anyone to download. DeepSeek released the R1 weights (which are massive and unlikely to be usable by consumers) as well as smaller "distilled models" that can be run on consumer-grade hardware. Based on Qwen and Llama, these smaller models are fine-tuned on synthetic data generated by R1. They're not as smart as the flagship LLM, but they will be far cheaper and faster to run.
Almost as an afterthought, there's also an insane cost differential. Right now, on OpenRouter, you can access R1 for $0.55 per million input tokens and $2.19 per million output tokens. Relative to o1, that's 27x cheaper2! I don't know how much margin OpenAI is making on o1, but I'm guessing it's about to make a lot less.
Practically speaking, users can now run models locally that outperform o1-mini, which was considered state-of-the-art in terms of the intelligence/cost tradeoff just four months ago.

Research notes
The second major factor driving excitement around R1 isn't what the model can do, but how it was made. The researchers have provided enormous transparency on their development process, essentially offering a blueprint for other researchers to build their own reasoning models. I’m covering things at a high level here - for a much more technical look, check out yesterday’s post from Interconnects.
The process they've outlined is remarkably straightforward. It starts with reinforcement learning (RL) applied to a regular chat model (specifically, DeepSeek-V3-Base) without any supervised data. In essence, they allowed the model to check its answers and improve based on whether it was right, instead of showing it thousands of examples of correct question/answer pairs to learn from3.
During this initial phase, the researchers discovered some fascinating emergent properties4, including an ability to learn and generalize through RL alone. There was even an "aha moment" - when the model learned to spend more time thinking when faced with complex problems by reevaluating its initial approach - a behavior that arose naturally rather than being explicitly programmed.

However, this first version of R1 (called R1-Zero in the paper), despite its impressive capabilities, still faced challenges. It struggled with readable outputs and tended to mix languages inappropriately. This led to the development of a second training process, with some key additional steps.
Researchers began with a "cold start" using a small amount of high-quality chain-of-thought data5. They then broadened the model's capabilities by incorporating data from various domains, enhancing its ability to handle writing, role-playing, and other general-purpose tasks. It also helped the model stay within a single language, and generate well-structured <thinking> and <answer> tags in its output.
There was also a final stage involving a second round of reinforcement learning, split between answer checking for fact-based areas like math and code, and RLHF-style feedback for more subjective tasks.
This might sound jargon-y and boring, but here’s why it's important: AI researchers have been trying to find the next paradigm for boosting intelligence. Last year, OpenAI appeared to have done it with o1 - but while there were plenty of guesses, nobody knew exactly how.
Now, we have a viable approach, and it’s remarkable how straightforward it is: there was no groundbreaking paradigm, no impossibly-rare training data set. Assuming they're telling the truth, DeepSeek has shown that we can build reasoning models by “just” applying well-known techniques in the right way.

The China angle
The third major factor sending shockwaves through the AI community is geopolitical. The emergence of a Chinese company matching - and in some ways surpassing - proprietary Western models has major implications for the global AI race.
For starters, this is the sort of thing that the Biden administration's GPU regulations were supposed to make extremely difficult. Yet DeepSeek could do this with significantly fewer resources than its Western counterparts - as a spinoff arm of a Chinese hedge fund (and not a particularly large one6), they're operating with a fraction of OpenAI's budget and hardware7.
Moreover, DeepSeek isn't an isolated case. Other Chinese companies are making similarly impressive strides: Alibaba's QwQ and Kimi's k1.5 claim to rival o1's capabilities - something no US company has achieved so far. And like DeepSeek, Kimi is also contributing to the open-source community by publishing detailed research findings. I don't have time to review their k1.5 paper, but it's similarly interesting.
The response has been growing. OpenAI, in particular, appears increasingly concerned about this shift in the competitive landscape. In a recent policy document, it explicitly urged the U.S. government to increase support for domestic AI development, warning about the possibility of Chinese models matching or surpassing American capabilities8.
If I had to guess, the reasoning model race will likely catalyze significant policy changes. Even this week, we saw the White House roll back Biden’s regulations on AI development as well as highlight Project Stargate, a joint venture to invest $500B in American-made AI.
Where we go from here
So what should we make of all this?
For starters, let's be clear about R1's performance. Yes, it does shockingly well on benchmarks. but the jury is still out on whether it's actually "as good" as o1 in terms of real-world usage.
Anecdotally, it still has plenty of limitations - in one instance, the model successfully gaslit itself into believing that "strawberry" only contained two 'r's.

There's also the question of censorship - while US-based models are restricted in the types of explicit or offensive content they can generate, China-based models (even the open-source ones) often refuse to comment on geopolitical issues like Taiwan.

But focusing too much on R1's current limitations might cause us to miss the bigger picture. Even if R1 isn't quite at o1's current level, OpenAI's rapid progress from o1 to o3 showed how quickly these models can improve. We're entering an era where the advantages of being a first mover might not be as durable as previously thought.
I don't think it's hyperbole to say that the AI landscape has evolved in the last few months faster than many anticipated. The release of R1 suggests that breakthrough capabilities in AI might not remain exclusive to a handful of well-resourced companies for long. Yet whether this leads to a more collaborative global AI ecosystem or intensifies the technological arms race between nations remains to be seen.
One thing is for certain: we're going to see a lot more reasoning models in the coming months. The real question isn't whether other labs will build them - it's what we'll do with them once they're here.
o1 is currently priced at $15.00 / 1M input tokens and $60.00 / 1M output tokens.
This approach helps explain why reasoning models excel particularly at math and coding - these are domains where correct answers can be verified programmatically.
As noted in their research paper:
"The findings reveal that RL empowers DeepSeek-R1-Zero to attain robust reasoning capabilities without the need for any supervised fine-tuning data."
"The thinking time of DeepSeek-R1-Zero shows consistent improvement throughout the training process. This improvement is not the result of external adjustments but rather an intrinsic development within the model. DeepSeek-R1-Zero naturally acquires the ability to solve increasingly complex reasoning tasks by leveraging extended test-time computation."
"A particularly intriguing phenomenon observed during the training of DeepSeek-R1-Zero is the occurrence of an “aha moment”. This moment, as illustrated in Table 3, occurs in an intermediate version of the model. During this phase, DeepSeek-R1-Zero learns to allocate more thinking time to a problem by reevaluating its initial approach."
As a reminder, chain-of-thought is a prompting technique where you ask the model to "think step by step" as it answers a problem, and has been shown to meaningfully improve accuracy. if you want to learn more, you can check out my prompt engineering workshop.
High-Flyer has 160 employees and $7B AUM (assets under management), according to Wikipedia. If it were a US hedge fund, it would be number 180 in terms of AUM.
To quote the MCU: "[DeepSeek] was able to build this in a cave! With a box of scraps!"
Even more pointedly, OpenAI's VP of policy specifically called out High-Flyer (DeepSeek’s parent company) as an organization of particular concern in an interview with The Information.
The release of DeepSeek's R1 model is significant, combined with the transparent research and the fact that it is under the permissive MIT license, allowing commercial use. This shifts power dynamics.
There are two messages:
1. First towards OpenAI: We can achieve the same results with at least one order of magnitude less resources.
2. Second towards Meta: We can totally out-opensource you.
How are companies who have invested vastly more resources, yet do not seem to possess any significant competitive advantage, supposed to receive a return on their initial investment? It appears highly unlikely.
The $500 billion in infrastructure could be perceived as a bailout to the investors of OpenAI, who are frankly in a tight spot.
According to a colleague the model is “talking about Taiwan, no problem”