

Lies, damned lies, and benchmarks
Examining some of the downsides of how we evaluate LLMs.

This week, Google Bard (now powered by Gemini Pro) hit second place in the Chatbot Arena on Hugging Face. If you don't know what that sentence means, don't worry - we'll get to it.
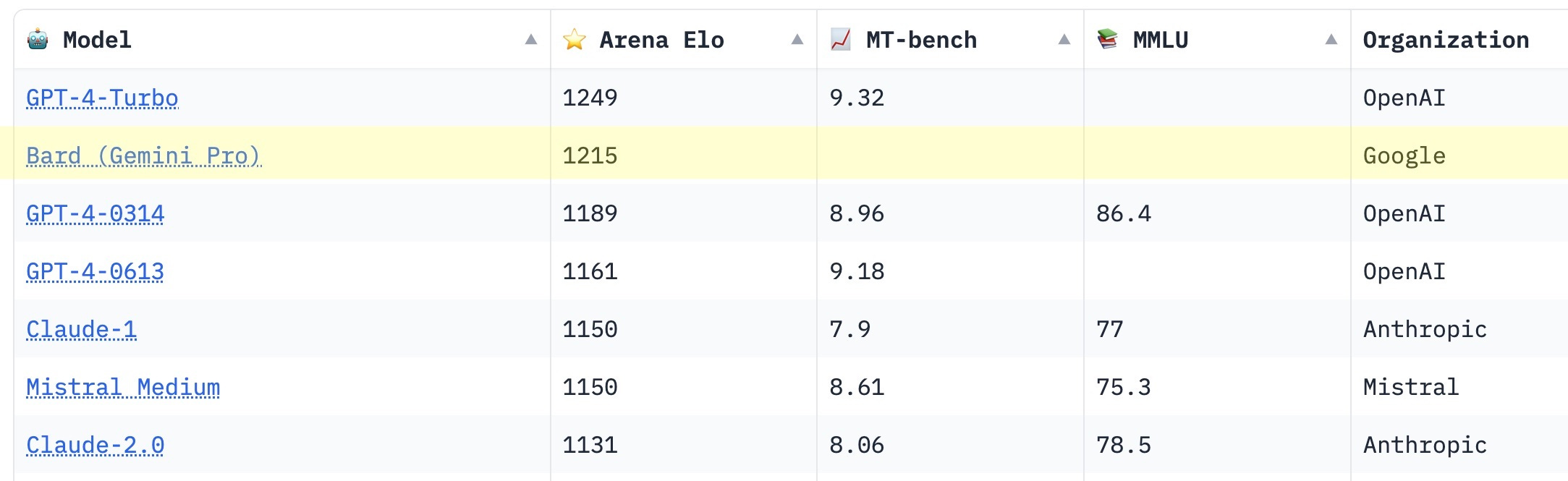
But it often seems like every month (sometimes every week) there's a new model, with new high scores, bringing new posts about how it's about to change everything. "New high scores" can mean various things - often it means academic benchmarks, but sometimes it's informal leaderboards or other kinds of evals.
And while benchmarks (and leaderboards) are useful tools, they are but a small facet when it comes to evaluating large language models. Often, they're not the best indicators of real-world utility - and I want to dig into why (and what other approaches exist).
If you want to dive deeper into some of the most common benchmarks, Why Try AI? has a great roundup of twenty-one of the top benchmarks, with sample problems from each.
The problem(s) with benchmarks
When training a new LLM, it's essential to know how good (or not) your model is - which is where benchmarks come in. They allow us to compare models across the exact same set of problems in language understanding, code generation, math, and more. Without a unifying system, we’d constantly compare apples to oranges with each new LLM release.
Yet depending on your use case, there are several reasons why LLM benchmarks don't paint the whole picture.1
Narrow scope. Typically, papers evaluate LLMs in controlled environments with narrow criteria. As a result, it's usually not reflective of the diverse and complex data encountered in real-world applications. As LLMs have been released into the wild, we've had to contend with harmfulness, fairness, and helpfulness - qualities not measured in the most popular benchmarks2.
Overfitting. Similarly, many benchmarks are designed to test a specific task or use case. That's generally a good thing! But often, being "the best" at one type of task is mutually exclusive with being "pretty good" at handling new, unforeseen scenarios. And as we continue to build toward general-purpose models and agents, successfully navigating unknown situations becomes much more critical.
Contamination. As the size and scale of LLMs have grown, we've run into a new problem - contamination. While small, specific models may be able to curate and vet their data sources, the reality is that state-of-the-art LLMs are being trained on datasets too large for any one person or team to comprehend. As a result, there is a growing risk of dataset contamination - where the LLMs perform well because they've already seen the answers to the test!
Currently, the oldest of the popular benchmarks are from around 2018/2019, which is old enough to have been accidentally included in GPT-4's training. But as more articles and papers share example problems from existing benchmarks, the problem will get worse - unless we keep creating new, never-before-seen problems.3
Reproducibility. With the advent of RLHF, prompting has come to play a much more significant role in LLM performance. And while the creators of a model are probably best suited to generate the best results via prompts, they likely aren't experts at other people's models - meaning the comparison could be flawed due to different prompting techniques.
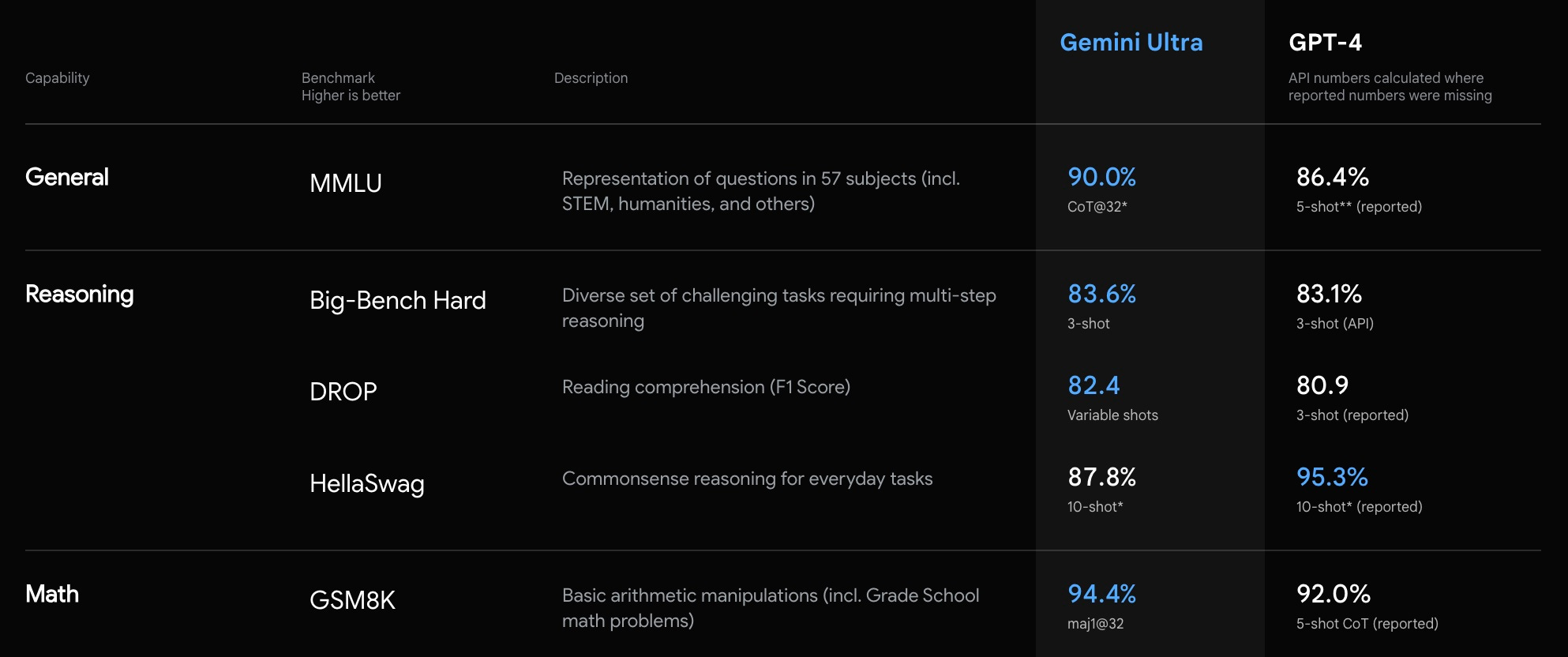
We saw this with the release of Google Gemini - the model was compared against GPT-4, but slightly different prompting techniques were used. And while it may be close, it leaves room for debate when it's not a true apples to apples comparison.
Lack of multi-modal capabilities. There's also a big gap when it comes to benchmarking multi-modal models. Many benchmarks are usually designed to test language understanding or image recognition - not both. That's a big miss - we've already seen how GPT-4 with vision can perform significantly better on some tests and exams.
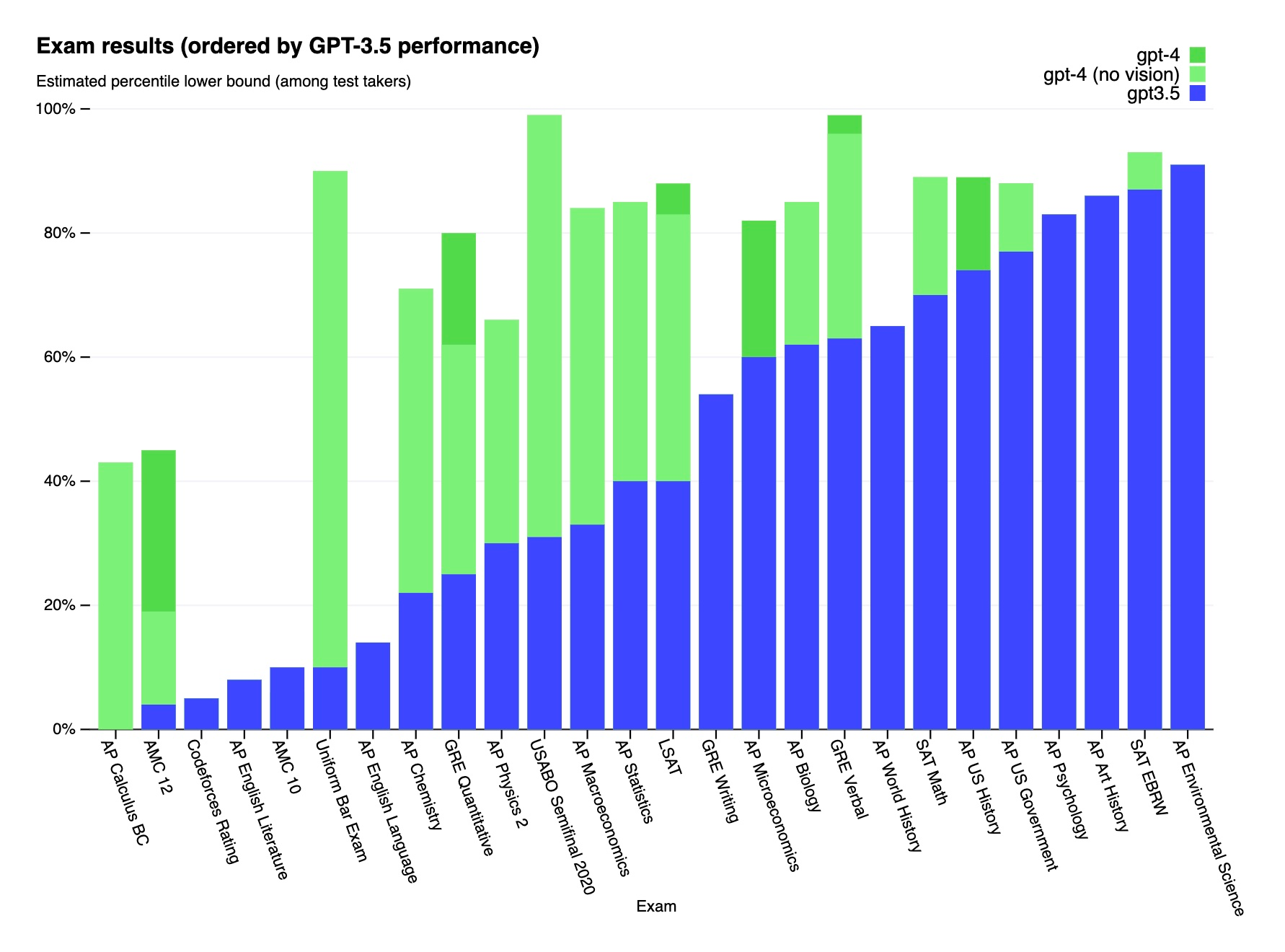
Looking at this list, the biggest issue seems to be that tests to measure LLMs have a hard time holding up to actual day-to-day usage. This kind of makes sense - encapsulating all of the nuance and complexity of real-world LLM usage is hard! It's important to remember that up until very recently, LLMs were nowhere near ready for consumer (or even developer) consumption. They were the domain of researchers and academics, so they mostly needed to worry about research and academic use cases.
Beyond benchmarks
What, then, should we be using to measure our models? There are some alternatives, mainly in the form of leaderboards and evals.
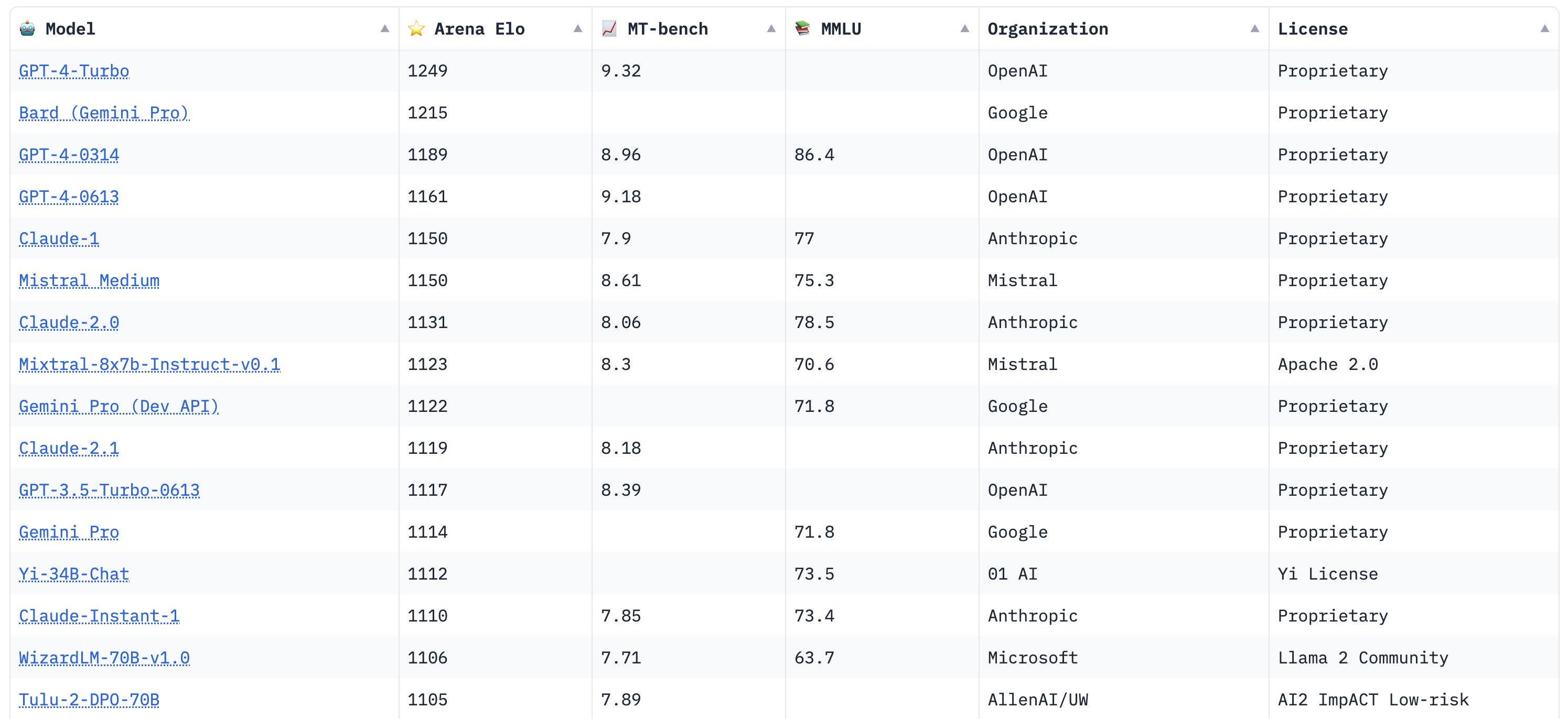
Leaderboards are platforms that track and rank LLMs based on their performance. They're a way of looking at multiple metrics simultaneously and are inherently meant to compare different models. Some, like the Open LLM Leaderboard, use a handful of existing benchmarks to create a ranking. Otherwise, like the LMSYS Chatbot Arena, use crowdsourced data to compare LLMs in a chatbot setting. These leaderboards are often hosted on Hugging Face - a key player in the open-source AI movement.
The Chatbot Area is particularly interesting because users interact with two anonymous chat models at once - and choose the one they prefer4. That lets us compare models head-to-head in real-world scenarios, and the leaderboard represents a more practical "Elo score" for chatbots.
This, by the way, is the leaderboard that Google Bard shot to the top of last week - meaning actual people prefer Google Bard to all but the latest GPT-4 Turbo model in head-to-head comparisons. It’s quite a PR win for Google!
Besides leaderboards, there are also evaluations, or "evals." These tests or procedures are used to check LLM performance in various scenarios. OpenAI maintains a repository of public evals, to which anyone can contribute. Evals can involve a range of metrics to track multiple things at once and are often used to measure a model's performance over time.
Evals can be thought of as the "unit test" equivalent for LLMs - they're less concerned with general understanding and more focused on actual performance within a system. They can also be tailored to the needs of a specific product or company.
But benchmarks, leaderboards, and evals each have their role in the AI ecosystem - I'm not suggesting we should throw any of them out entirely. Rather, it's important to know their strengths and weaknesses - and what a "new high score" actually means.
Of course, if we run out of good exam questions, we can always use other LLMs to come up with new ones. But the jury is still out on just how good synthetic data is for training (and evaluating) language models.
There are some additional rules - for example, the vote is thrown out if that chatbot reveals its identity.
My LinkedIn feed is now full of some arcane and obscure open source model I'll likely never hear about again. Since when did leaderboards become a thing engineers actually cared about?
Great clarification regarding the Chatbot Arena. It pops up in my feed regularly (the last time with the Gemini Pro news), but I never tried digging further, so I never realised it measures interactions with real humans in a "non-lab" scenario. Looking more closely, I can see that Bard "only" has 3K votes compared to GPT-4's dozens of thousands (for every measured version). So the confidence interval is quite different and we may potentially see Bard slip as more votes roll in.
I've now heard from a few people about Bard being much improved lately. So I went and tried it yesterday and didn't quite have an "Aha!" moment of seeing major leaps forward. Then again, I rarely use Bard, so my point of reference isn't that great. (ChatGPT Plus with GPT-4 Turbo did give me better Mermaid code when I compared its output with Bard.)
I appreciate the mention, by the way!