

GPT-4o and the end of diffusion's dominance
The technical evolution reshaping AI's creative capabilities.

What a week for AI image generation.
The past 48 hours have seen two major image models released within barely a day of each other. Reve, a new Palo Alto-based startup, boldly claimed to have built "the best image model in the world." And for a moment, they seemed poised to dominate the AI news cycle.
At least until OpenAI announced GPT-4o's native image generation. And while I’m tempted to dive into both, I actually think it’s worth focusing more on GPT-4o, for reasons I’ll get into below.

Show don’t tell
It’s perhaps easiest if we look at some of the images coming out of GPT-4o. DALL-E, despite its impressive capabilities, consistently produced images with telltale AI artifacts - cartoonish features, illustration-style aesthetics, and the notorious inability to render text correctly. GPT-4o, in contrast, shows remarkable improvements.
Realistic Images



Character Consistency



Detailed Instructions

Prompt:
A square image containing a 4 row by 4 column grid containing 16 objects on a white background. Go from left to right, top to bottom. Here's the list:
1. a blue star
2. red triangle
3. green square
4. pink circle
5. orange hourglass
6. purple infinity sign
7. black and white polka dot bowtie
8. tiedye "42"
9. an orange cat wearing a black baseball cap
10. a map with a treasure chest
11. a pair of googly eyes
12. a thumbs up emoji
13. a pair of scissors
14. a blue and white giraffe
15. the word "OpenAI" written in cursive
16. a rainbow-colored lightning bolt
World Knowledge



Over on Reddit, users are rejoicing over the model's ability to generate "a wine glass filled to the brim" - an image generation challenge similar to "count the r's in strawberry" that most AI images have a very hard time with1.

Making a splash
In any other week, Reve's launch would have dominated AI headlines. Their model has topped head-to-head leaderboards in image generation quality, representing a significant achievement for a startup.
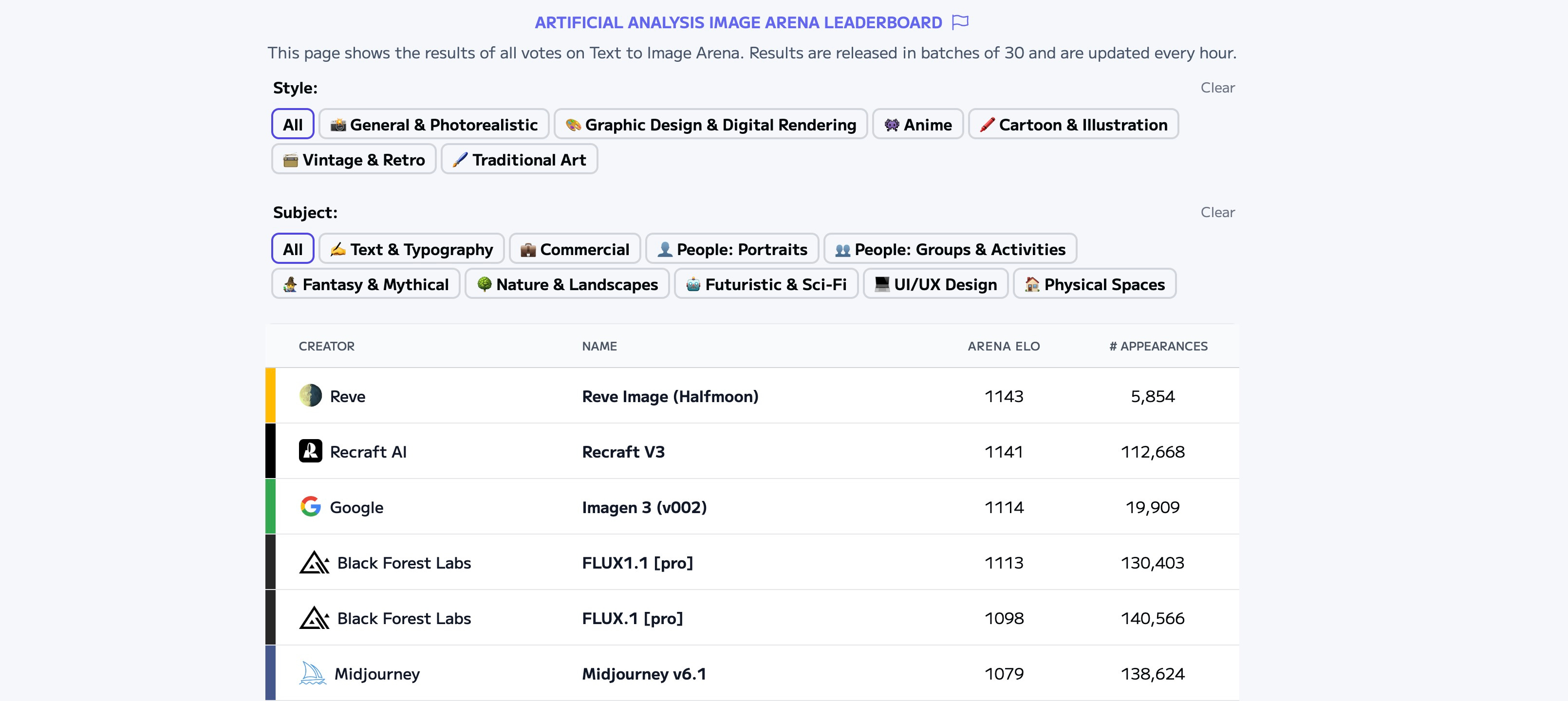
Yet within hours, they are perhaps already overshadowed by GPT-4o's capabilities.
It's really remarkable how splashy OpenAI's releases continue to be, even when there exists competition in the space. Google, for example, rolled out some very compelling image editing features to its Gemini chatbot just two weeks ago. Their examples showed the ability to use natural language to make image edits: "add a hat to the dog" which I hadn't seen a model do before (if you want to see more examples, Why Try AI did a quick write-up when it launched).
And yet - I suspect OpenAI's release will make it into more hands, faster, because of their ability to build compelling products. There's a growing importance in how AI capabilities are packaged, marketed, and integrated into compelling product experiences. Notebook LM was a striking example of this, but even as recently as last week we saw openai.fm, a quirky app that gives users a window into their new voice generation technology.
This is doubly important for competitors like Reve, which are releasing state-of-the-art models via a playground site but not within a broader chat experience. As much as it pains me to say it, companies that release top-tier models without comparable attention to the user experience increasingly risk being overlooked, regardless of their technical merits.
Yes, there's still the chance that your model can hit the top of leaderboards and go viral on social media, but that's a difficult distribution strategy to bank on. And it also makes it less appealing to write about - while I’m happy playing with something like Reve, I’m not sure whether publishing it will be as interesting to my readers, given the lack of a compelling product experience.
Taken together, it's yet another piece of evidence pointing toward our AI future being dominated by companies with deep pockets.

Disrupting diffusion
One of the most interesting aspects (to me, at least) of the new capabilities is the fact that they're not a diffusion model. Every leading image generation model, from Midjourney to DALL-E to Black Forest Labs, is using a diffusion approach. It's a bit technical, but I've previously done a deep dive of how these models work:
Diffusion models are machine learning models with two steps: breaking data down and building data up. Given a piece of data, say, the pixels in an image, the model first runs a "forward process." This process adds "noise" to the image until it's unrecognizable - think TV static.
Then, we pass the noisy image, along with a description, to a "reverse process." This process then learns, through trial and error, how to turn a static image back into something resembling the original image. After doing this across billions of images and descriptions, it can generate any image from just a description.

Instead, OpenAI is leveraging the fact that GPT-4o is a natively multimodal model (meaning text/images/audio goes in, and text/images/audio comes out) to find a different path forward. We saw the first examples of this with Advanced Voice Mode, which was a far richer voice experience than most models that had come before - you can ask it to speak faster, or in an accent, or at a lower volume, and it can understand and comply with those instructions2.
GPT-4o is generating images one visual token (i.e. pixel) at a time(side note: can’t wait to see what “reasoning for image models looks like”), allowing it to think about what’s already been generated and what should come next. From an architecture perspective alone, it’s a fascinating model.
To be fair, it's worth noting that OpenAI has showcased the "best of 3" of "best of 8" outputs in its launch post, meaning there's still a bit of a slot-machine effect at play here. And the architecture, despite its breakthroughs, still has clear downsides:
Hallucinations
Spatial awareness
Multilingual text
Following more than a couple dozen instructions
Precisely editing images
It’s slow. Like, really slow.
What’s next for image gen
Looking at GPT-4o's image generation, I'm left with some big questions about where image generation is headed.
For starters, I wonder whether competitors like Midjourney and Black Forest Labs pivot away from diffusion models. Given OpenAI's massive head start on multimodality, not to mention the massive resource requirements for adding world knowledge and language, I have a hard time seeing how that's possible to do efficiently3.
Besides, if they did spend those resources, there's already a large ecosystem built around the existing architectures. Platforms like Civitai exist to host and share open-source "LoRAs," quick and dirty style adjustments for image models (think swapping out drill bits on an electric drill). Lots of fine-tuning infrastructure is based around being able to customize a diffusion architecture.
And of course, if ChatGPT can handle all of these things natively, on top of writing emails and code, I have to imagine "image-only" competitors like Midjourney get squeezed in the long run (to say nothing of the legions of AI selfie/headshot/anime apps). There will always be a faction of open-source users, but Midjourney is neither open-source nor developer-oriented - they've resisted having an API for years.
While diffusion-based image generation isn't obsolete overnight, its days as the dominant approach may be numbered. As computational resources continue to grow and multimodal architectures mature, we're likely entering a new era where the boundaries between different modalities - text, image, audio - continue to blur into increasingly unified and powerful systems.
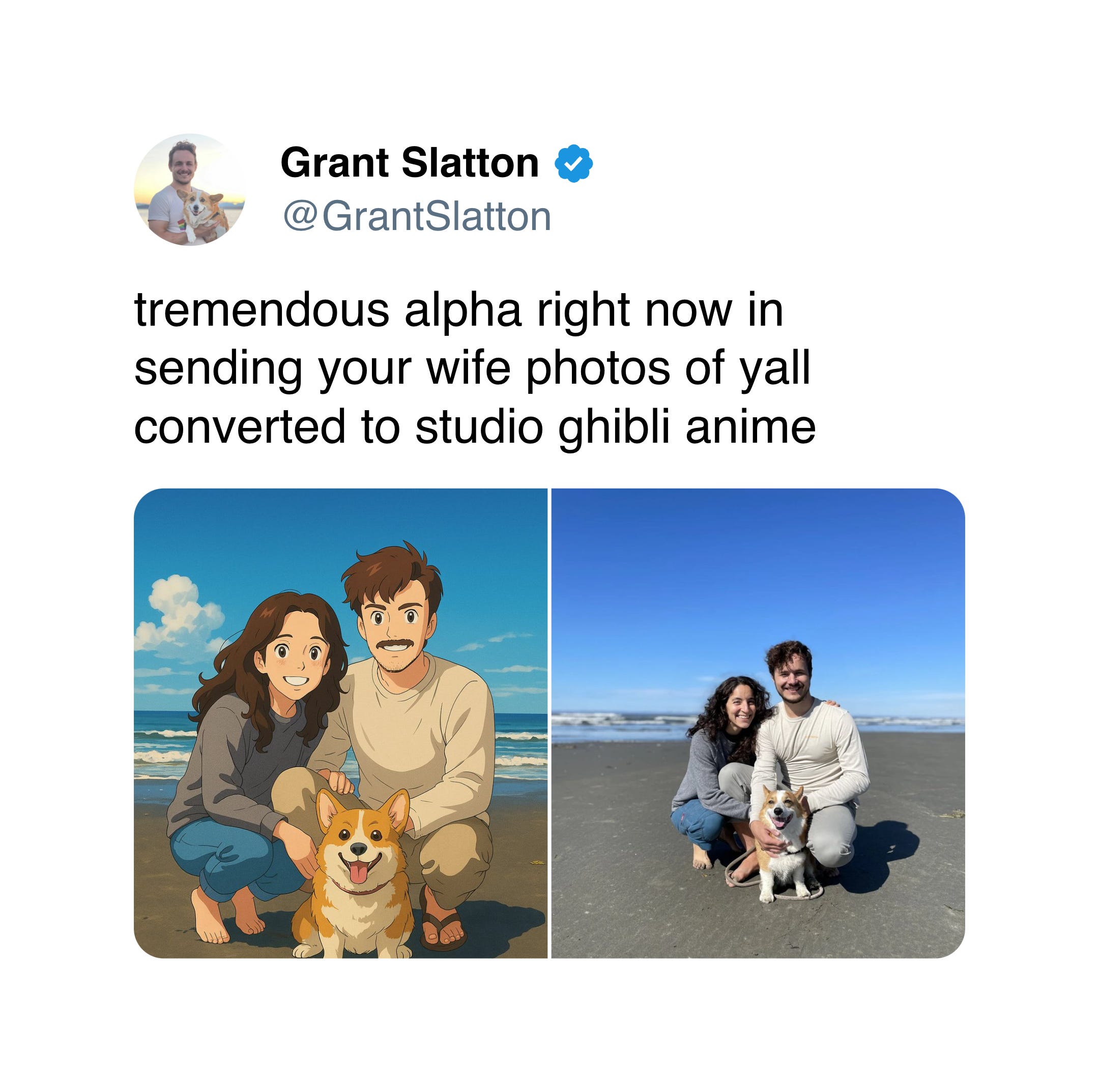
In the meantime, please enjoy the Studio Ghiblification of the internet:
This is because most AI image generators learn from a training set, and it’s incredibly rare to see a photo of a wine glass filled all the way to the brim. It's not practical or aesthetically pleasing, so they've never learned what that looks like.
There’s also an open question here around why it took so long for this capability to be released. It was present in the original demos of GPT-4o around 10 months ago, but took until now to be made available publicly. My guess is some combination of: post-training tweaks, safety and alignment work, and GPU capacity.
The one big argument against this shift is that 4o’s image generation is nearly unusable as a standalone product. Despite the higher quality, it can take tens of seconds to create an image, something AI consumers will likely have a hard time swallowing. But because 4o is generating images via tokens, it means that any improvements to inference as a whole will speed up its image generating capabilities.
Ha, looks like we ended up tackling the same issue (and the same Reve vs. GPT-4o take) from slightly different perspectives today! We even reach the same broad conclusions. Mine's here: https://www.whytryai.com/p/openai-4o-native-image-generation
I've been playing around with 4o image generation and am honestly blown away. The level of detail it can pick up in an uploaded image and then re-render in any style is incredible.
Also, thanks for the shoutout to my Gemini 2.0 take!