

How AI image generators work
Examining how one in particular (Midjourney) works and what it's capable of.

It wasn't too long ago that we all believed art was one of the few areas safe from automation. After all, how could you distill visual creativity into ones and zeros? Then came the image-generating AI.



Let's dive into Midjourney, one of the most widely used of these new tools.
We'll look at how it works, what its limitations are, and how its different from competitors (mainly Stable Diffusion and DALL-E). In a follow-up post, learn how it's already proving valuable to businesses, and how you can get started.
What is Midjourney?
Midjourney is what's known as a diffusion model, a type of machine learning model. It takes a piece of text as the prompt, then generates corresponding images. Each image is unique, though re-using the same prompt will lead to similar results.

Midjourney is more "artistic" than other models. People often look more like portraits than photographs, but it's also easy to create gorgeous illustrations.
Midjourney is only accessible through a web interface (specifically Discord), unlike some other teams that have open-sourced their code. While there is a free trial, heavy usage will require purchasing credits from the company.
Technical aside: What are diffusion models?
Diffusion models are machine learning models with two steps: breaking data down and building data up. Given a piece of data, say, the pixels in an image, the model first runs a "forward process." This process adds "noise" to the image until it's unrecognizable - think TV static.
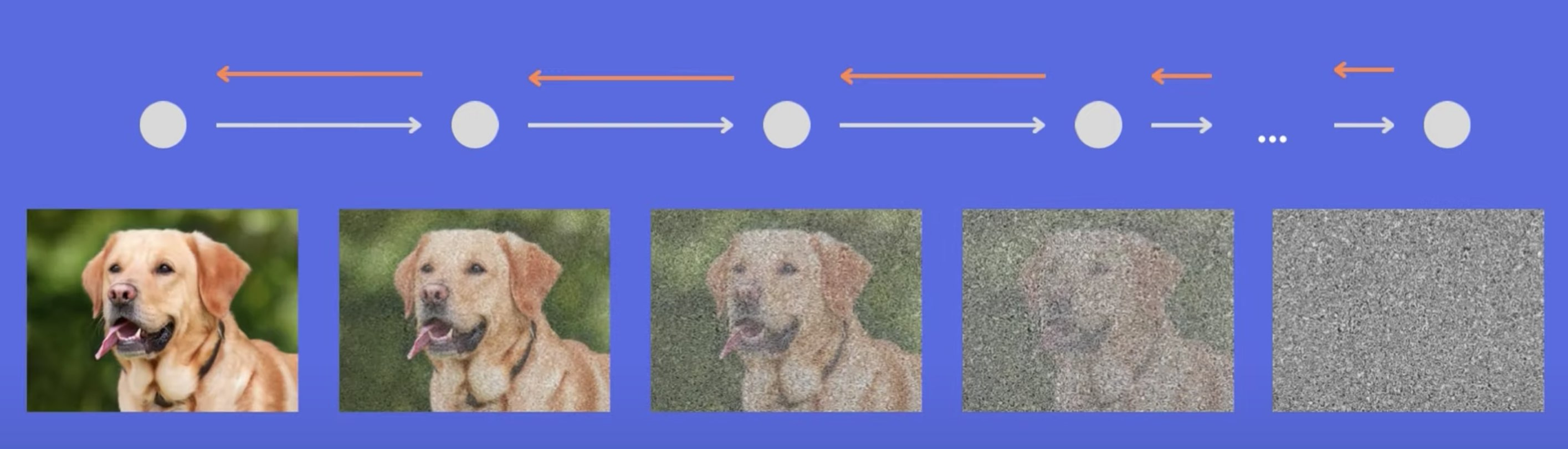
Then, we pass the noisy image, along with a description, to a "reverse process." This process then learns, through trial and error, how to turn a static image back into something resembling the original image. After doing this across billions of images and descriptions, it can generate any image from just a description.

Those billions of images and descriptions are currently a contentious issue. Stable Diffusion and Midjourney have admitted to using images and text scraped from the internet, without explicit consent. This has led to more than one intellectual property lawsuit.
If this all sounds strange, it kind of is! The concept of diffusion models have only been around since 2015, and we're still figuring out what they're capable of and how to improve them. Midjourney, Stable Diffusion and DALL-E were all released in 2022, and have already been making rapid improvements. And although we're focused on images here, there's already research applying diffusion models to audio and video.
What are diffusion models capable of?

Imitating existing styles. Midjourney is great at mimicking the styles of famous artists. It’s an excellent way to quickly get a specific aesthetic, or generate the same image across multiple styles. With tools like Stable Diffusion, you can also do things like turn sketches into fully-finished paintings.

Modifying parts of an image. If you’ve used the latest version of Google Photos, you’ve probably seen this feature, otherwise known as inpainting. You can select a specific area of an image, then describe how you want it to change. The opposite technique, known as outpainting, expands an image by filling in extra space.

Blending two images. One of the coolest things I’ve seen is blending two images together. It’s difficult to know exactly what you’re going to get, but the creative choices are endless.

Upscaling an image. Midjourney by default will generate low-resolution images, then upscale them. But you can use diffusion models to upscale existing images. This process is cheating a bit - it’s inventing pixels to fill in the gaps as the image gets bigger. In the example above, note how details on the helmet, belt, and feet changed when it was upscaled.
3D and video output. Right now, the most compelling outputs are happening with images. But there are companies working on creating 3D models, rendering, and video using diffusion models.
What are the limitations of diffusion models?
As mind-blowing as these results are, there are still some quirks to consider.

Hands. This is a meme by now, but diffusion models are notoriously bad at generating accurate hands. In fact, a good way to tell (for now) if art is AI-generated is to look at the hands (or lack thereof).

Multiple faces. While diffusion models are great at details of faces, they have a tendency to want to generate multiple faces in a single image. Additionally, if you're intentionally making an image with multiple faces, there's a tendency for them to look strange.

Text. One of the hardest things to do with diffusion models is generating text. That's because the models don't actually "understand" language, so to them, letters are just slightly-different looking pixels. While it's possible to create prompts that add the correct text, it's usually easier to add it with other software.
Nuanced prompts. For those without an art background, it can be difficult to know the right words to describe the picture in their head. Complex scenes can take a lot of prompt engineering to get the right image.
How are businesses using Midjourney today?
Stay tuned for part 2: practical use cases for Midjourney, and how to get started.