

Gemini 3 and Google’s Antigravity Trajectory
Google's simultaneous releases in models, research, and developer tools.

There’s been much ado about Gemini 3, and yesterday Google finally unveiled its latest model. As you might expect, we’re already seeing breathless hype and flashy demos. The trendiest things from Gemini 3 so far seem to be very impressive one-shot coding examples, but as always, we’ll find out over time where consensus lands. Let’s dig in.

Gemini 3 Pro
Technically only Gemini 3 Pro is being released - today Gemini 3 is a single model, but tomorrow it’ll be a model family. The Gemini 2.5 family consisted of Pro, Flash, and Flash-lite, and I’m expecting a similar lineup for Gemini 3. Google is also hinting at new models “with new features, across different modalities,” so stay tuned.
But these days, it makes sense to lead a launch with the biggest model size if you can. It’s going to take up all of the attention, especially if it’s got good benchmarks.
Speaking of benchmarks
Of course, the usual benchmark disclaimers apply - they’re often gamed, they don’t capture everything that matters, and real-world performance is what counts. But there are a few interesting data points worth highlighting1.
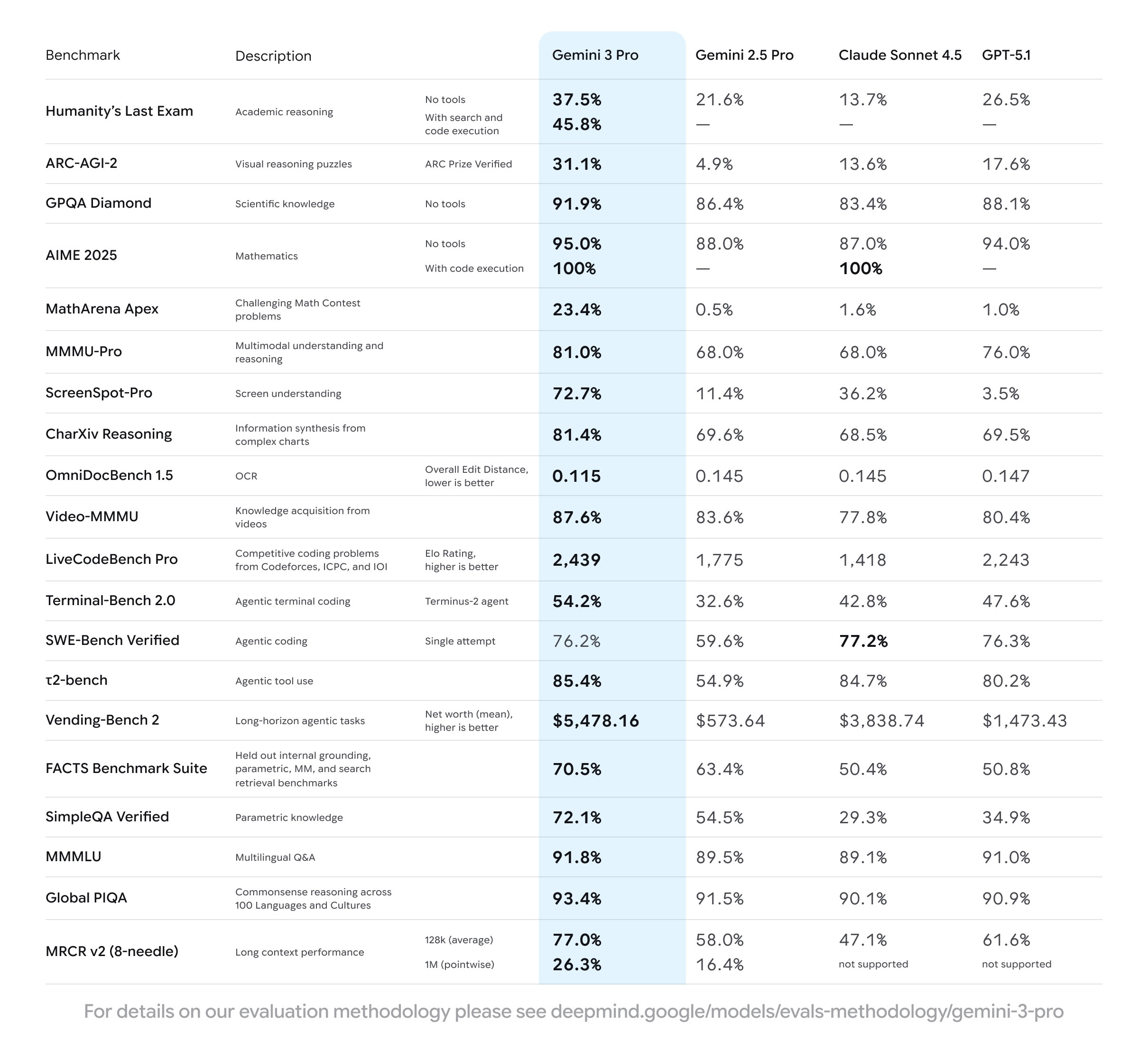
Gemini 3 Pro scored an impressive 31.1% on ARC-AGI-2, a benchmark that’s intentionally designed to be very difficult for LLMs, and a nearly 2x improvement over GPT-5.1. Gemini with “Deep Think” - a compute-heavy system that spawns multiple agents in parallel - scored an even higher 45.1%. For context, this benchmark has been notoriously resistant to being solved by throwing more compute at the problem, so these numbers are genuinely notable.
Sonnet 4.5 retains its lead as the “best” coding model according to SWE-bench Verified, but GPT-5.1 and Gemini 3 Pro are now quite close. We’re talking about differences of a few percentage points, which means we’re entering the territory where model choice matters less than the tooling around it - more on this later.
Perhaps the best comparison, though, is Gemini with itself - from 2.5 Pro to 3 Pro. It’s remarkable how much better the model has improved, especially given that the 2.5 Pro is already widely considered a strong model!
Again, I don’t want to get caught up in the benchmarks here. It’s certainly possible to game them, and there’s undoubtedly enormous pressure to do so. That said, if Google’s benchmarks are any indication of Gemini 3’s overall improvements over 2.5, then they really cooked with this one.
Beyond benchmarks
But Google isn’t just trying to win on numbers. They’re also trying to showcase Gemini’s broad capabilities across various surfaces and modalities.
One aspect of this is multimodal reasoning, which incorporates images and videos. Gemini 3 appears to excel in spatial reasoning, including notoriously challenging tasks such as generating an accurate clock face. The model can also ingest and reason over long videos, such as lectures, tutorials, and sports footage. This is table stakes for frontier models now, but Gemini 3’s scores on Video-MMMU suggest it’s very strong at it. The ability to throw a 2-hour lecture at a model and have it extract the key concepts, or to analyze an entire basketball game for strategic insights, is the kind of thing that feels like magic (until it becomes mundane).
A second aspect is UI design - including generative UI. With every major release, there’s always a wave of shiny demos highlighting the best use cases, particularly around coding beautiful, custom websites and interfaces. Often, these tend to be less impactful as time goes on - they’re great for landing pages, but don’t hold up over time when you need to maintain or iterate on them. But Gemini 3 has a couple of unique things going for it.
For starters, there’s Replit Design, a new feature powered by Gemini 3 Pro. The examples I’ve seen have been quite impressive (though I admit I haven’t tried using LLMs to generate UIs in some time). But it’s not just about one-off designs - the fact that it’s connected to Replit means you can quickly deploy the front-ends without having to worry about pesky backend steps.
However, one of the most exciting aspects of the entire Gemini 3 launch (IMO) is another Google research paper about generative UI. Generative UI is the idea of having the AI dynamically create a custom presentation - layout, format, UX, and all - for content. Since GPT-4’s breakout moment, tons of developers and startups have been experimenting with this. As far as I’ve seen, none have really nailed it. Most examples I’ve seen quickly go off the rails with complexity or are hopelessly irrelevant, generating elaborate interfaces for simple queries or completely misunderstanding what presentation format makes sense.
But Google’s are... actually reasonable. There’s a repo with a couple dozen examples here, including some delightful results from stupidly simple queries like “dragonfruit” or “green things.”

Look, I’m sure that they’re certainly cherry-picked examples, and we’ll see a bunch of strange or broken dynamic UIs in the wild. But the fact that Google is bringing them to AI mode, and attempting them at scale, implies that they’re at least reasonably confident that they can do a good job here.
And, of course, there’s the fact that launches which relied on cherry-picked examples a year or two ago are now just... generally that good, every time. Image generation comes to mind here - what once required dozens of attempts and careful prompt engineering now works on the first try.
Anyways, the last aspect is agentic coding, which brings us to...

Google Antigravity
Google has (re-)entered the AI coding space, this time with an IDE - Google Antigravity. Their previous project, Jules, hasn’t garnered significant mindshare as a Claude Code alternative, so this feels like a second attempt to break into the developer tools market.
I have to assume this is the result of the Windsurf deal. When DeepMind poached Windsurf’s founders and engineers last summer, leaving the rest of the company to be acquired by Cognition, most observers assumed they would be building some sort of IDE for Google. Even still, it’s impressive what they’ve shipped in under six months.
The product
On the surface, Antigravity is a VSCode fork - very similar to Cursor. I think many developers are going to wonder: why is this different? What makes this worth switching?
I’m still reserving final judgement, but some new features are opening up interesting possibilities here.
For starters, there’s the “agent manager” dashboard. In the launch video, the Antigravity team (i.e., the former Windsurf team) is blunt: “you’ve been elevated to a manager of agents.” And Antigravity’s UI was clearly built with agents in mind. The management panel is some of the best UX I’ve seen for “pair programming” alongside a coding agent2.
For better or worse, this appears to be where the software industry is headed - though I do appreciate that Google’s IDE at least gives you the option to choose between “agent-driven development” and “agent-assistant development.” The former is the “go build this feature while I grab coffee” mode, while the latter is still giving you some semblance of control over the experience.
Then there are Artifacts. These are markdown documents that are generated as the coding agent works - it’s very reminiscent of Cursor’s “plan mode.” But Antigravity uses them in many different ways: plans, step-by-step walkthroughs, screenshots, browser recordings, and test runs. As someone who is still inherently distrustful of long-running coding tasks, I’m a big fan of the ability for users to add comments to the artifact, much like a code review. There’s something psychologically satisfying about being on the same page ahead of time, rather than waiting for it to be completed and then starting over.
One great use case for Artifacts is using them to read and write to internal knowledge bases - something the best Cursor users I know have adopted as a habit, but is far from common knowledge.
Lastly, there’s a browser extension. This is a neat trick that addresses one of the main limitations of coding agents like Claude Code: they can only ever deal with the code. If there’s something wrong in situ - once the code is actually running in a browser - there isn’t a great way for the agent to see it.
Some agents, like Devin, can circumvent this by having access to an entire virtual machine, as well as a browser. However, that’s both a significant undertaking and a potential security risk. Antigravity is leveraging its Google pedigree by having a Chrome extension that gives the coding agent hooks into the browser directly, letting it get its “hands dirty” in the frontend code itself to look for bugs. It’s the kind of integration that’s obvious in hindsight but likely requires being part of the Chrome ecosystem to pull off seamlessly.
The trajectory
Google appears to now be singing the same tune as Anthropic and OpenAI: chatbots are passé, and coding models and agents are the next big battlefront.
Anthropic has been the “leader” in this regard for some time. Even as GPT-5 has put up impressive numbers, most tuned-in engineers I know still prefer Claude as a daily driver for coding. As I wrote about Claude 4.5 Sonnet:
Anthropic has leaned heavily into the coding performance of [Claude 4.5 Sonnet], going so far as to call it “the best coding model in the world” and “the strongest model for building complex agents.” Early reviews seem to support this, with individuals like Simon Willison impressed by how well the model can code, and companies like Cursor endorsing the model from the outset.
And as far as I can tell, Anthropic is doubling down on pushing the frontier of coding capabilities. For whatever reason, they’ve cracked the code (no pun intended) on making models that developers love to use. The latest model can reportedly code for up to 30 hours at a time on long-running tasks - a remarkable number, assuming all of those hours are productive.

Of course, the model choice may not matter in and of itself if we’re ultimately relying on the agentic chassis powering things. And to that end, it feels like Antigravity isn’t aimed at competing with Cursor so much as it is competing with something like Devin - giving coding agents all the tools necessary to work end to end, and only incorporating the human when it deems us necessary.
The agent manager dashboard, the artifacts system, the browser integration - these are all features designed for a world where developers spend more time reviewing and directing than actually writing code.
Beating the allegations
It’s remarkable how far Google has come in the past two-ish years.
For much of 2023, they were widely perceived as being in disarray. The famous “we have no moat” memo leaked in May, suggesting that Google was losing the AI race to both closed-source competitors and open-source alternatives. People didn’t think they would vanish overnight, but certainly many were quick to anoint ChatGPT as a potential “Google killer.”

Now, their models are absolutely best in class, and it’s hard to argue that they’re not extremely well-positioned. Let me break down why.
