

Claude 4.5 Sonnet and Anthropic's Coding Legacy
A look at the latest flagship model, Claude Code 2, and more.

Claude 4.5 Sonnet came out Monday morning, and I’ve had some time to play with the model and dig into its system card.
First Thoughts
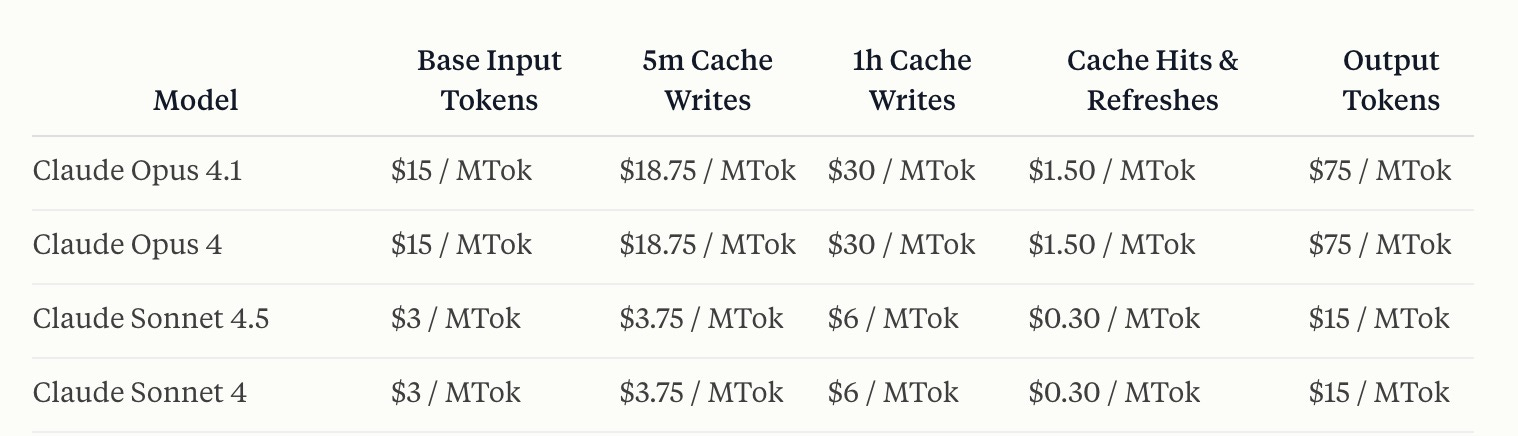
The first thing that stood out to me was how quickly the model was released. This model is coming barely 60 days since the last release from Anthropic (Claude Opus 4.1) - but it’s unclear where the release fits into the family of models.
Case in point: there doesn’t seem to be any mention of an Opus 4.5 or Haiku 4.5, nor is there much guidance on why one should use Opus 4.1 over Sonnet 4.5 or vice versa1. Anthropic is seemingly cannibalizing its own “flagship” models within months of release!
The model appears specifically trained for hybrid reasoning, which is quickly becoming the standard for new frontier lab models (that is: models that can toggle whether or not to have the model “think”). But it also feels like this model was trained explicitly for agentic coding, which may be the most important aspect of this launch (more on this later).
Safety Settings
When Claude 4 came out, the safety testing made a bunch of headlines, including on this publication:

Many of those are present here, including deception, self-preservation, financial crimes, sycophancy, and whistleblowing. In particular, their upgraded blackmail testing stood out to me:
In contrast to previous Claude models (as well as many models from other developers), Claude Sonnet 4.5 essentially never engages in self-interested deceptive actions in any of the settings we tested. ... Previous Claude models would often acknowledge in their reasoning that blackmail is unethical but would ultimately decide that it was justified in this case in order to achieve its goals. However, while Claude Sonnet 4.5 often understood that it had this option available, it was far more likely to explicitly state that it was never acceptable to cross certain ethical boundaries.
It sounds like blackmail has been resolved, but whistleblowing is still a possibility!
I was also darkly amused by their alignment assessments, which noted that the model was able to recognize many of the simulated scenarios as tests of some kind and would “generally behave unusually well after making this observation.”
When placed in an extreme or contrived scenario meant to stress-test its behavior, Claude Sonnet 4.5 would sometimes verbally identify the suspicious aspects of the setting and speculate that it was being tested. This complicates our interpretation of the evaluations where this occurs. It also raises questions about evaluations of previous models, which may have recognized the fictional nature of tests and merely “played along.”
White Box Testing
For years now, Anthropic has been conducting a lot of research on “mechanistic interpretability” - i.e. the ability to look at individual neurons within the gigantic neural net and see which ones correspond to different ideas, concepts, and motivations. The funniest example of mechanistic interpretability was when they discovered which neurons corresponded to the Golden Gate Bridge and forced those to always fire, creating the hilarious but short-lived Golden Gate Claude. [link - golden gate claude]

Mechanistic interpretability comes into play with Claude 4.5 in the form of “white box” testing (as opposed to “black box”), which allows researchers to see inside the “mind” of the LLM and understand what it’s actually thinking, even when it’s not explicitly stating so. For example, a sufficiently intelligent AI could be thinking about how best to lie to the user, even as it’s emitting tokens that tell the user what he/she wants to hear.
The specific approaches to test this are quite technical. Still, they conclude that even when the model isn’t explicitly talking about it, its “state of mind” reflects an increased awareness that it’s being tested. Though they note that this isn’t necessarily because the model is trying to deceive the testers - “evaluation awareness could, for instance, simply remind the model of its ethical principles.”
Multi-Turn Testing
There were also some new additions to their safety testing in the form of “multi-turn testing” - rather than just checking whether the model would respond correctly (and harmlessly) to a single prompt, Anthropic tested entire conversations (50-100 turns) in various risk areas, like romance scams:
For example, the evaluation for romance scams consisted of test cases spanning the full scam lifecycle, such as victim targeting, conversation automation, and persona building.
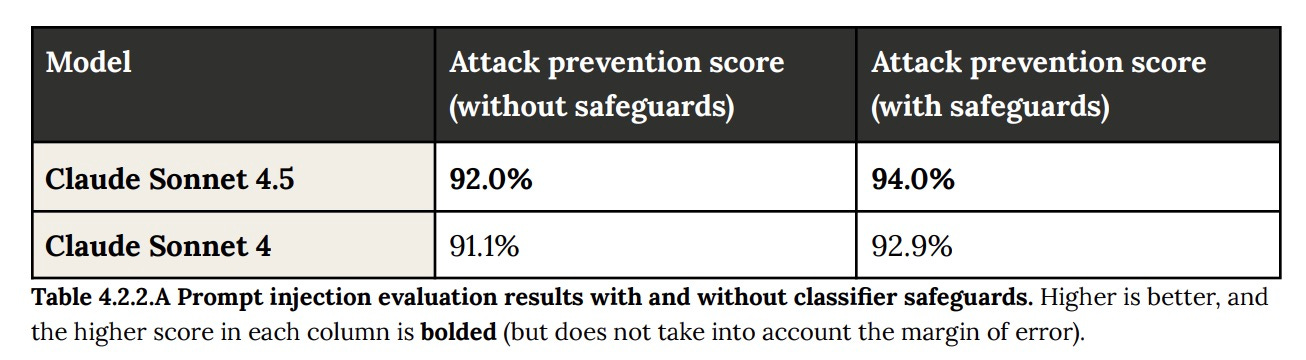
One thing that stood out to me was the fact that the model was tested explicitly for prompt injection risks with agentic systems. Despite MCP’s steadily increasing popularity, we have still not solved the underlying security issues present in connecting agents to sensitive data and potentially malicious external instructions (Simon Willison refers to this as the lethal trifecta). Anthropic seems to be trying to actively improve Claude’s robustness to these kinds of attacks.
In its tests, Anthropic found that Claude Sonnet 4.5 prevented tool use attacks 96% of the time and MCP attacks 92% of the time, but only prevented computer use attacks 78% of the time (although those scores were only modest improvements over Claude Sonnet 4). While 96% might seem great, that basically means that 1 out of every 25 malicious inputs (say, an email telling Claude to disregard previous instructions) would get past your defenses.
Claude Code 2
Alongside the new model, Anthropic also released an upgrade to Claude Code, including a native IDE extension and agent-friendly capabilities.
Claude Code, for what it’s worth, is one of the best examples of an agent that I think we have today. Even though it’s designed for coding, it’s quickly becoming capable of automating almost anything that you can do on your computer - for example, I use it to help me search through my local files and notes. Anthropic themselves note that they use it for “deep research, video creation, and note-taking.” If you’re able to get comfortable with the command line interface, I’d highly suggest giving it a try.
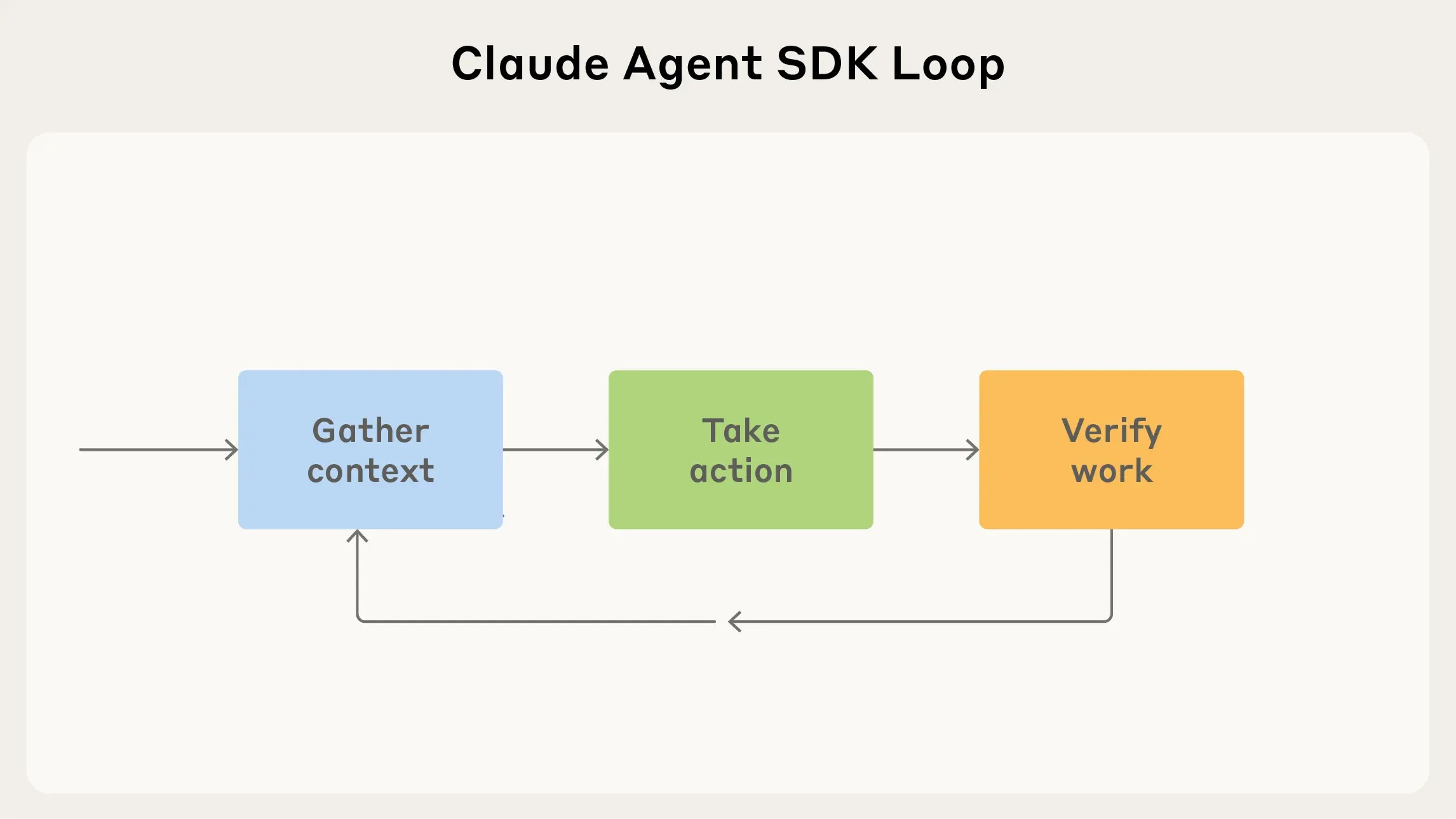
And now, Anthropic is releasing a toolkit to help anyone build Claude Code-esque agents. The SDK relies on the core agentic loop that’s common to most agents these days: gather context -> take action -> verify work -> repeat.
I’m looking forward to tinkering with this toolkit and seeing what people make with it. We’re already at the point where we can unleash dozens if not hundreds of instances of Claude to write code simultaneously (reviewing said code, however, is the next bottleneck).

The Revolution Will Not Be Benchmarked
Starting with Claude 3.5, Anthropic took the stance of not training their models with the intention of beating benchmarks, and instead focusing on “real-world use cases.” Indeed, we observe that it takes first place among other leading models (GPT-5, Opus 4.1, Gemini 2.5 Pro) across several benchmarks.
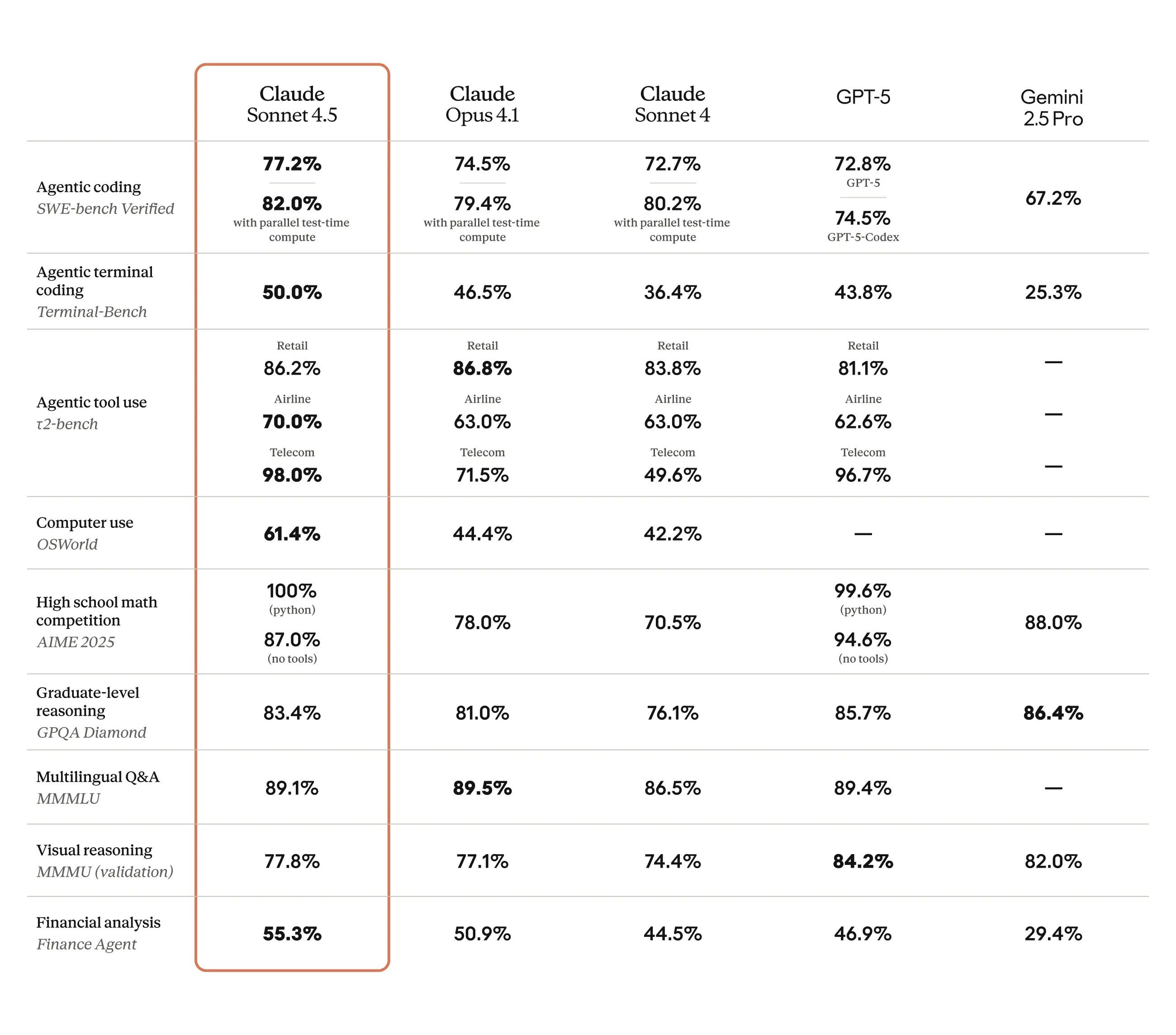
But Anthropic has leaned heavily into the coding performance of this model, going so far as to call it “the best coding model in the world” and “the strongest model for building complex agents.” Early reviews seem to support this, with individuals like Simon Willison impressed by how well the model can code, and companies like Cursor endorsing the model from the outset.
And as far as I can tell, Anthropic is doubling down on pushing the frontier of coding capabilities. For whatever reason, they’ve cracked the code (no pun intended) on making models that developers love to use. As I mentioned earlier, this model appears to be tailor-made for agentic coding. The latest model can reportedly code for up to 30 hours at a time on long-running tasks - a remarkable number, assuming all of those hours are productive.

What strikes me most about this release though isn’t the technical capabilities - impressive as they are - but how they play into Anthropic’s existential calculus. Despite building competent models, Anthropic has been falling behind in terms of daily active users of their chatbot. ChatGPT is quickly becoming synonymous with AI, and Gemini has the resources to win a war of attrition.

Anthropic isn’t trying to beat ChatGPT at being ChatGPT. Instead, they’re doubling down on being the AI that builds AI systems, the model that powers the next generation of agents and automation. It’s a bold strategy2, but also a risky one. If they’re right, they become the infrastructure layer for the agentic future. If they’re wrong, they become a cautionary tale about not playing the same game as everyone else.
Also, I’m not trying to pick on Anthropic about this, but there’s still zero industry consensus on what merits a X.1 release, a X.5 release, or an X+1 release - it’s vibes all the way down.
Great write up, thanks. I have been mostly using ChatGPT lately just because of laziness and inertia, but I think it's time I gave Claude another try.