

DeepSeek: Frequently Asked Questions
Share this with your friends and family.

It's strange - and rare - for me to write long-form pieces about the same company two weeks in a row1.
But here's the thing - I am astounded at how big of a splash DeepSeek is making. It's on the front page of The New York Times2, CNN, CNBC, Fox: you name it. It hit #1 in the US App Store over the weekend and is still there. It's reportedly causing panic within Meta, and has drawn a response from OpenAI's Sam Altman. It's "triggered" a $600B loss in Nvidia stock - the biggest single-day drop in history. Heck, it's even got Nate Silver out here talking about AI on a politics blog.
Suffice to say, it's having a ChatGPT moment3:
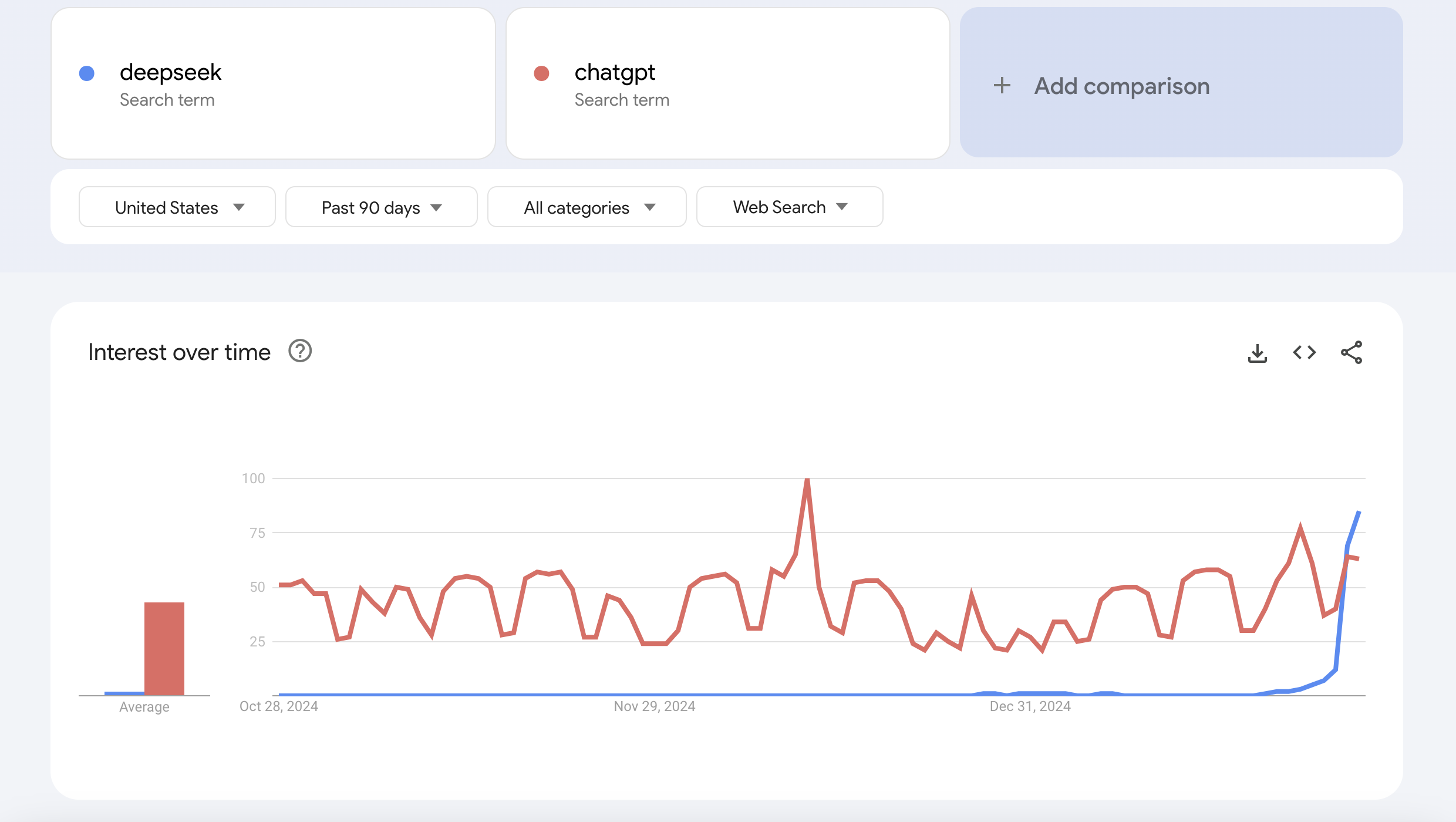
And most importantly, it's caused two different family members - so far - to text me out of the blue, asking questions about a previously obscure Chinese AI company.
Which was a great reminder: for folks who aren't keeping up with this news every day, there are a lot of questions: What's DeepSeek? Is it free? Is it better than ChatGPT? Is the China hype real?
So, at the risk of contributing to the absolute deluge of DeepSeek content out there4, I wanted to put together an FAQ, both for me to send to my friends and family, and for you to send to yours.
What is DeepSeek?
DeepSeek emerged in 2023 as a research-focused spinoff from High-Flyer, a Chinese stock trading firm. What makes DeepSeek somewhat unique is its pure research focus – a rarity in today's AI landscape, where most companies are rushing to commercialize.
While the company maintained a relatively low profile during its first year, the release of DeepSeek-V2 in May 2024 marked a turning point. The model's combination of strong performance and competitive pricing sparked what observers called China's "AI model price war," forcing Chinese tech companies to adjust their strategies. Less than a year later, the company is now impacting the US AI sector with two new models - V3 and R1, released in December and January, respectively.
How does it compare with OpenAI and Google?
DeepSeek's latest models – DeepSeek V3 and R1 – have done something remarkable: performance parity with industry leaders at a fraction of the cost. V3 is a chat model, not unlike ChatGPT and Google Gemini. R1 is what's known as a "reasoning model" - it's capable of "thinking" through math, logic, and coding problems, even highly complex ones. Before R1, the state-of-the-art reasoning model was OpenAI's o1, requiring a paying subscription.
R1's benchmark scores closely match OpenAI's o1 across major tests, with differences typically within a few percentage points. DeepSeek V3 similarly keeps pace with GPT-4o, putting it in the same performance tier as Google's Gemini 2.0 and Anthropic's Claude 3.5 Sonnet. But it's worth mentioning that benchmarks are not the same as real-world usage, and there's already plenty of anecdotal evidence that DeepSeek can fall flat in some areas.
Besides performance, though, there's the matter of cost. Both V3 and R1 are offered at significantly lower prices than comparable models from established providers (in R1's case, current prices are 27x cheaper than the o1, the only commercial alternative).
For a deeper dive on R1 and what it means for the AI space, you can check out last week's post:

{kind=link}
{kind=link}
Can it be used for free?
Yes, for consumers. Their chatbot is freely available through their website and mobile apps (iOS and Android), with no subscription required. That said, recent cyberattacks have caused temporary outages in new signups for the chatbot.

For developers and organizations, DeepSeek has open-sourced their core models under the MIT license, allowing anyone to download and modify the technology. Those needing API access can use DeepSeek's services at extremely competitive rates.
Is it safe to use?

Being made by a Chinese company, DeepSeek raises some concerns about its use, especially around privacy and censorship.
On privacy, DeepSeek's Terms of Service do allow for 1) sending the data back to China and 2) using it to train future models. That said, the open nature of DeepSeek's release means that third parties can use or host it however they want - you can even do so yourself, provided you have good enough hardware. It's likely that a US-based company will start providing access in the very near term.
On content moderation, testing has shown that DeepSeek's models do exhibit some self-censorship around politically sensitive topics, and its responses about historical events often align with official Chinese government positions5.
Ultimately, you'll need to decide what policies you're comfortable with. Clearly, many Americans are fine with using a China-based app, especially given the unpopularity of the now-suspended TikTok ban.
Why did Nvidia's stock drop?
Nvidia experienced the largest single-day stock drop ever on Monday, wiping out nearly $600 billion in market value. While several factors contributed, DeepSeek's release of R1 (and the subsequent attention paid to V2 and V3) likely served as a catalyst6.
DeepSeek has claimed that they were able to train their V3 model for $5.5 million - roughly a tenth of the amount Meta spent on its latest open source model, Llama 37. And in doing so, DeepSeek has challenged one of the core assumptions of the AI boom: that building state-of-the-art AI systems will require billions in additional hardware investment8.
As a result, Wall Street is now questioning whether tech giants like Microsoft, Alphabet, and Meta need to maintain their current level of investment in Nvidia's hardware. The success of more efficient approaches to AI development suggests that future models might require fewer GPUs9.
Update 2/29: Timothy B. Lee has pointed out that the sell-off came just ahead of President Trump’s plans to slap tariffs on Taiwanese chips, including TSMC - Nvidia’s primary supplier. I’m inclined to believe the dip was triggered by insider trading more than a weeks-to-months-long delayed reaction to DeepSeek’s models.
What about America's chip ban?
Some are wondering how DeepSeek could train state-of-the-art models despite heavy export controls imposed by the United States on AI hardware. As far as we can tell, DeepSeek has managed to build its systems without violating the bans.
The company built its systems primarily using Nvidia H800 chips - hardware specifically designed to comply with the original October 2022 bans. After DeepSeek had established its infrastructure, more stringent restrictions on AI chip exports to China came into effect in October 2023 and December 202410.
What's particularly interesting is how these restrictions might have inadvertently spurred innovation. Rather than violating export controls, DeepSeek appears to have adapted to them by developing highly efficient training architectures that require less computing power.
But how did DeepSeek pull off its upset?
One possible reframing of this question is: "Is DeepSeek a fluke or the real deal?" And ultimately, I do believe it's the real deal. While they've benefited immensely from prior research and AI releases, a couple of major breakthroughs were needed to get to this point. I've done my best to craft an oversimplified explanation, but I'd also suggest one of the many well-written technical explainers here on Substack.
The first breakthrough is DeepSeekMoE, which essentially creates a team of specialized experts within the model (MoE stands for "Mixture of Experts"). Instead of activating the entire model for every task – imagine calling in every specialist at a hospital for a simple checkup – DeepSeekMoE only activates the experts needed for the specific task at hand, making the entire system more efficient.
Their second breakthrough, DeepSeekMLA, tackles a different challenge: memory usage. Existing AI models require enormous amounts of memory to remember the entire context of a conversation or document. DeepSeekMLA compresses this information without losing its meaning - similar to how a good summary can capture the key points of a book. This dramatic reduction in memory requirements means the models can run faster and at lower cost.
Does this mean China is ahead of the US on AI?
I'm not ready to declare a new era of Chinese AI dominance just yet. OpenAI still leads the benchmarks with o3, a new reasoning model that's in early preview but not yet publicly available. And if rumors are to be believed, leading AI labs may keep their most powerful models in-house to accelerate faster, cheaper models for public consumption.
What DeepSeek has done is push China to the front of the open-source AI space. While major US companies have generally kept their AI systems proprietary, some firms (led by Meta) are openly sharing their models and research notes, believing that it’s in the world’s best interest to democratize access to AI.
Of course, this still creates geopolitical tensions. If Chinese open-source models become the foundation for future AI development, it could gradually shift the center of AI innovation eastward, with implications for everything from commercial applications to military systems.
If you have more questions about DeepSeek, leave a comment or reply! I'd like to keep the web version of this post updated as more information becomes available.
In fact, I took a look at my archives, and excluding two-part coding tutorials, the last time I came close was May of 2023.
Albeit below the fold, but still - multiple front page stories in the business section.
It’s swamped the discourse so much that part of me wonders whether it’s a Chinese psyop. I promise I’m not a shill.
There's a good chance you're exhausted at the amount of DeepSeek coverage. I'm exhausted at the amount of DeepSeek coverage. But, you know - writers gonna write.
This is not meant to be a defense of DeepSeek's approach here - I’m opposed to the CCP’s censorship of historical events - but it's worth mentioning that other leading AI companies do a similar thing, just with different types of content. ChatGPT, for example, will self-censor if the conversation veers too close to sex and violence. The only truly uncensored model is one that you can run yourself.
Interestingly, while DeepSeek's efficiency achievements aren't new – their V3 model has been matching industry leaders on a fraction of the budget for months, and R1 has been public for over a week – it took until yesterday for investors to react strongly to these implications.
However, this figure warrants careful interpretation. The $5.5 million figure represents only the cost of the final training step: it does not include building out their clusters, paying their research team, or burning money on prior R&D. Still, even accounting for these additional expenses, DeepSeek's efficiency gains point to a possible future where advanced AI development isn't exclusively the domain of companies with massive capital reserves.
Just last week, President Trump unveiled The Stargate Project - a new initiative to spend between $100 and $500 billion on AI infrastructure in the coming years.
I'm actually pretty skeptical of this. I've talked about Jevons Paradox - the idea that as a resource gets cheaper, we consume more of it overall. One thing that reasoning models do is shift a lot of the computation from the initial training stages to the generation stage (i.e. when you’re chatting with it). That means that even if it’s cheap individually, everyone having a reasoning model in their pocket could mean orders of magnitude more GPUs needed.
It remains to be seen whether the new controls will have a longer-term impact. DeepSeek’s CEO has publicly said that they’re still at a major compute disadvantage and are bottlenecked by access to chips.
As always, nice rundown. Also, your mention of 'concerns' around it i good to see. You are only the second writer / publication to mention concerns related to it. Wired is the other: https://www.wired.com/story/deepseek-ai-china-privacy-data/
Seems to me, and I'm going on waaay less info than you, that - politics aside - this is a positive technical development overall that will improve AI efficiencies and cost structures. Am I way off?