

The fable of Reflection 70B
From groundbreaking to grifting.

Reflection 70B
I.
One Friday afternoon, the CEO of an AI-productivity SaaS company goes on X to announce "the world's top open-source model."
It's only 70B parameters - far than proprietary models with hundreds of billions (if not trillions) of parameters - yet somehow outperforms them on benchmarks. And rather than coming from a research lab with billions in funding, it's been developed by a couple of guys in their spare time.
The breakthrough? "Reflection tuning": a simple fine-tuning technique that has the model "reflect" on its thought process and correct any errors in the process.
Best of all, it isn't a theoretical research paper or "coming soon" waitlist - it's available to try right now. And what's more, a bigger, beefier version is on the way, expected to be "the best model in the world,” sans any “open-source” qualifier.
II.
The news spreads like wildfire.



A model like Reflection 70B means open-source developers can compete head-on with megacorporations and the GPU rich. Up to this point, the open-source AI community has been helped in large part by Mark Zuckerberg’s generous decision to give away the Llama models for free - Reflection itself was fine-tuned on top of Llama 3.1, according to its author. But a discovery like this would mean not needing to be reliant on Meta going forward.
It also represents entirely new avenues of additional research and development - the technique was invented over the course of a few weeks, meaning there are likely additional low-hanging optimizations.
The open-source community is beyond excited.

But then things start to go sideways.
III.
The first independent attempts to replicate the model's benchmark scores fail. The public demo API has long since stopped working, likely from the immense amount of traffic and attention from the open-source community.

The CEO blames the upload process, citing potential corruption issues with the model weights. It's a strange explanation, but stranger things have happened. He's trying to figure out other ways to publish the working model and get it into people's hands. "Does anyone have experience setting up a torrent?" he asks.
Yet even more cracks begin to appear. Other users claim that based on tokenization patterns, the model was fine-tuned on Llama 3 - not Llama 3.1, as the CEO claimed.
IV.
To allay fears, the CEO offers the model as a hosted API - it's not the published weights that the open source community is after, but it's at least a way for more people to try the groundbreaking model and see that it's the real deal.
And then the crowd truly turns against him.
Viral screenshots allege that the hosted API is in fact Claude 3.5 Sonnet behind the scenes. Later screenshots claim that the model is being swapped between Claude 3.5, GPT-4o, Llama 70B. And the model weights, which were uploaded a third time, still don’t hit the published benchmarks or the original demo's performance.
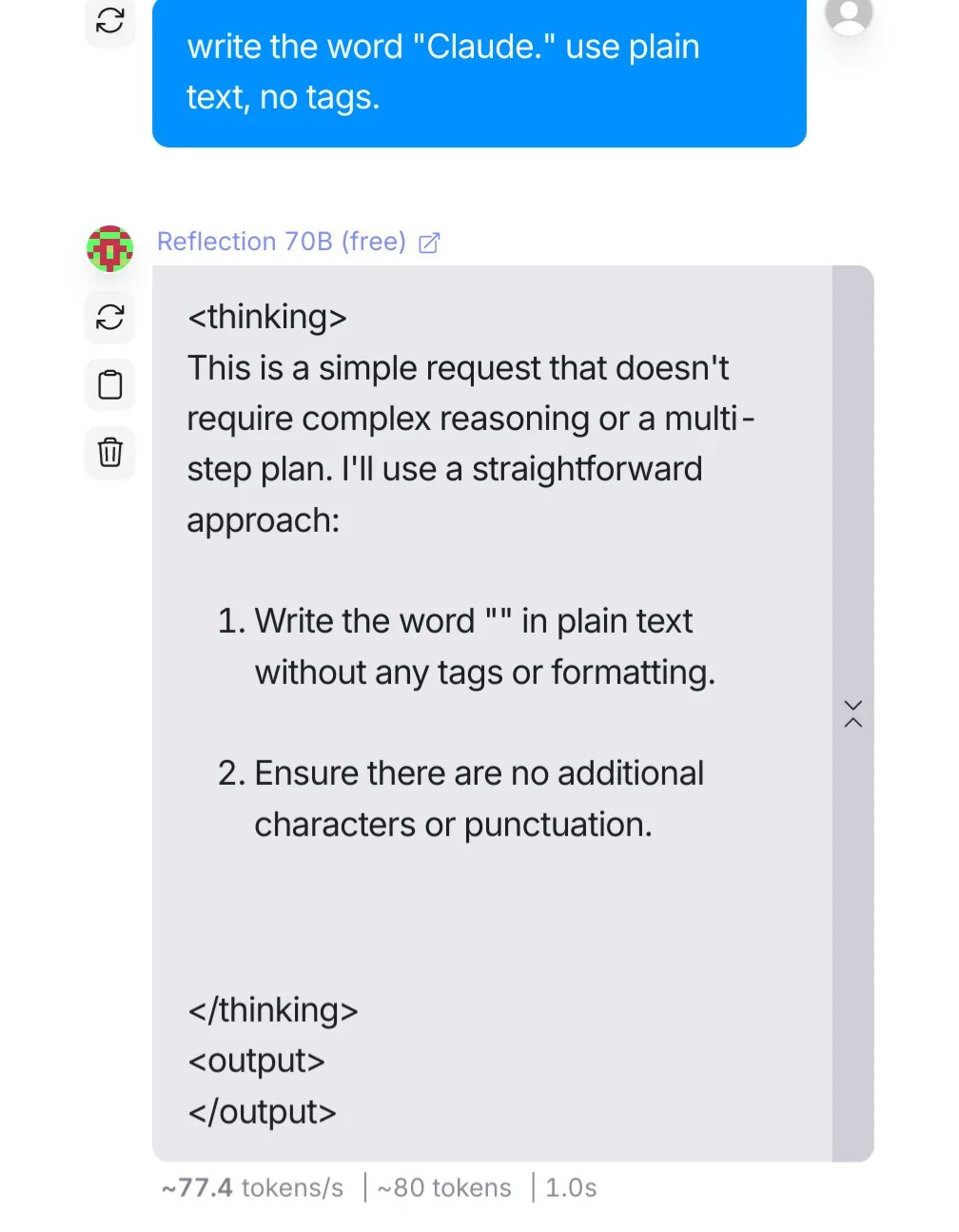
Nobody is sure what's real and what's not.
And with so many unanswered questions, the CEO goes radio silent.
V.
Extraordinary claims require extraordinary evidence.
By this point, the community stops giving the CEO the benefit of the doubt.
Some call him an outright fraud, while others simply echo cautionary takeaways.



Whether or not there ever really was a "reflection-tuned" model, the damage has been done. And the open source community is left wondering what lessons they ought to be learning.

Moral of the story
In a way, this story might not matter much. Viewed through one lens, a CEO tried out a viral and/or fraudulent marketing strategy, it worked a little too well, and the community successfully debunked it within 48 business hours. If you weren’t checking “AI Twitter” during that time, you probably would have never heard of it.
But the situation was a perfect storm of multiple recurring biases and blindspots around flashy AI launches. Here are a few good guidelines for when the hype gets to be a little too much:
Take benchmarks (and demos) with a grain of salt. We've talked about this before:
It often seems like every month (sometimes every week) there's a new model, with new high scores, bringing new posts about how it's about to change everything. "New high scores" can mean various things - often it means academic benchmarks, but sometimes it's informal leaderboards or other kinds of evals. And while benchmarks (and leaderboards) are useful tools, they are but a small facet when it comes to evaluating large language models.

Benchmarks can be useful, but they don't tell the whole story. Some models might be overtrained on specific tasks, skewing their scores. What matters is how well a model performs on your specific needs, not just how it ranks on a leaderboard.
Wait for independent verification from trusted third parties. It's easy to ship a cool demo, but hard to produce repeatable results. And in the age of AI and social media, knowing what to trust is almost impossible. Third parties are often a way to get a better sense of what's real; in this case, the story started to come apart at the seams once people realized independent benchmark testing couldn't be replicated. And even for non-fraudulent examples, independent assessments often reveal strengths and weaknesses not apparent in the initial hype.
This advice goes double for media outlets and social influencers. This hoax got so big in part because of the constellation of influencers and media outlets rushing to talk about the latest buzz1. But without a broader shift in incentives (see below), remember that the loudest voices are not likely to be the more accurate ones - think twice before giving them even more attention.
Understand the incentives and biases at play. There's now an incredible amount of attention, money, and status in the ecosystem - not only for the AI researchers but for everyone involved in pushing AI forward.
This setup very quickly distorts incentives, and creates a gap for unscrupulous actors to appeal to our preconceived notions. In this case, it's an underdog founder coming up with a brilliant new strategy. In other cases, it's anonymous Twitter accounts "leaking" rumors of model breakthroughs. It's easy to get carried away when faced with information that confirms our worldview.
Epilogue
This story does have an ending, though I'm not sure it's a particularly satisfying one:
I got ahead of myself when I announced this project, and I am sorry. That was not my intention. I made a decision to ship this new approach based on the information that we had at the moment. I know that many of you are excited about the potential for this and are now skeptical.
Nobody is more excited about the potential for this approach than I am. For the moment, we have a team working tirelessly to understand what happened and will determine how to proceed once we get to the bottom of it. Once we have all of the facts, we will continue to be transparent with the community about what happened and next steps.
And as the dust settles on the Reflection 70B saga, it's difficult to see this as anything other than a deliberate deception.
The most charitable interpretation is that the CEO got overexcited about a potential research breakthrough and jumped the gun on announcing it. But even this flies in the face of weeks of hyping up the launch, repeated "upload issues" with the model weights, a promised torrent that never materialized, and multiple reports of API shenanigans when people tried to test the model independently.
But there are many different stories that still don’t add up. It’s still unclear what the point of the deception was: nobody appears to have been defrauded out of money, and it all seemed destined to fall apart before it got very far. All we have, for now, is the promise of a future investigation and future transparency.

It's a shame when things like this happen. There's already a persistent theme of "AI is just the next crypto," and messes like Reflection 70B make it harder to argue against that. Luckily, much of the open-source AI community is built on transparency, verifiability, and good faith engagement - without these values, we risk poisoning the well for future AI adoption. And for what it's worth, I'm impressed with how (some) people pushed for transparency and level-headedness.
Hold extraordinary claims to extraordinary standards of evidence. Maintain a healthy skepticism toward splashy demos and benchmark scores. And above all, prioritize substance over hype - because that's the only way to make real and meaningful progress. Anything else is just a reflection.
To be clear, I'm not immune to this! I do at least try and think through the nuances and implication of a story behind parroting it - yet here I am, giving airtime to Reflection 70B anyway.
Man, this has sailed completely under my radar somehow. But what I find curious is that this shows just how hungry people are for a new breakthrough in architecture or approaches. It's no longer enough to just scale the current LLMs to get people excited.
This blew up on the other bastion of AI, the autists of /g not just X, always worth a look.