

o3 is important, but not because of benchmarks
OpenAI's new model offers a peek at the future of AI investment.

Hidden away at the end of OpenAI's advent calendar, they saved possibly their most newsworthy release for last: o3 (and o3-mini), the next iteration of their reasoning model1.
So far, everyone has focused on the model's benchmark scores, particularly on ARC-AGI. And yes, we'll talk about them - but the bigger story isn't about benchmarks. It's about the shift that o3 represents in the changing economics and development of AI.
Big benchmark energy
o3 has topped the charts on several benchmarks, showing best-in-class performance on real-world coding problems and math olympiad challenges. SWE-bench verified, in particular, is a set of problems that are designed to be particularly difficult for AIs - and o3 outperforms the previous record by a significant margin:
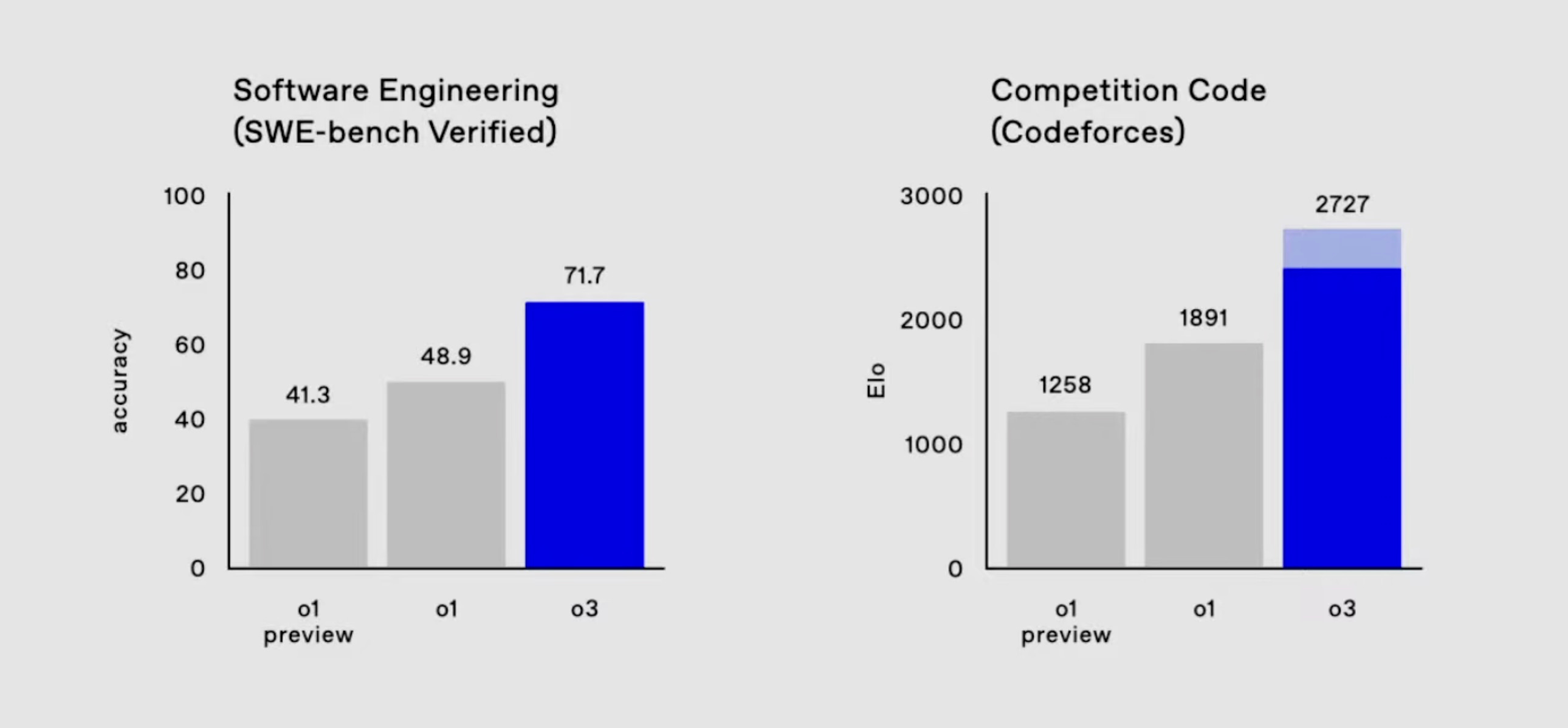
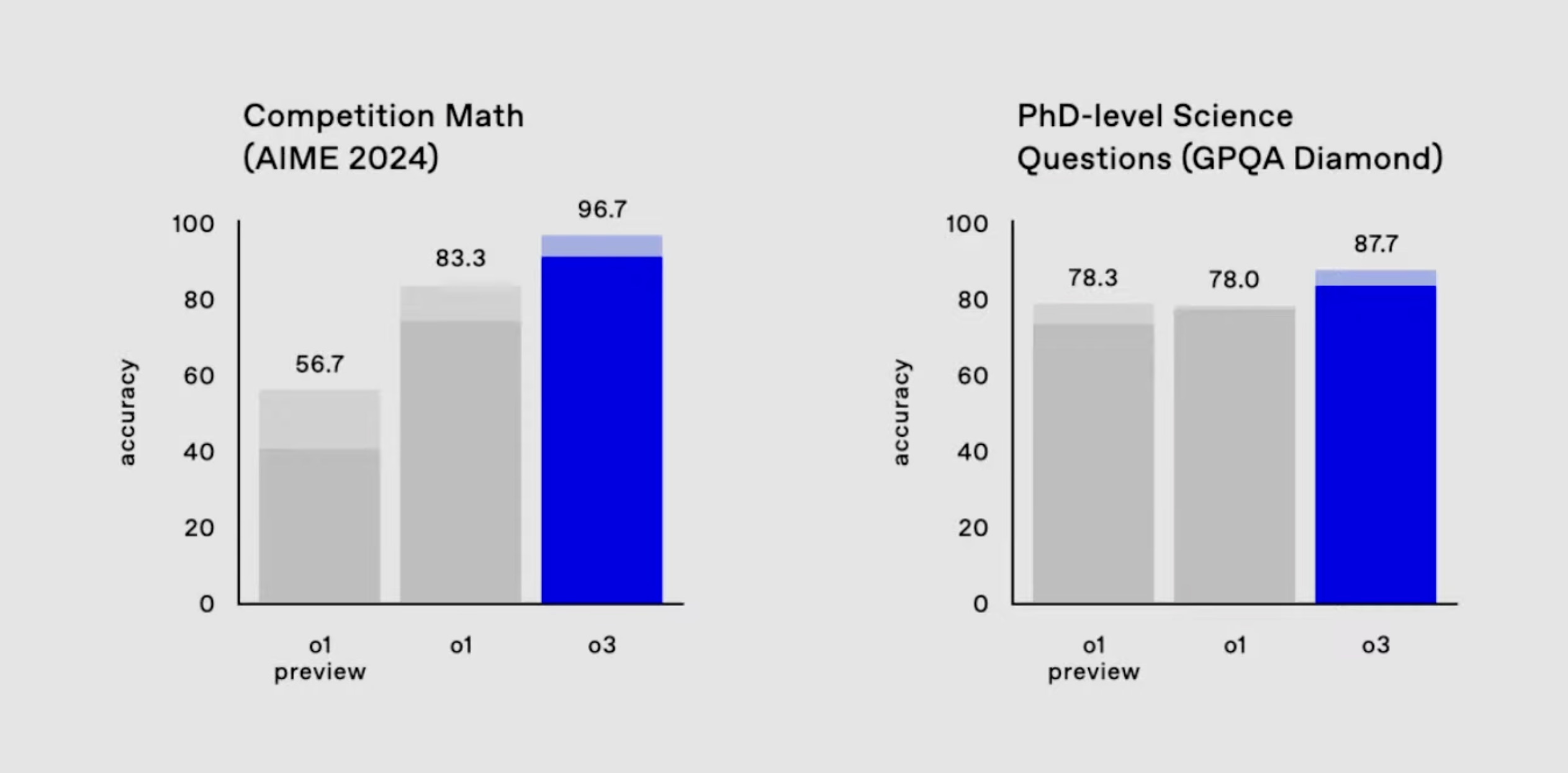
But what's caught everyone's attention is its performance on the ARC-AGI benchmark. For context, ARC-AGI is a visual reasoning benchmark released in 2019 by François Chollet, creator of Keras. It was specifically designed to be particularly challenging for language models, focusing on abstract pattern recognition that comes naturally to humans but has historically been difficult for AI.

The benchmark's creators explained their rationale clearly when launching the ARC prize ($1 million to the first open-source solution to score 85%):
Modern AI (LLMs) have shown to be great memorization engines. They are able to memorize high-dimensional patterns in their training data and apply those patterns into adjacent contexts. This is also how their apparent reasoning capability works. LLMs are not actually reasoning. Instead they memorize reasoning patterns and apply those reasoning patterns into adjacent contexts. But they cannot generate new reasoning based on novel situations.
For nearly five years, progress on ARC-AGI was painfully slow - it took until GPT-4's release to reach even 5% performance on the benchmark. For reference, the average human scores 85%, with STEM college graduates typically scoring above 95%. But in just the last few months, the scoreboard has shifted dramatically:
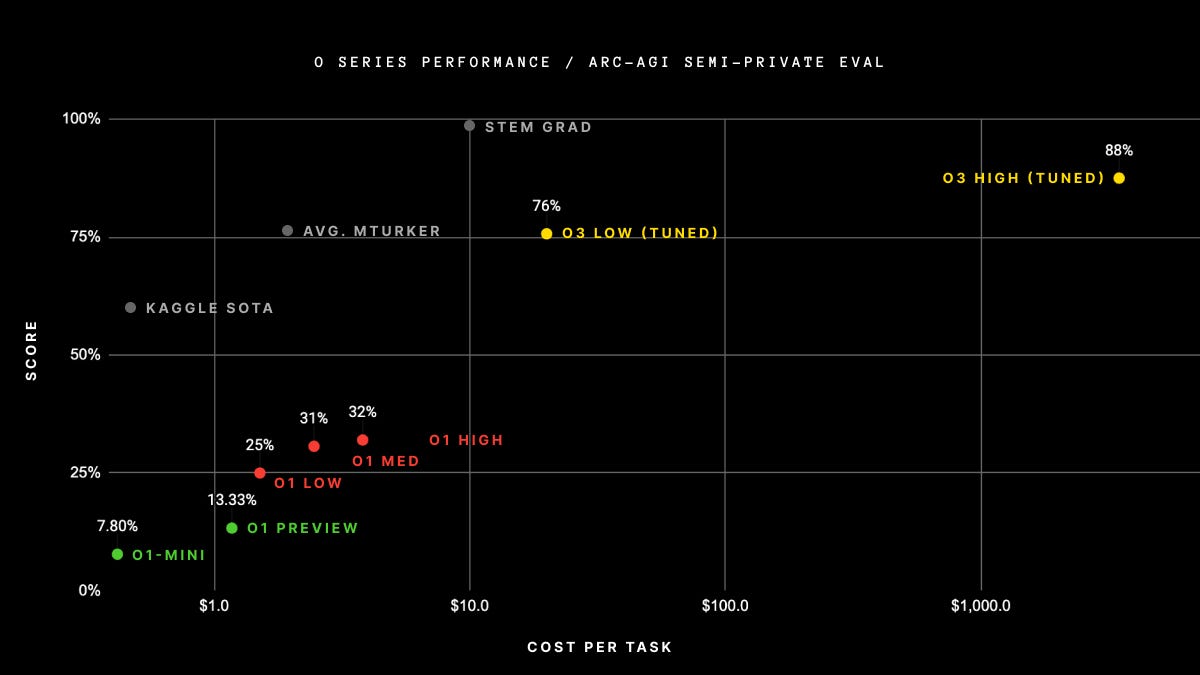
First came o1, scoring 29%, and now o3, scoring a dramatic 87% - enough to claim the million-dollar ARC prize if it were an open-source model. But beyond the headlines, this achievement reveals something more fundamental about how AI systems are becoming more capable - and more expensive to operate.
The economics of thinking
There's certainly some nuance in these numbers2. That 87% score was achieved with the highest levels of compute – lower-compute versions "only" reached 76%3. Even o1 had a smattering of results, depending on whether it was set to low, medium, or high thinking.
This is a pretty new way to think about working with LLMs - previously, to get better results from an LLM, you just had to pick a different model (or level up your prompt engineering skills). Now, you can simply tell the model to “think harder” and get better results - for an additional fee.
We can already see these controls making their way into OpenAI’s API, via a new “reasoning effort” setting:

This all touches on a major debate in the AI community about whether scaling up AI models using more data, computing power, and more extensive neural networks is reaching its limits in improving AI capabilities.
o3 appears to be an answer to that debate - but with a twist. The scaling isn't happening during training time, but during inference. Traditional language models had to "bake in" all of their intelligence during the initial training phase, spending billions of dollars on compute up front.
As I noted when o1 was first released:
The graph on the right, though, implies a whole new set of scaling laws that we haven't yet touched. "Test-time compute" means that when OpenAI gave the model more "time to think" (i.e., GPU cycles), it was able to think its way to better results.
I don't want to get too speculative here, but this would imply that increasing intelligence isn't solely dependent on continuously training the biggest and smartest model up front - instead, you can train a (still very large) model once and then tailor your GPU spend depending on how much intelligence you want to throw at the problem.

This shift in how AI systems achieve intelligence helps explain a crazy trend: it took three years to go from GPT-3 to GPT-4, but barely three months from o1 to o3.
Without more notes from OpenAI's research department, it's hard to say why, but we can make an educated guess. Ilya Sutskever (cofounder of OpenAI) noted in a recent talk:
Pretraining as we know it will unquestionably end, because while compute is growing through better hardware, better algorithms, and large clusters, the data is not growing because we have but one Internet. You could even go as far as to say that the data is the fossil fuel of AI. It was created somehow and now we use it, and we’ve achieved Peak Data, and there will be no more. We have to deal with the data that we have.
If you take this to be true (and I'm not entirely sure I do), it would imply that future intelligence gains would need to come from other parts of the training workflow. That's both a blessing and a curse - it's challenging because we have to invent new research techniques, but it's promising because it may mean we can avoid repeating the massive, expensive pretraining phase.
And that seems to be echoed by OpenAI researcher Jason Wei:
o3 is very performant. More importantly, progress from o1 to o3 was only three months, which shows how fast progress will be in the new paradigm of RL on chain of thought to scale inference compute. Way faster than pretraining paradigm of new model every 1-2 years
Is this AGI?
In short: no. The ARC Prize creators themselves are clear about this:
ARC-AGI serves as a critical benchmark for detecting such breakthroughs, highlighting generalization power in a way that saturated or less demanding benchmarks cannot. However, it is important to note that ARC-AGI is not an acid test for AGI – as we've repeated dozens of times this year.
But we need more benchmarks like ARC-AGI - not because they measure AGI (they don't), but because they represent problems that are easy for humans and hard for AIs. Too many AI benchmarks are only solvable by a handful of STEM PhDs, which doesn't tell us much about general intelligence.
There's a computer science term that I’ve been thinking about lately: "hillclimbing." It's a type of optimization where you start at a random (or semi-random) point, tweak your approach slightly, decide which direction is better, and continue in that direction. The name comes from the visual metaphor - at each step, you are "climbing the hill" of performance ever so slightly, until you reach a local maximum.
This is, in some sense, what's happening with AI development right now. We create benchmarks that challenge current AI capabilities, companies optimize their models to solve them, and then create new, harder benchmarks. For their part, ARC said they're cooking up something totally different for v2.
Perhaps with enough hill climbing across enough different dimensions of intelligence, we can start to cobble together something resembling AGI4. But we're not there yet, and o3's impressive performance on a single benchmark - while noteworthy - is just one step up one particular hill.
The efficiency game
But even if it's not AGI, o1/o3 does represent a new frontier in AI development. The ability to achieve higher intelligence through inference-time compute means development cycles are accelerating dramatically, with improvements happening in months rather than years.
It means companies can funnel their massive funding rounds (like Anthropic's recent $7.3B and $4B raises) directly into achieving better results, without waiting for lengthy training cycles.5
And it means efficiency is almost as valuable as scale - if you can get better reasoning for cheaper, huge training runs don't matter as much6.
That last point seems really, really important - as we move forward, the winners in AI might not be those with the biggest war chests, but those who can most efficiently convert compute into intelligence.
It's no longer just about how much money you can spend - it's about how wisely you can spend it. That's a very different benchmark than the kinds we’ve been measuring so far.
Why not o2? Likely to avoid IP issues with the major telecom company.
For starters, the data point says “o3 (Tuned)” - it’s very unclear whether the benchmark was set by a fine-tuned variant of o3. It’s also very unclear how the x-axis on the chart is being measured.
Back of the envelope calculations suggest OpenAI might have spent over $1 million getting to 87% – more than the prize is worth!
Other promising benchmarks include NovelQA, a long-range novel question-answering benchmark, and GSM-Symbolic, a benchmark for symbolic mathematical reasoning.
It also means the hype from "reasoning" models stands to usher in the next wave of massive AI funding rounds now that there's a growing correlation between inference spending and capabilities.
To be clear, the industry is already very focused on efficiency - whether through hardware (custom chips), software (pruning/quantizing), or research.