

The State of AI Engineering (2024)
Notes from the AI Engineer World's Fair.


It’s been two weeks since I attended the second AI Engineer conference (dubbed the "AI Engineer World's Fair" this time around). There was a lot of new technology, design patterns, and lessons to learn - though some things were pretty familiar from last year, too.
While there were plenty of announcements, I'm unsure how many were new for the first time. Some things like Google's Gemma 2 was released on the same day as the conference, while others like LangGraph Cloud were announced at the event (though many products still had a waitlist).
Ultimately, I wanted to talk about where the frontier AI engineering is today, and where things are shortly headed. To get a sense of last year's conference, take a look at my previous analysis:

AIE 2
The conference itself was significantly bigger, from the number of attendees to the number of talks to the venue itself. There were clearly some growing pains, and some last-minute emergencies (like one of the co-organizers being stranded in Singapore due to visa issues!).
The conference had a whopping twelve different types of content (thirteen if you count the "Hallway track" for conversations and networking):
Keynotes
Workshops
Expo Sessions
Open Models
RAG & LLM Frameworks
AI in the Fortune 500
Multimodality
Agents
Codegen & Dev Tools
Evals & LLM Ops
GPUs & Inference
AI Leadership
Workshops and AI Leadership sessions were only included with specific ticket types, but everything else was open to all attendees. That also includes the Expo (a full conference hall of demos, swag, and "activations") and a few other surprises - like an HF0 Demo Day on the last day of the conference.
Consuming everything was impossible, though about half of the tracks were livestreamed and the remaining recordings are in the process of being edited and uploaded. Most of my time was spent checking out the talks on evals, RAG, AI in the Fortune 500, and to a lesser extent, agents and codegen.
As part of its social promo, the conference generated summary cards for a number of talks, and I’ve included a few of them below.
Core themes
Like last year, several themes jumped out from the talks again and again. While some are similar to the last summit, others have evolved.
Evals are still (really) important. After last year's conference, I wrote:
[Developing good prompts] is compounded by the fact that we don't have good QA systems figured out yet. And given the non-deterministic nature of LLMs, tweaking prompts and models just seems like trying to run A/B tests without doing quantitative measurements. How do we know if the changes we're making are actually working?
This is still true, but there are better practices (I'm not sure I'd say "best practices" yet) for doing evals than before. One workflow: starting with simple units tests/assertions (even as simple as string matching on LLM output), logging and monitoring outputs, curating an effective eval set, then finally performing prompt engineering on the final output.
As Hamel Husain said, vibes can get you to V1. But in contrast to a year ago, many engineers are painfully aware of how hard it is to take AI from prototype to production - and even with a good V1, maintaining performance across model deprecations and drift is still quite challenging. What surprised me was how straightforward some of the recommended approaches were, like string matching or entity extraction.
Beyond the basics, there was much discussion about emerging techniques. One that repeatedly came up was “LLM as a judge” - using GPT-4 to evaluate how well your prompts are working. There are some big tradeoffs here, not least of which is the risk of removing the human from the loop.
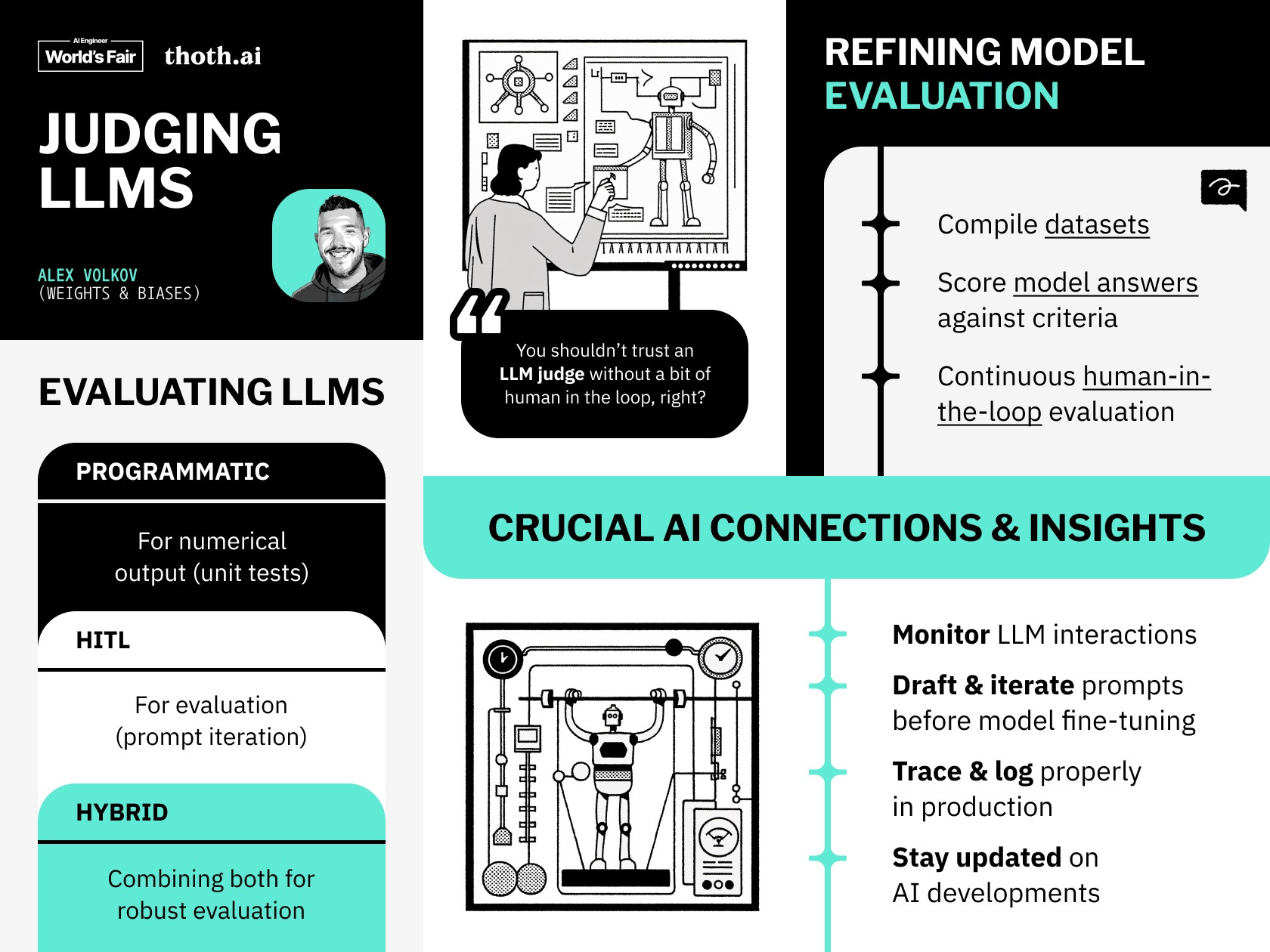
Agent infra is the new hotness. At the conference, I saw a shift in the types of software being launched. Just a few months ago, there were dozens of different vector DB startups and RAG (retrieval augmented generation) libraries hitting the scene. Now, there is a new wave of products designed to deploy and monitor your AI agents.
More developers are beginning to experiment with agents, which replaces specific lines of code and replaces it with real-time LLM decision-making. It can (in the ideal case) allow for open-ended problem-solving and tool use. But in practice, there are some gaps around reliability and correctness - agents can get stuck in endless loops or run into problems with using underlying tools.
With agent infrastructure (e.g., LangGraph Cloud, a hosted SaaS product to deploy agents at scale), engineers can more effectively structure their agents, view traces for each run, and manage prompts and evals. That said, I’m still fairly skeptical about the current capabilities of general-purpose agentic workflows1.
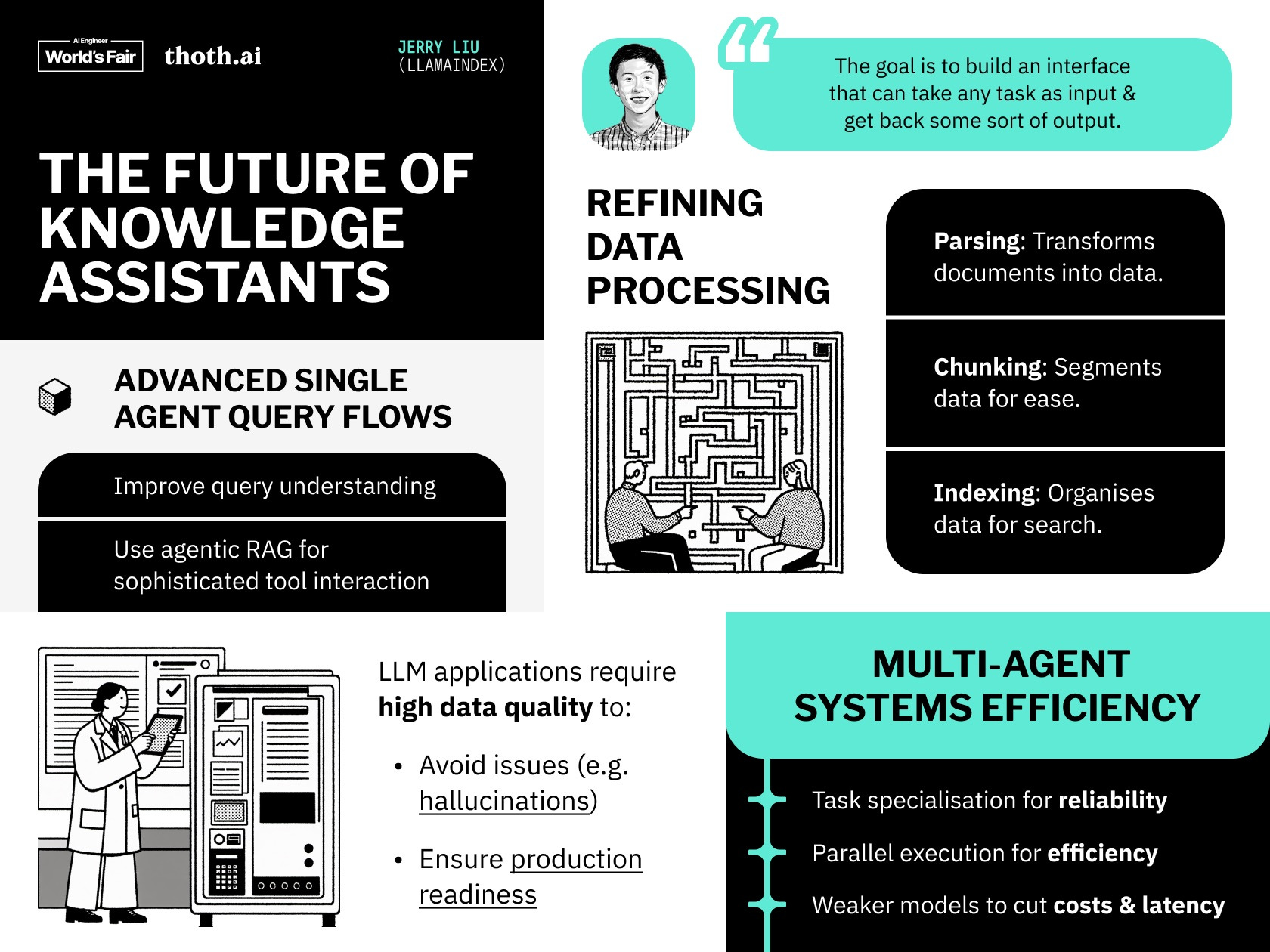
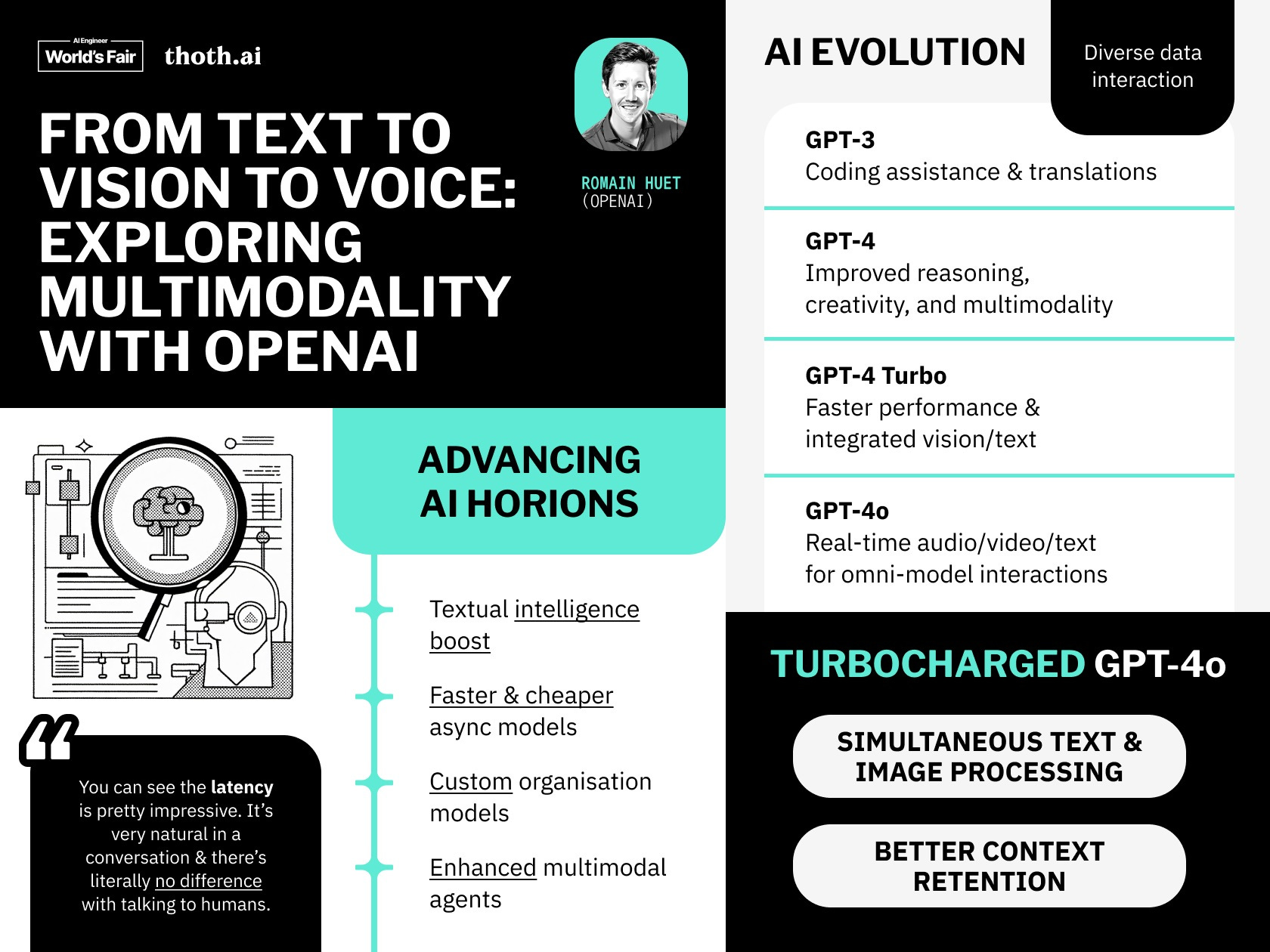
Multimodality is a strange beast. One of the biggest trends emerging from foundation models this year is multimodality. While GPT-4 could ingest images, GPT-4o natively works across text, voice, and images. Just this week, we saw the open-source community playing catch-up with its own natively conversational model.
However, I don’t think we’ve fully grasped what it means to build with natively multimodal LLMs. The cost of generating real-time, realistic, intelligent speech is quickly dropping. We’ve barely figured out good ways to “chat with your documents”—what does it look like when you can speak to them, too? What applications or experiences are unlocked when spinning up a swarm of conversational agents takes minutes?
Great AI engineers work across boundaries. Swyx originally defined the AI Engineer as a category between “ML Engineer” and “Software Engineer.” Yet what we’re seeing is that those boundaries are becoming blurrier.
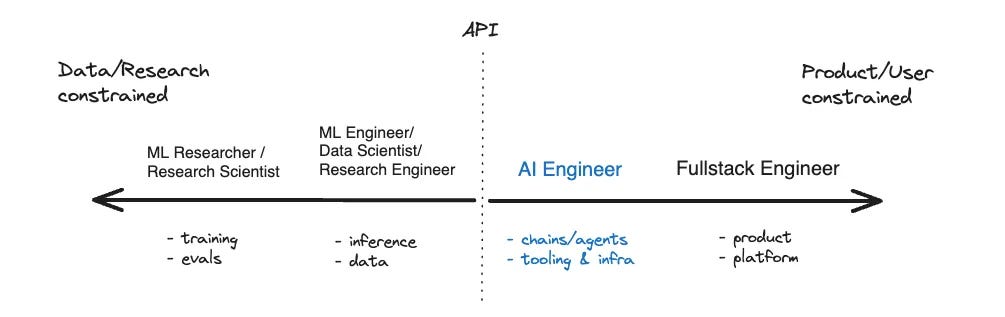
One definition of an AI Engineer is someone who works with chains and tooling but not products or data. Yet, as the field grows, AI is impacting engineers in multiple ways:
They can use code autocomplete and general-purpose chatbots that work out of the box.
They can build LLM-enabled product features that require new frameworks and architectures (RAG, agents, etc).
They can leverage full-fledged coding agents that automate large parts of software planning and implementation.
So, depending on your use case, it may not be as simple as working only with infrastructure and agents. A great AI Engineer is flexible enough to move up and down the stack, harnessing AI agents, digging through evals, or fine-tuning open-source models.
And last but not least:
The vibe is shifting
What stood out the most to me is how the conference and the topics themselves have already started to mature. The last AI Engineer Summit was only eight months ago, but the vibe felt quite different. Again, from last year:
One of the most eye-opening things was how raw a lot of this is. The technology, the design patterns, the libraries, the research, the QA - all of it. As much as it might feel like some folks are already miles ahead, the reality is that we're just starting to figure out what's possible.
Having been to two of these, perhaps the biggest surprise was how commercial much of the conference felt this time. Many of the workshops felt like infomercials for various pieces of SaaS, including databases, deployment, and diagnostics. Many Expo booths would have fit right in at other tech conferences. Just take a look at the logos up top if you don’t believe me.
That's not necessarily a bad thing - every ecosystem matures eventually. But there was also a growing sense of responsibility; many of the challenges in AI Engineering aren’t strictly technical. Drawbacks like hallucinations or prompt injection aren’t going away any time soon, and it’s up to the builders to educate others on how to use LLMs effectively.
Likewise, there’s a growing trust crisis in AI - the public no longer gives technology companies the benefit of the doubt with data collection and usage, meaning any new AI feature faces heightened scrutiny and skepticism.

Ultimately, being surrounded by so many hackers and builders was invigorating - it served as a reminder of how malleable so much of this technology is. And it reinforced my belief that the future of AI is neither human extinction nor techno-utopia - I didn’t talk to a single person about AGI or extinction risk all week.
Rather, I think we’re headed towards something more familiar and more pedestrian. Our chatbots and AI assistants will continue to get smarter and more ubiquitous, incorporated into the platforms and products we use daily, with an ecosystem of dev tools and B2B SaaS to support the engineers making it happen.
If you’re interested in learning more about building with LLMs, I’m working on an AI engineering course, and I want your feedback to help tailor the content. Sign up for updates here.
The one exception here might be coding agents such as Devin, but I haven’t had enough hands-on experience to make a solid decision.
Nice summary. For those who were not there (like me), the livestreams are available on YouTube (at least from some tracks, like keynotes, multimodality and codegen) https://www.youtube.com/@aiDotEngineer/streams
great recap! and thanks for coming again! i would say the commerical bent is partially my fault - because i was trying to give people a survey of the landscape of ai tooling to take home to their own companies to discuss. next year i will make more effort to rebalance toward more applications