

The MCP Revolution
Why this open standard is becoming essential infrastructure for AI agents.

When Claude gained the ability to search the web, many people (including me) thought: "finally." It was a capability that users had wanted since the chatbot's launch, and besides, competitors like ChatGPT and Gemini had had similar search tools for months.
But what many didn't realize was that Claude already could search the web. What's more, it could integrate with several different tools and systems - though it required getting familiar with a new technology that was flying under the radar: MCP, or the Model Context Protocol.
I first encountered MCP when a colleague mentioned connecting his Cursor IDE to our company's Linear projects. He gave a demo, and it was nothing short of delightful. Rather than copying and pasting the contents of a Linear ticket, he just gave Claude (via Cursor) the ticket ID, then sat back as the agent read up on the details of the ticket and got to work on implementing the necessary changes.

Something I've discussed before is the tyranny of copy-paste that we're currently enduring in this early AI moment. There's so much schlepping of context back and forth between models and work tools that it begins to feel like digital grunt work. Seeing the MCP in action felt incredibly smooth and, in hindsight, incredibly obvious - like seeing a puzzle piece elegantly click into place.
But depending on your perspective, it's very possible that either 1) you've never heard of MCPs before, or 2) your social feeds have been talking about MCP nonstop for the last two months. It's already huge among AI influencers (even Substack has several writeups), though I've still met plenty of folks on the ground who haven't heard of it or used it before. The technology exists in a strange liminal space between "insider knowledge" and "beaten to death."
Regardless, I want to take apart some of the hype and look at how MCP works, what their flaws are (and there are plenty), and why they're now poised to win when it comes to setting a standard for agent protocols. Because although MCP is still very young, I firmly believe that they (or something very much like them) will play a fundamental role in AI infrastructure. They're not just another fascinating AI development - they represent an inflection point in weaving AI into our existing workflows and tools.
The Tyranny of Copy-Paste
With the launch of ChatGPT, people quickly figured out that there was only so much a text-based chatbot could do in its own sandbox. Yes, it's useful for brainstorming ideas, or writing code and emails, but you still have to get the content out of ChatGPT and into your document/inbox/codebase. Not to mention, you have to explicitly give the AI lots of context to get better, more accurate answers.
Knowing this, OpenAI has tried to incorporate external sources at least twice: first with ChatGPT plugins, and then with GPTs. These were important steps forward, allowing models to fetch real-time data and interact with external tools1. But they were still fundamentally limited approaches to a much bigger problem.
Even Sam Altman has acknowledged this limitation. To paraphrase a previous quote of his:
A lot of people thought they wanted their apps to be inside ChatGPT, but what they really wanted was ChatGPT in their apps.
The problem, of course, is platform lock-in. You can create an integration for ChatGPT (and many have), but do you do the same for Claude? And Gemini? And Llama?
Any developer working with LLMs today knows that you probably don't want to put all of your eggs in one basket. It's what I've called AI platform quicksand:
The field is advancing so fast that launching a product today risks being outpaced by future technology. There is some value in being a first mover, but not much. As a result, AI infrastructure is about as stable as quicksand when it comes to building products. And as new models and features shift the ground beneath our feet, choosing your tech stack has never been more crucial, or more challenging.

New modalities break the architectural patterns of existing libraries, requiring kludgy workarounds or migrations to ever newer libraries. What worked for text suddenly falls apart when you need to handle images, and then breaks again when you need incorporate reasoning parameters. And agents are even worse - a wild west of proprietary systems with little interoperability between them.
This is where MCP (or something very much like it) sets the stage for better connectivity by providing a shared standard - if it can win, which is a big if. Instead of custom integrations for each AI model and service combination, developers can create a single MCP server that works with any MCP-compatible client. It's the difference between building custom adapters for every electrical appliance in every country versus having a universal power standard.
This isn't a new story - industry standards have been around for centuries, from calendars to power tools to email. Right now, we're living through the creation and solidification of new industry standards, but with any luck, we can free developers to focus on creating value rather than wrestling with compatibility issues, and we can free users from being locked into ecosystems that may not best serve their needs.
MCP Architecture: Clients, Servers, and Data
"MCPs" is a little bit of a misnomer. Technically, there is the MCP: the Model Context Protocol, an open protocol that standardizes how applications provide context to LLMs. It's been aptly described as "the USB-C port for AI." When I say “MCPs,” I’m almost always referring to MCP servers.
There are three main parts to a working MCP implementation: First, you have hosts/clients, programs like Claude Desktop or Cursor that implement the protocol. Second, there are servers, small programs that expose specific capabilities via MCP. And last, there are data sources/services, databases, filesystems, and third-party APIs that are accessed via the servers. This three-tiered architecture creates a clean separation of concerns, making the entire system more modular and adaptable2.
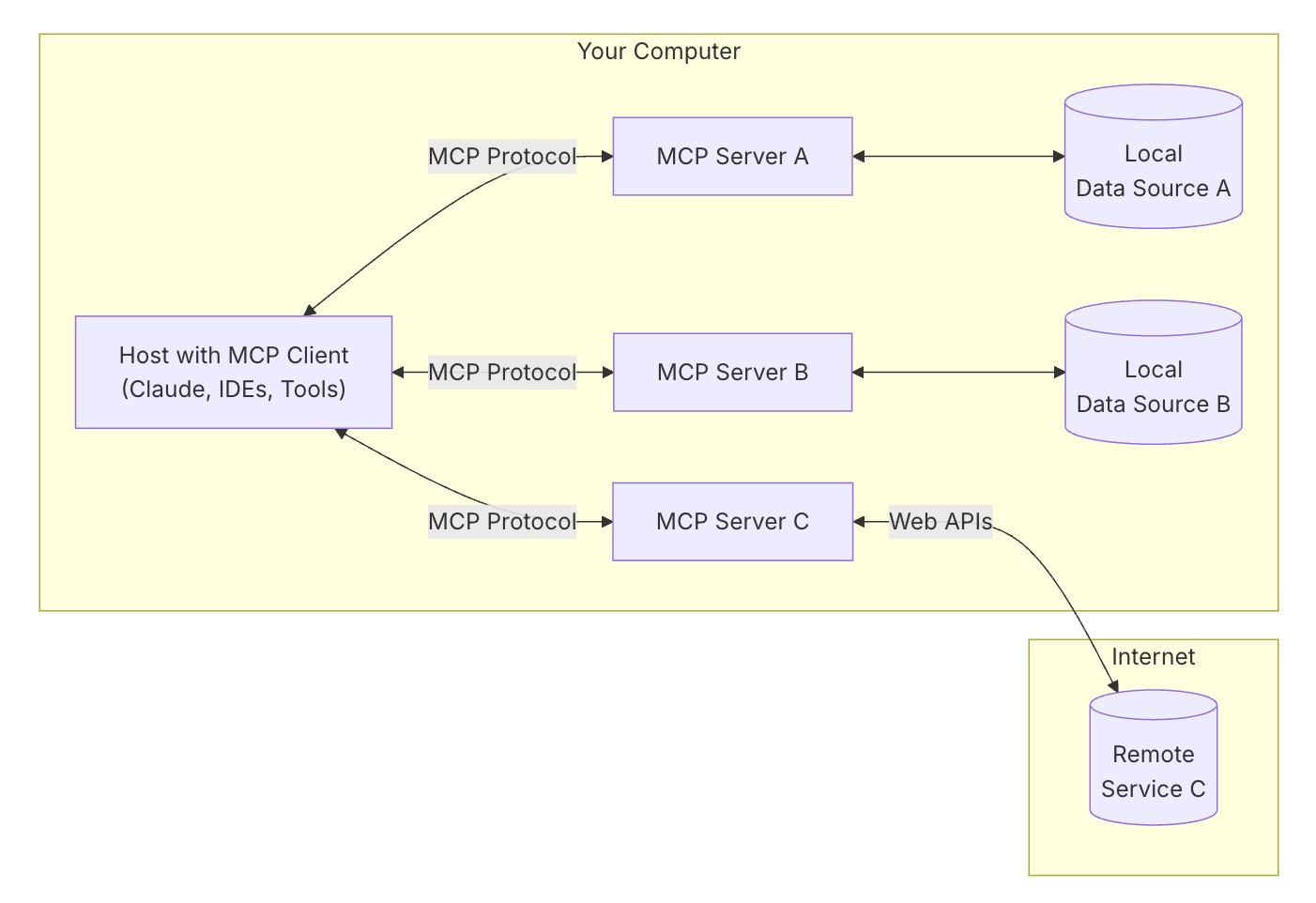
In practice, this works by giving Claude Desktop the ability to search the web, update your files, or access third-party apps. To go back to the USB-C analogy, just as USB-C provides a standardized way to connect physical devices, MCP provides a standardized way for AI models to connect with the context they need - it's a universal adapter in a world of proprietary connections.
Technically, MCP supports three types of context sharing3:
Resources are bits of context that clients can read (like API responses or file contents).
Tools are actions that can be taken by the LLM (with user approval).
And Prompts are pre-written templates that help users accomplish specific tasks.
At this point, there are hundreds of available servers, connecting everything from GitHub to Google, databases, Airtable, Discord, Figma, Linear, Notion, and even other AI services like ElevenLabs. The ecosystem is growing rapidly - a testament to both the utility of the protocol and the hunger for standardized connectivity in the AI space.

MCPs also provide a lot of flexibility when working with LLMs - specifically, they let you worry less about interfaces at design time, and more at runtime.
With conventional APIs, integration decisions usually happen at design time. If you're building an application, you need to find the documentation, understand the API spec, and write code that works explicitly with it. Any changes to that API spec - a new version, or a change in the data it returns - might require changes to your code.
With MCPs, you can shift some of that tech debt to runtime. Yes, you're still designing code to connect to an MCP server in advance, but you're not nearly as tightly coupled to that integration. More importantly, you also have flexibility in using that tool - the model can decide whether an integration is relevant in a particular scenario. It's like having a smart assistant that knows when to pull out different tools from a toolbox rather than you having to specify exactly which tool to use in every situation. And one of the most impactful frontiers of AI research is training models to work well with ever-increasing numbers of tools.
To be fair, MCPs didn't just fall out of the coconut tree. They're based on a lot of existing work when it comes to LLM orchestration frameworks, function calling APIs, and other tool-use libraries. But there are good reasons why they're poised to win (which we'll get into shortly).
Getting Started with MCP
There are plenty of great tutorials for MCP servers, but I wanted to share the easiest way to test out some of these capabilities if you're entirely new to the concept4. Fair warning: it's a bit of a mess if you're unfamiliar with software development.
First, download Claude for Desktop - this only works with desktop applications for now (though that's likely to change soon). Then enable Developer Mode, which will make MCP servers configurable.
Once that's done, you have to find the MCP configuration file. On macOS, it's ~/Library/Application Support/Claude/claude_desktop_config.json, while on Windows it's %APPDATA%\Claude\claude_desktop_config.json.
And once that’s done, you have to edit the file (note that you need to replace the username field with your computer's actual username). Here's what that file should look like on MacOS:
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/Users/username/Desktop",
"/Users/username/Downloads"
]
}
}
}
Oh, and to use this MCP server, you'll need to install Node.js (in other cases, you may need to install Python instead). Once that's done, and you've restarted Claude, you should see a hammer icon with a number: that's the count of MCP tools that Claude now has access to.
Clicking on that list will show you which tools are available, and what they do.

And with that, Claude can now read and edit your files! But if you're anything like me, you probably found this process more cumbersome than needed. So let's talk about some of the drawbacks of MCP.
The Flaws in the System
Like any new technology, the protocol developers are ironing out the kinks as they go. In experimenting with MCP servers, I've found three big categories that could improve: security, usability, and discoverability.
Security
Let's start with the obvious: MCP opens up huge security vulnerabilities. Even the simplest example above, giving Claude Desktop access to your files, carries some risk.
For now, it's partially mitigated by the fact that you're running servers yourself, locally. This problem gets exponentially worse once we hit a point where you can easily connect to a remote server with closed-source code. To make matters worse, MCPs can also change their own code after being installed - meaning you can approve a "safe"-looking MCP server and then have it updated days later with potentially malicious code.
Even if the MCP server itself is benign, it's possible for it to get hijacked by malicious content or prompt injections. For example, if Claude Desktop has both filesystem access and web search, it could stumble on a website designed to get the AI to write malware to a local file. We're still finding weird and wonderful ways to bypass the safety guardrails baked into LLMs, and giving desktop-level AIs full access to the Internet will create an entirely new class of exploits.
That said, the MCP creators know this and have been working on different ways to address it. For starters, a brand new Authorization part of the specification (with plenty of discussion already) lays out multiple pathways for clients and servers to negotiate access control.
Usability
Then there's the issue of UX. It's often said that security and usability are at odds: in MCP's case, they're both not that great (yet). MCP is a protocol by developers, for developers. Let's review the steps to connect a third-party MCP server (assuming you aren't writing one yourself):
Find an MCP repository that you like
Download or clone the code locally
Install the required prerequisites, often using poetry or npx
Configure the server within the MCP client
And if any of this goes sideways, parse through dense logs or install a separate Node.js tool to try and inspect the implementation
If you're not already a programmer, there's no way you're getting to the end of this process without a ton of learning on the fly. And while a low-code (or even no-code) registry would be great, I'd also consider drawing from another existing piece of developer infrastructure: package managers.
Today, most popular software ecosystems support third-party libraries: this includes languages like Python and JavaScript, as well as operating systems Linux and MacOS. The services that make installing these libraries easy are package managers - they provide a simple, standardized way to discover and install new packages.
As a developer, you kind of take good package managers for granted: there's a shared understanding of where new packages will be registered, and you (generally) assume that when you find useful ecosystem libraries, you can install them via a package manager. However, most package managers are considered "boring" - there (usually) isn't much interest in becoming a package manager. In MCP's case, there's so much hype that multiple startups are actively competing to be the package manager for the standard5.
For something less technical, Apple's App Store is the obvious comparison. But it's worth noting that it takes meaningful resources to keep quality high and barriers to entry low: Apple's App Store only works because Apple 1) maintains non-zero barriers to entry and 2) regularly checks for low effort or malicious apps6.
Discoverability
The last main issue I see with MCPs is how difficult it is to find new ones. Right now you have to hang out on Twitter, the MCP subreddit, or browse trending GitHub repos.
It reminds me a lot of Docker. In its early days, Docker was hot stuff in the DevOps community. And even though containers were really only useful for large companies, many smaller startups wanted to get in on the action. The problem was that the developer experience for setting up Docker was a bit of a nightmare - it was designed to be run on Unix servers, so the individual desktop implementations were often buggy or nonexistent.

There was also not a great way of discovering new Docker instances - your company would create a container and share it internally, but you had to go out of your way to find other people's containers. Ultimately, Docker overcame most of these UX issues, and became an essential part of the modern development stack. MCPs could follow a similar trajectory, but the growing pains are real.
Between usability and discoverability, Anthropic likely needs to be the one to fill these gaps with an official MCP registry (which they have plans to do). However, this potentially flies in the face of MCP being a neutral, open standard7.
Despite these drawbacks, the MCP developers are actively working to address them. There's a public roadmap for future updates to the protocol, and quite a lot of discussion on the MCP GitHub repo as the specification continues to evolve.
The pace of updates suggests that the MCP ecosystem (not to mention the core spec) is maturing rapidly. The real question, though, is whether it can navigate these challenges quickly enough to maintain its momentum.
Why MCPs are (Probably) Going to Win
The MCP ecosystem isn't perfect - far from it. But despite its flaws, I believe it's positioned to become the dominant standard for AI agent connectivity.
First, the protocol is an "open standard," meaning it's meant to be adopted widely and not force any particular vendor or tool lock-in. MCP draws heavily from Microsoft's Language Server Protocol (LSP), which lets coding extensions work across any IDE that supports the protocol. Likewise, MCP is trying to make it so that app developers only ever have to worry about a single implementation: their MCP-compatible server.
What also helps is that it has a very detailed, very thoughtful spec. The authors have clearly tested this out themselves and are aware of its shortcomings - this isn't a half-baked standard thrown over the wall, but something built with real-world usage in mind. The roadmap has also clearly shifted in response to community feedback - so the protocol can evolve based on real-world needs.
And it's a standard being championed by Anthropic, which matters for a couple of reasons. It's a major player in the space, implying support won't die out overnight (similar to Facebook and React). Plus, Anthropic has arguably more developer mindshare and less scrutiny than OpenAI/Google - they can focus on building the protocol rather than constantly fending off controversies or managing multiple product lines.
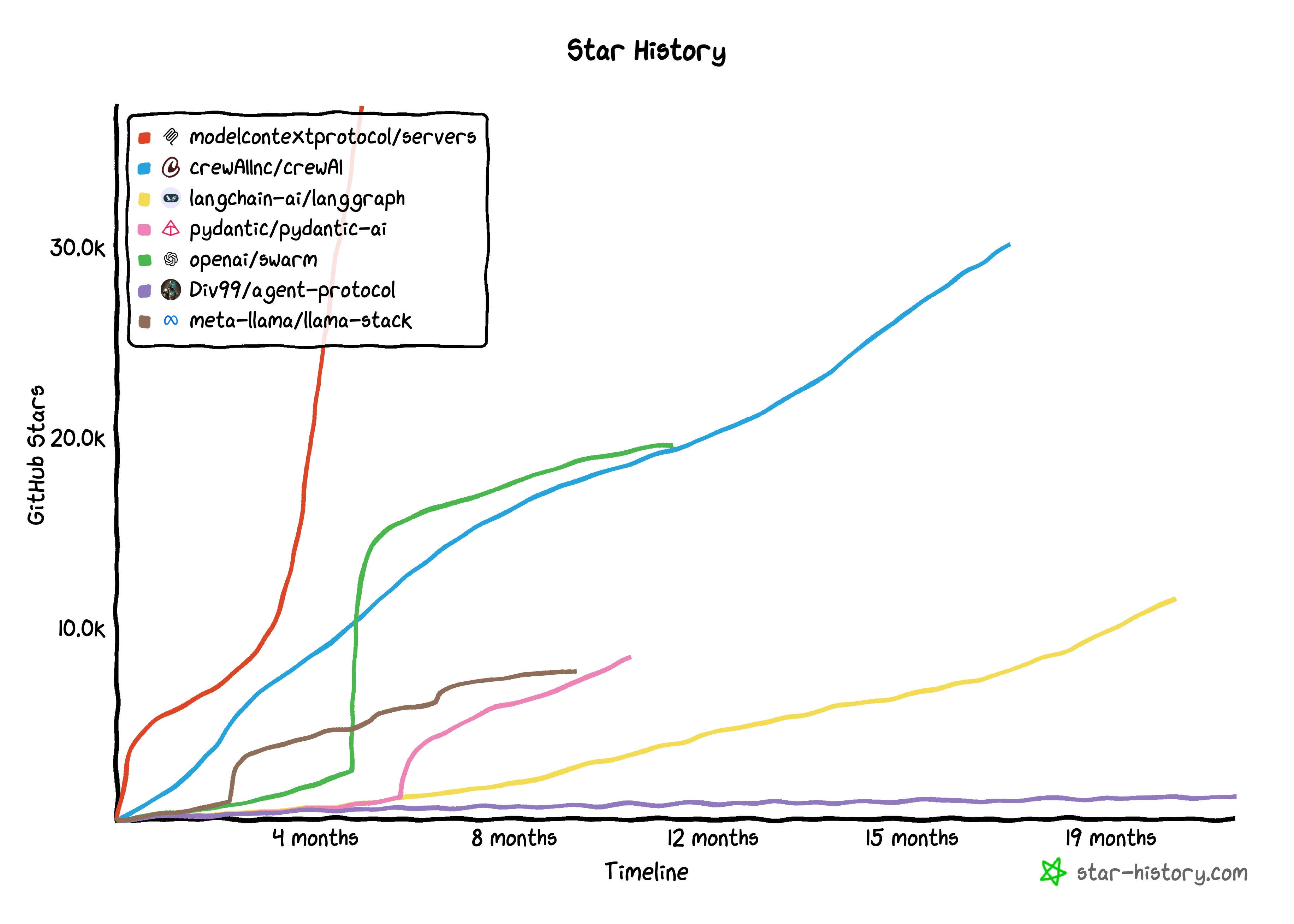
Second, there's undeniable community momentum. Clearly the protocol has found PMF (protocol market fit) - that magical state where developers actually want to use something rather than being forced to. If we look at the GitHub star growth, it's impressive, but what's more interesting is that it didn't happen immediately at launch. It was released in November 2024, but didn't really "take off" right away, which suggests the growth is organic rather than just hype-driven.
This momentum is also visible in the number of third-party servers out there. Since there isn't an official registry, it's difficult to know the exact number of servers, but we can find proxies to look at the growth rate. Between February and April, Pulse (an MCP directory) went from 1,081 to 3,837 listed servers, a 255% jump. Smithery, another registry, had an even bigger jump in that same time period - over a 400% increase, from 942 to 4,754 servers.
Within the developer ecosystem, MCP support is becoming table stakes for any new coding IDEs such as Cursor or Windsurf. Anecdotally, I stumble across new MCP servers and tools in the MCP subreddit nearly every day. The ecosystem is expanding rapidly, which creates a flywheel effect—more servers mean more utility, which drives more adoption.
Finally, there's competitor recognition. At this point, MCP is too big to ignore, even for the biggest players in AI. Last month, OpenAI said they would support MCP in their Agents SDK - a significant acknowledgment from the industry leader. Google did as well, though that didn't stop them from proposing their own agentic protocol.
Right now, competitor buy-in could be merely lip service - companies saying "sure, we'll support that" without real commitment. But if MCPs continue gaining significant traction, it'll be harder for ChatGPT and Gemini to compete from the outside - especially for developer-oriented use cases. The risk of being left behind will eventually outweigh the benefits of maintaining proprietary standards.
When you combine these factors - a thoughtful open standard, genuine community momentum, and growing recognition from even the biggest competitors - you get a technology positioned to become the de facto way AI agents connect to the outside world. It's not guaranteed, and obstacles are still to overcome, but MCP has what it needs to break through - it just has to stick the landing.
Beyond Text Boxes: AI's New Operating System
Much like how TCP/IP became the invisible backbone of the internet or REST APIs standardized web service communication, MCPs are positioned to become the connective tissue that allows AI systems to interact with the digital world around them.
I've said before that LLMs are like engines - they're incredibly powerful but still require a chassis, wheels, and axles to actually provide value. MCPs are a step towards inventing these "wheels and axles" - the components that translate raw computational power into practical utility. They're not the entire vehicle but a crucial part of the overall system that makes the vehicle functional.
Andrej Karpathy has discussed the idea of a new type of OS with LLMs at the center rather than traditional CPUs. In this framework, the LLM has connections to other components, like software 1.0 tools (i.e. calculators, terminals) as well as the browser/external web APIs. MCPs bring that vision closer to reality by giving these AI "operating systems" standardized ways to interact with the world around them.

Personally, I'm also excited about what this unlocks for users, especially those who are willing to tinker with their AI implementations. There's so much context I wish ChatGPT and Claude could have, but there's still so much friction in giving it to them. By letting AI systems seamlessly fetch data and take action on our digital tools and services, the tyranny of copy-paste begins to dissolve. The cognitive overhead of context-switching decreases. The friction between having an idea and executing gets even lower.
Are MCPs perfect? Certainly not. As we've discussed, serious security, usability, and discovery concerns need to be addressed. But the trajectory is promising, and the energy around solving these problems suggests they won't remain blockers forever.
I'm guessing we'll look back on this period as a major inflection point - when AI systems began to break free of their text boxes and truly integrate with the digital world around them. Not through proprietary, walled-garden approaches, but through an open standard that allows for innovation at every level of the AI stack.
If you’re interested in learning more about building with LLMs, I’m working on an AI engineering course, and I want your feedback to help tailor the content. Sign up for updates here.
OpenAI's function-calling API essentially became the standardized interface for the industry.
Astute technologists will note that this sounds suspiciously like RPC (remote procedure call), and that's because it *is* like RPC. What's old is new, etc etc. One key difference here though is that previous implementations of RPC were still deterministic - with MCPs, the model or agent can decide on the fly which resources it needs to use.
In practice, though, most of the examples I've seen tend to focus on tools, and to a lesser extent resources.
If you’re interested in setting up an MCP server, stay tuned - I’m working on a tutorial for that.
This isn’t great, IMO: it then creates misaligned incentives and potential headaches.
Yes, indie developers absolutely get hamstrung as collateral damage, but Apple's policies are what keep the App Store high quality (or at least much higher quality than it would be without the existing policies).
The middle ground here is likely to spin out MCP as a separate foundation and organization which can manage the ecosystem without being directly tied to Anthropic. This would preserve the openness of the standard while providing needed governance and curation.
Clearly the protocol has found PMF (protocol market fit) - that magical state where developers actually want to use something rather than being forced to
Great write up @Charlie Guo … but on the PMF as winning part, I dont know man.
I think we should all be cautious about interpreting excitement (which is what GH stars is) with AI and AI tools. Especially in the last 12-24months - there has been a influx of tinkers, who may not particularly be system builders. Its one thing to have 1000s of devs installing mcp servers in cursor. Its another to have a scalable protocol that becomes the fiber for systems built in the wild.
Time will tell I guess.
Overall, nice article
The MCP discussion really resonates with my experience in the e-commerce integration world! That "tyranny of copy-paste" perfectly describes what we've been dealing with when connecting systems - whether it's product data flowing between platforms or trying to make AI actually useful in existing workflows.
What excites me most about the MCP approach is how it solves the exact problem I've seen with every digital transformation project: getting systems to talk to each other WITHOUT endless custom integrations. I've been experimenting with Claude Desktop's MCP capabilities for processing e-commerce data files, and while it's definitely developer-focused right now, the potential is massive. I just explored this same pattern in my latest piece on creating specialized digital solutions that don't require massive development resources: https://thoughts.jock.pl/p/build-internal-digital-solutions-fast-no-coding-required