

Revisiting "Intelligence Drift"
Why AI models still feel like they're getting dumber

Last year, I wrote about a strange phenomenon - the anecdotal but widespread experience of LLMs seeming great at first, then getting progressively “dumber” over time. With models like GPT-4 and Claude 3.5 Sonnet, users reported worse answers, incomplete responses, and outright refusals to work.

In that post, I explored several different theories as to why, but I couldn’t land on a satisfying explanation. Neither could anyone else.
Since then, I’ve started calling this phenomenon “intelligence drift” - a term that captures the user experience regardless of underlying cause. Whether it’s cutting corners, model limitations, or seasonal laziness, users experience the same thing: AI that feels less intelligent over time.
Because people are still complaining, and we still don’t have any clear, obvious answers - though that’s beginning to change.
People Are Still Complaining About LLMs Getting Dumber
When I checked back in on whether people were satisfied with the latest models, I was surprised to find that the complaints haven’t really stopped. If anything, they’ve intensified as more people rely on these tools for critical work.
From the last few months alone, via Reddit/Hacker News:
”I’m getting worse output from Claude than I was two years ago. This is not an exaggeration.”
“Claude used to be a powerhouse. Fast forward to today, and it feels like you’re talking to a broken algorithm afraid of its own shadow.”
“Claude Code HAS gotten worse - Here Is the Proof”

The pattern echoes exactly what I wrote about last year. Users report that tasks which worked reliably months ago now fail, that responses feel more generic, and that models seem to “forget” context mid-conversation. Moreover, these reports come from power users - developers, writers, and researchers - who use these tools daily and notice subtle degradation.
So what’s changed since my last post? Have we made any progress in understanding what’s actually happening?
What Happened to the Old Theories?
Before diving into new evidence, let’s recap the old theories:
The cost-cutting theory suggested that companies were intentionally degrading models to save on compute costs - essentially “quantizing” or compressing models to run cheaper inference. This theory was always cynical, and Anthropic’s recent transparency (more on this shortly) somewhat disproves it.
The winter break theory - that GPT-4 learned to be lazy during holiday months because it ingested internet content about seasonal slacking - remains unfalsifiable and delightful. We still can’t rule it out entirely, which tells you something about how little we understand these systems.
The stale training data theory proposed that models perform well initially because they have “fresh” knowledge cutoffs, but degrade as they encounter scenarios further from their training distribution. This theory still lacks clear evidence, though “model collapse” (see below) provides a more specific and concerning mechanism for long-term degradation.
The post-training theory suggested that companies weren’t technically lying about “not changing the model” because they only promised not to do additional pre-training, leaving the door open for continuous post-training adjustments that could change behavior. This remains plausible, and if anything, will likely become more believable as we move away from fixed model versions and towards “personalities” that are continuously updated.
The “it’s all in your head” theory argued that users experience confirmation bias and adaptation effects, becoming desensitized to AI capabilities while also discovering edge cases through increased usage. In my view, the theory is partially vindicated (confirmation bias is indeed real), but Anthropic’s recent data also reveal real degradation issues, not just perception problems. The truth, as usual, lies somewhere in between - some complaints reflect real issues, others reflect changing expectations and selective memory.
AI companies, predictably, continue to deny making any changes. Frontier labs are insisting that each model is more intelligent than the last, and they publish their system prompts and system cards in the name of transparency.
Until last month, when Anthropic published a technical postmortem revealing three overlapping bugs that caused meaningful performance issues for Claude. If you enjoy geeking out over low-level AI implementations as much as I do, then by all means give it a read. However, the key takeaway is that many things can go awry between having a fully finished model and successfully hosting it as a software service.

Three New Theories
The “infrastructure issues” theory
One point I didn’t touch on in my original post is how we often hand-wave away “inference” as essentially a solved problem. Training gets all the attention - the dramatic compute requirements, the data pipeline challenges, the scaling laws. But inference - how hard could that be?
In truth, serving LLMs at scale is unprecedented in its complexity. OpenAI, Anthropic, Google, and others are dealing with arduous system design challenges: routing millions of requests across heterogeneous hardware platforms (NVIDIA/AMD GPUs, Google TPUs, AWS/Oracle/Coreweave clusters), maintaining strict quality equivalence across different chips, handling requests that might take 100ms or 30 seconds, all while load-balancing globally.
And perhaps unsurprisingly, traditional software bugs - the “dumb” infrastructure problems that have nothing to do with model training or intelligence - can absolutely degrade perceived model quality. In Anthropic’s postmortem, two of the issues they ran into were classic configuration problems:
A minor routing bug on August 5th, where less than 1% of requests were mis-routed to the wrong servers. But on August 29th, a routine load balancing change amplified the error dramatically, eventually impacting up to 16% of requests. Worse, the routing system was “sticky” - once your request hit the wrong server pool, subsequent requests would continue to go to the same broken servers.
A TPU misconfiguration was even stranger. Starting August 25th, a bad performance optimization began driving text generation haywire. For example, users asking questions in English would suddenly see random Thai or Chinese characters appear mid-response. It affected multiple Claude models for a few weeks, producing bizarre outputs that resembled model insanity.
These weren’t core ML problems. They were infrastructure problems. And yet the user experience was indistinguishable from the model “getting dumber.” The postmortem was refreshingly honest: “We fell short of our standards.” But it also underscores just how hard this problem is.
The “implementation issues” theory
The third issue in Anthropic’s postmortem was a latent bug deep in the hardware/software stack that nobody knew existed, until an innocent code change triggered it.
Last December, Anthropic engineers patched a bug related to how Claude’s AI model calculated token probabilities1. The patch was meant to be a temporary workaround, and in August, they rewrote the code to get rid of the workaround entirely. Except that “fix” exposed a deeper bug in the low-level software that the TPUs run on.
The bug was maddeningly inconsistent:
It changed depending on unrelated factors such as what operations ran before or after it, and whether debugging tools were enabled. The same prompt might work perfectly on one request and fail on the next.
For years, we’ve known how challenging ML implementations can be. Teams routinely discover dramatic improvements after finding long-hidden bugs. The move to specialized AI hardware (TPUs, custom ASICs) multiplies these opportunities for bugs. Every new hardware platform means new compilers, new optimization passes, and new places for subtle issues.
And unlike configuration bugs, these are nearly impossible to detect with standard evaluation. The model’s capability hasn’t changed - it’s the same weights, the same architecture. However, the execution is ever so slightly flawed, causing intermittent degradation that appears to be intelligence drift.
The “context rot” theory
But there’s one other new theory that isn’t touched on in Anthropic’s postmortem: context rot.
In 2024, researchers at Chroma published research on “context rot“ - a phenomenon where LLM performance degrades as input context length increases. They tested 18 state-of-the-art models including GPT-4.1, Claude 4, and Gemini 2.5, and found something unsettling: model performance drops from around 95% accuracy on short inputs to 60-70% on longer contexts, even when the additional content is semantically relevant.
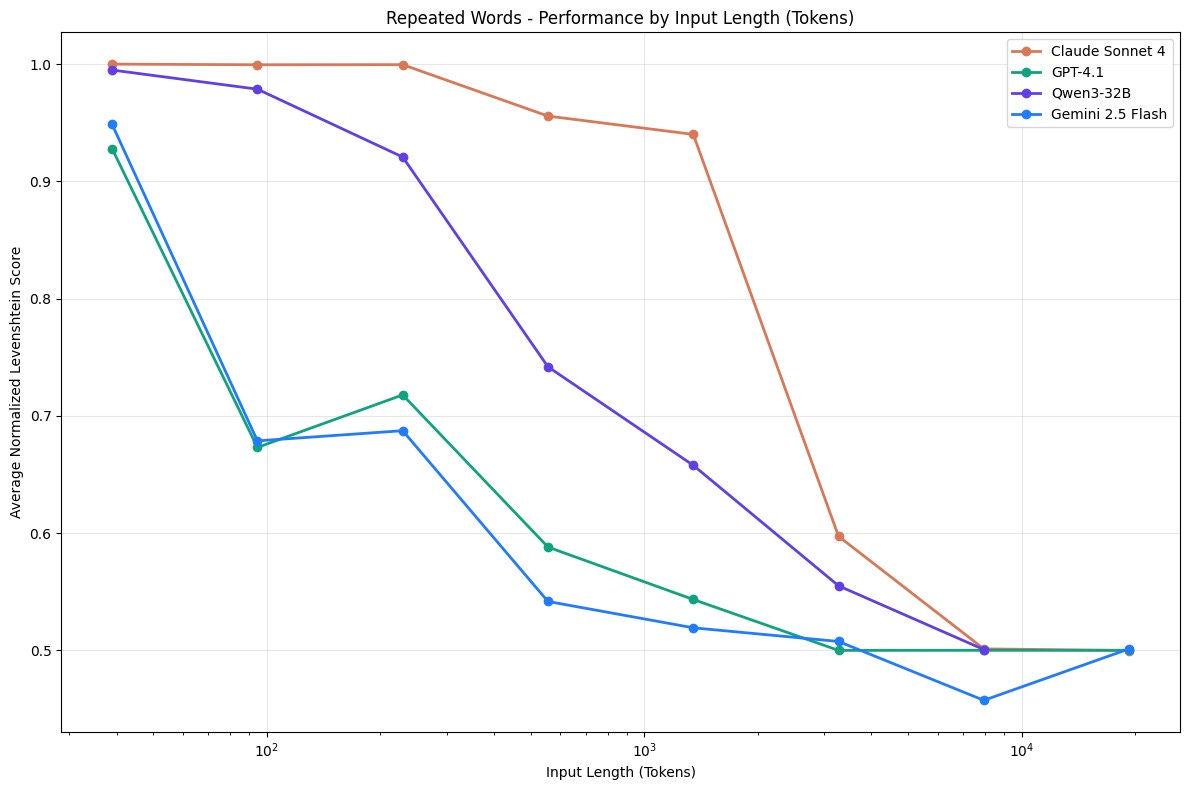
This is decidedly different than hitting token limits, as the tests stayed well within models’ advertised context windows. The problem is more fundamental: models don’t treat all tokens equally. Performance degrades unevenly as context grows, with different failure modes emerging - the tenth token isn’t processed with the same fidelity as the ten thousandth.
Modern chatbots, such as ChatGPT and Claude, are continually expanding the context window to include user memories, recent chat history, project context, custom instructions, and more. For power users who accumulate dozens of memories and maintain long-running conversations, the amount of “stuff” being injected into every request grows steadily.

Could it be that we’re collectively hitting a model tipping point where context bloat degrades performance? This would explain why intelligence drift feels inconsistent - it would vary based on how much context each user has accumulated. The power users complaining loudest would be exactly the ones hitting degradation thresholds first.
The timing aligns suspiciously well with complaints. As platforms add features like persistent memory and multi-file analysis, they’re unknowingly pushing more users toward the context rot cliff. What feels like the model getting dumber might actually be the model drowning in context.
The Threat of Model Collapse
So where does this leave us? Intelligence drift is real, multifaceted, and probably inevitable. And that reality challenges a popular narrative in AI: “This is the worst the technology will ever be.”
That phrase has become a mantra - every time someone complains about AI limitations, someone else responds that these systems only improve, that next year’s models will be better, that we’re on an inevitable upward trajectory. But what if that’s not true? What if, as these systems become more complex, serve more users, and face more constraints, some forms of degradation are simply unavoidable?
The good news is that we’re working on solutions to many of these problems. Automatically compacting context windows can help mitigate context rot; more sensitive evaluations can aid in detecting subtly broken infrastructure more quickly. And Anthropic should be commended for their remarkably transparent postmortem, so the field as a whole can improve.
But in the long term, we may face a more fundamental threat: model collapse.
Model collapse occurs when generative AI models are trained on outputs from previous AI models, either intentionally (synthetic data) or unintentionally (internet AI slop). Research published in Nature showed “irreversible defects,” where the tails of content distribution disappear. Models lose diversity, rare concepts vanish, and outputs converge toward bland, repetitive patterns. Broadly speaking, it’s akin to making a photocopy of a photocopy of a photocopy.
And the problem appears to be accelerating. Accoding to one analysis, over 74% of newly created webpages contained AI-generated text as of this past April. As this synthetic content gets scraped into future training runs, each generation of models learns from an increasingly polluted data pool. The rich diversity of human expression that made GPT-3 and GPT-4 possible may not be available for GPT-7 or GPT-8.
Infrastructure bugs can be fixed. Context rot can be managed. But model collapse represents a tragedy of the commons - each AI-generated piece of content is individually cheap and easy to produce, but collectively, they poison the data ecosystem that all future models depend on.
There are some solutions, but they are neither cheap nor easy: tracking data provenance, preserving pre-AI archives of human content, curating training sets more carefully, mixing synthetic and real data thoughtfully. The path of least resistance (and lowest costs) leads towards AI models regurgitating AI content, over and over again.

Living with Intelligence Drift
Ultimately, I think the term “intelligence drift” gives us language for all these issues - from transient infrastructure bugs to existential data pollution. The user experience is the same regardless of cause: AI that feels dumber as time goes on.
And sadly, the mystery of intelligence drift isn’t solved. If anything, it’s expanded - we went from “we don’t know why” to “it’s between three and six different things happening simultaneously.”
But that’s actually progress! Problems with names can be studied, measured, and (sometimes) fixed.
The harder question is whether or not we’re building on stable foundations. Traditional software is reliable because it’s deterministic and composable. But LLMs are different. They’re non-deterministic, their behavior emerges from billions of parameters, and we use them via unprecedented infrastructure complexity. Add context rot, model collapse, and the brittleness of floating-point precision across specialized hardware, and you get systems that might be inherently unstable.
Anthropic co-founder Jack Clark recently talked about the future of AI progress, and how he uses the term “growing” instead of “making”:
This technology really is more akin to something grown than something made - you combine the right initial conditions and you stick a scaffold in the ground and out grows something of complexity you could not have possibly hoped to design yourself.
So maybe we’re approaching this from the wrong angle. Maybe instead of expecting AI to function like a sterile, lifeless tool, we should treat it more like a garden - something that requires constant monitoring, graceful degradation, and hedging strategies.
Maybe the future isn’t “AI you can trust” but “AI you can grow.”
That bug was a classic floating point precision issue: the model calculated word probabilities in 16-bit floating point (bf16) because that’s memory-efficient. But the TPU compiler, trying to be helpful, automatically converted some operations to 32-bit (fp32) for better accuracy. Different parts of the system started disagreeing on which word had the highest probability - sometimes dropping the best candidate entirely.
LLMs can be made to be deterministic though, I wonder if this will be more popular in the future.
However in most cases, my AI collaborate in an effective way (ChatGPT, LeChat…)