

Llama 4 is a technical triumph and a strategic stumble
How Meta's messy launch overshadowed its latest flagship model.

Meta's Llama 4 launch should have been a triumphant moment for open-weight AI. Instead, it's become a showcase of how technical excellence can be undermined by rushed execution and communication missteps (and why taking shortcuts may be the natural response to increasing competitive pressures).
In the days since Meta (unexpectedly) released its newest AI model family over the weekend, the company's narrative has been at odds with the community's reception. On the one hand, the technical specifications seem solid: native multimodality, massive context windows, and a sophisticated mixture of experts architecture that ostensibly puts Meta back at the forefront of open-weight AI.
On the other hand, confusion over benchmarks, limited availability of advertised features, and questions about the timing have cast a shadow over what should have been a defining AI moment of 2025.
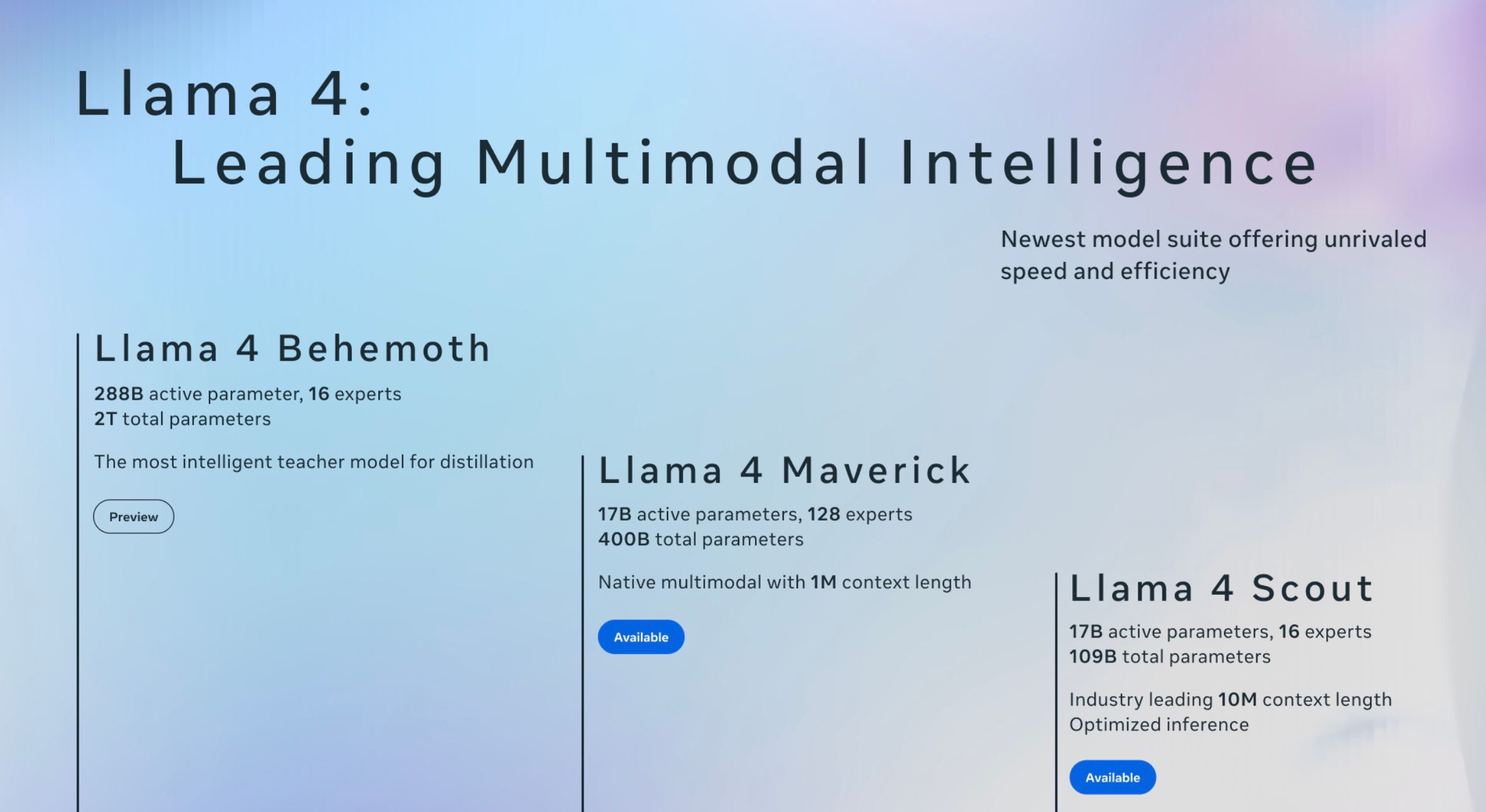
Meet Llama 4
Llama 4 is not just a model but a family: Scout, Maverick, and an unreleased model named Behemoth. All three are natively multimodal, with Meta describing their training process as "early fusion" – meaning they're jointly trained on text, images, and video from the beginning rather than having these capabilities bolted on later.
The models also come with impressively large context windows. Positioned as the smallest/fastest/cheapest option, Scout boasts a 10M token context window - the next closest option is Gemini 2.0 with a 2M context window. This means the model can theoretically "remember" and process the equivalent of thousands of pages in a single conversation – a dramatic leap forward for applications that handle complex, lengthy inputs.
True to its name, Behemoth weighs in at a whopping 2 trillion parameters. If and when it's released, it'll be the largest open-weight model available by a considerable margin1. It’s also been used to help train the smaller models through a process known as “distillation,” where a larger model helps "teach" a smaller one - a pattern we've seen elsewhere from companies like OpenAI.
A mixture of architectures
The Llama 4 models use a mixture of experts (MoE) architecture, an approach where the model internally creates several "experts" that perform better at different tasks. Scout and Behemoth each have 16 experts, while Maverick has a remarkable 128.
Each expert represents a fraction of the overall model size and works alongside different layers that act as routers – picking the expert best suited for a given input. It's an experimental approach that works reasonably well, though with plenty of caveats2.
What's particularly interesting is that these models appear built for substantially different use cases. It's not as straightforward as taking a single architecture and simply scaling it up. I appreciated Nate Lambert's summary:
Llama 4 Scout resembles a Gemini Flash model or any ultra-efficient inference MoE.
Llama 4 Maverick’s architecture is similar to DeepSeek V3, with extreme sparsity and many active experts.
Llama 4 Behemoth is likely similar to Claude Opus or Gemini Ultra, but we don’t have much information to make a real comparison.
The divergent designs suggest Meta is positioning these models to address different market segments rather than creating a simple good-better-best lineup.
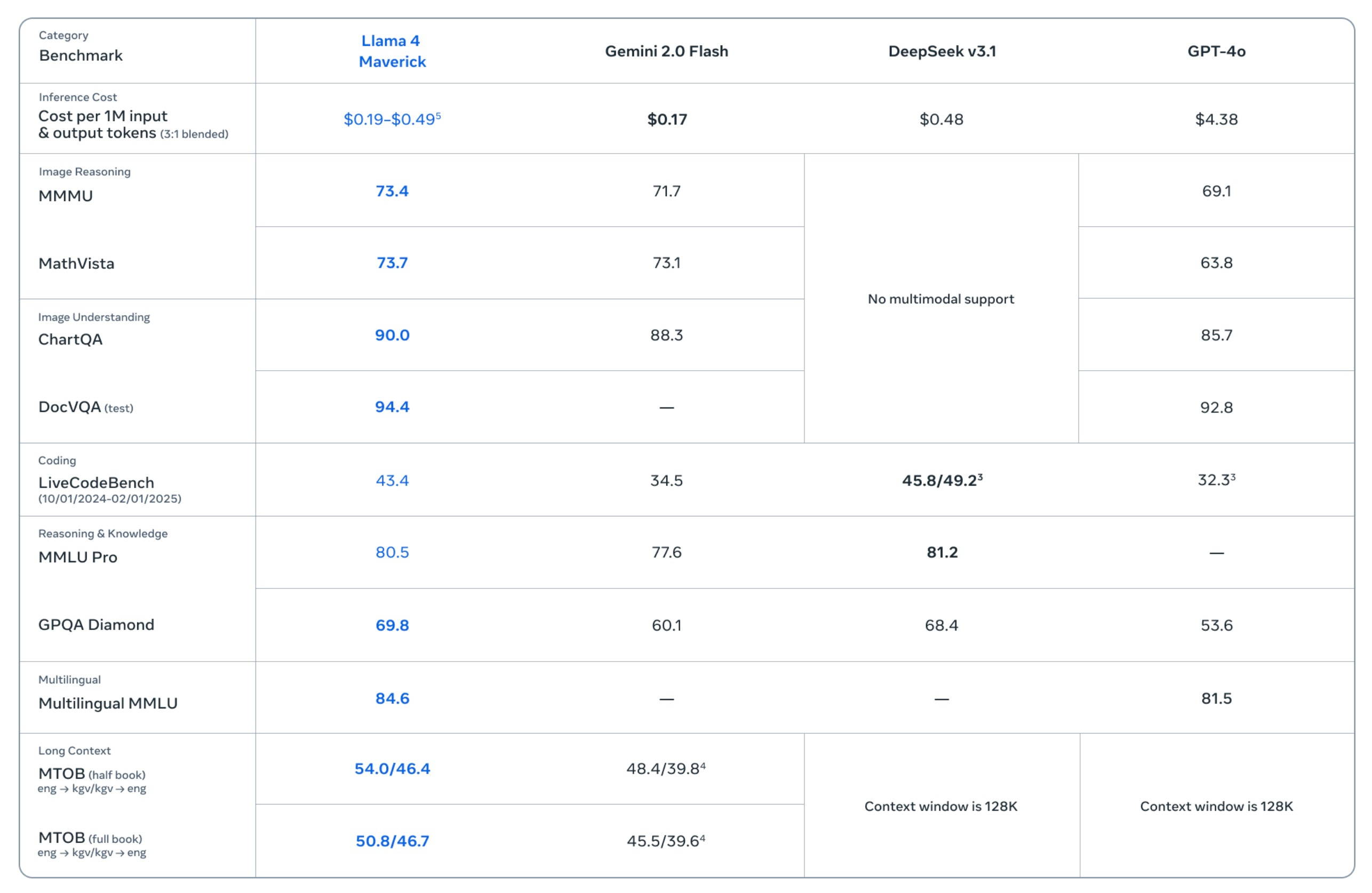
Benchmarks and blunders
Benchmark-wise, the reported numbers look great for a new open weight model. Maverick (the mid-size) allegedly beats Gemini 2.0 Flash and GPT-4o across various image, reasoning, and long-context benchmarks. Meanwhile, Behemoth (again, still unreleased) reportedly outperforms Claude 3.7 Sonnet and GPT-4.5 on multilingual, reasoning, and coding tests.
And indeed, shortly after launch, Llama 4 rocketed to the number two spot in the LMSYS Arena leaderboards, sitting only behind Google's Gemini 2.5 Pro. But that's where the problems started.
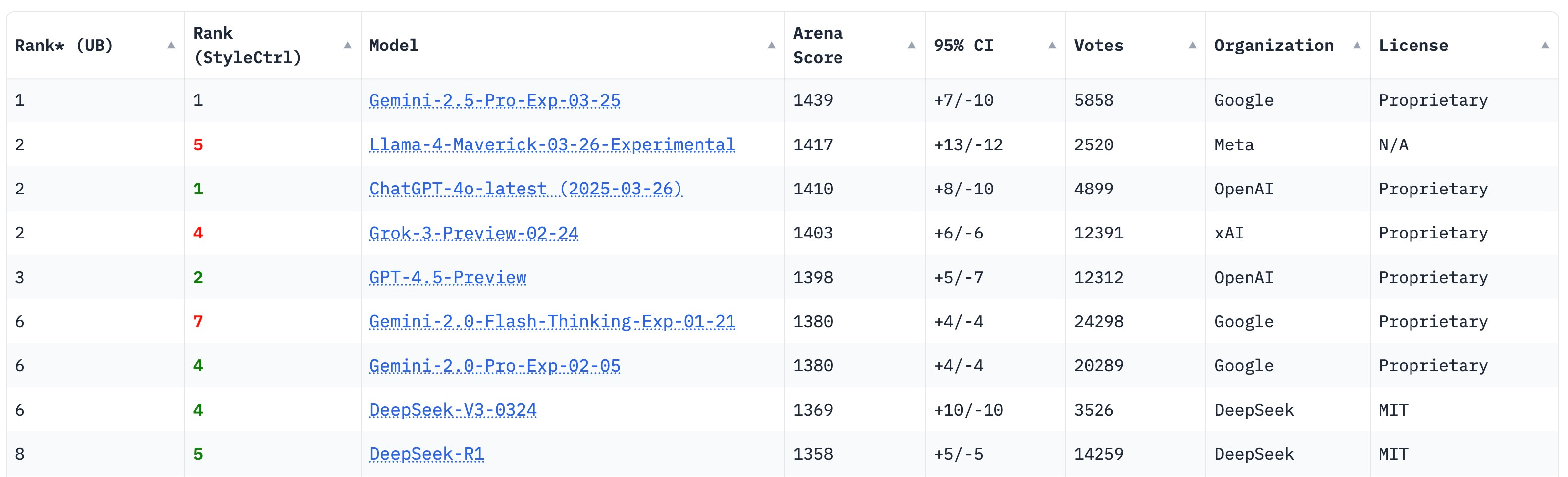
In the aftermath of the launch, several AI researchers noticed Meta's disclosure that the LMArena version wasn't exactly the same version being released more broadly – instead, it was an "experimental chat version" that's "optimized for conversationality."
Understandably, plenty of folks found this somewhat misleading3. With how much attention is paid to these leaderboards, what good is a high score if the model isn’t broadly available? More importantly, it calls into question what model developers might be hiding if they have to release a separate version for the LMArena – is the base model not actually suitable for real-world tasks?
Users have already started noticing differences in the model's behavior on LMArena versus in the wild, with some reporting significant performance disparities. Though interestingly, the base models seem better at real-world tasks, with the chat-optimized version being prone to rambling and emoji use.
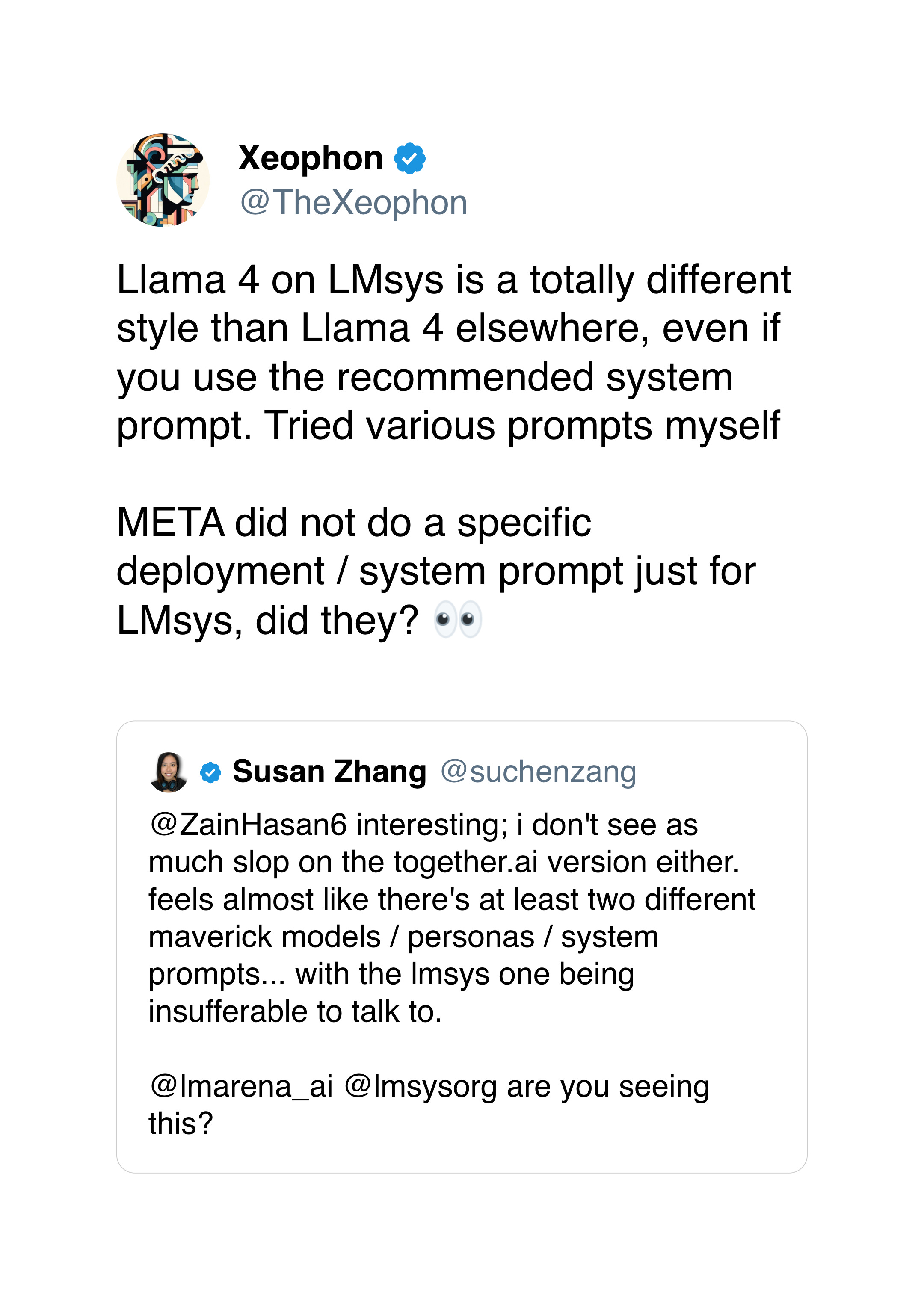
But there are also some differences in third-party implementations – as far as I can tell, no existing hosted versions have the 10M (or even 1M) context window available. Groq and Fireworks have implemented a 128K limit, while Together.ai offers a 328K context window – nowhere near the headline figures touted in the launch announcements.
Indeed, Meta's VP of generative AI has acknowledged some of these issues, stating: "Since we dropped the models as soon as they were ready, we expect it'll take several days for all the public implementations to get dialed in."
The timing of the release itself also raises questions. Launching Llama 4 over the weekend caught many AI researchers and experts off guard – this should have theoretically been one of Meta's biggest technical launches of the year, and was widely expected to happen at LlamaCon later this month. Instead, it arrived with minimal fanfare and maximum confusion.
To be fair to Meta, I assume that third-party model providers will eventually iron out the kinks and have the models fully up and running. And we don’t know what’s still in store for LlamaCon.
But all of the above seems like a series of strange, unforced errors that have undermined what should have been a genuinely strong launch.

Arms race artifacts
What's worse, all of this opens up Meta to unsubstantiated rumors. One post, supposedly coming from a Chinese whistleblower on the Llama 4 team, claims that Meta simply cheated on the benchmarks by training on the test sets.
Meta's VP of generative AI has unequivocally denied this, but again – a denial wouldn't be necessary in the first place if the model performance spoke for itself, without all of the benchmark shenanigans.
Again, to quote Nathan Lambert:
Sadly this post is barely about the technical details. Meta nuked their release vibes with weird timing and by having an off-putting chatty model that was easiest to find to talk to. The release process, timing, and big picture raise more questions for Meta. Did they panic and feel like this was their one shot at being state of the art?
Perhaps it's pessimistic, but this strikes me as a natural consequence of the continually increasing pressure on frontier labs. Meta in particular faces threats not just from proprietary labs like OpenAI and Google DeepMind, but its "open" crown is now under threat from Chinese competitors like DeepSeek.
To be clear, I don't think Meta did or would outright cheat on benchmarks – it's not a secret that can stay hidden for too long, and it risks squandering compute, alienating researchers, and torching an otherwise good reputation in the AI community.
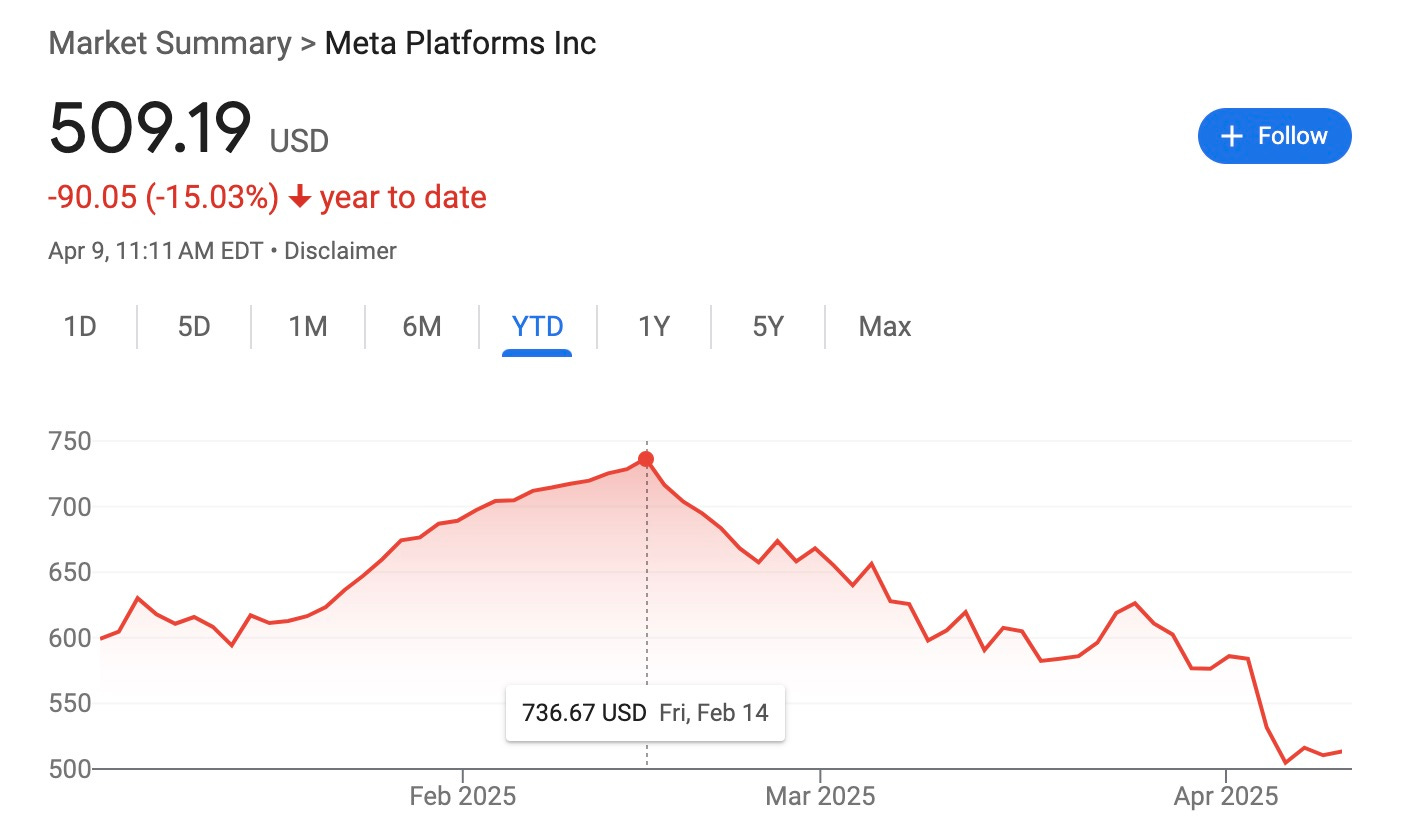
But as tech stocks get hammered ($META is already down around 30% from its February peak) and we appear to be entering a period of global financial instability, it will likely become more difficult to justify the cost of these releases without a clear business model. The pressure to show immediate results – both technical and financial – may well be influencing release strategies in ways that don't serve long-term trust in the field.
Reading tea leaves
Ultimately, I don't think we should be putting too much stock in a single release - that's how you end up with "it's so over" / "we're so back" whiplash. But the coming weeks will likely show whether Llama 4 was a bump in the road, or a sign of something deeper.
With LlamaCon just around the corner, it's entirely possible that Meta releases something that blows Llama 4 out of the water. And as implementations mature and the full capabilities of these models become accessible, the AI community may well forgive the initial confusion. It's worth remembering that Llama 3 was first released last April to moderate fanfare but got increasingly better over the following six months, with the 3.1, 3.2, and 3.3 releases.

And yet, Meta's real test isn't benchmarks, but finding ways to continuously stay ahead of the competition in a landscape that continues to be as cutthroat as ever. With Chinese alternatives advancing rapidly, closed-source leaders like OpenAI and Anthropic securing massive investments, and the economics of frontier model development growing ever more challenging, Meta's stumbles with Llama 4 might be part of a larger trend.
For now, Llama 4 remains a technically impressive suite of models shadowed by a problematic introduction – a cautionary tale of how even the most sophisticated AI can be undermined by all-too-human factors in its deployment.
Some have estimated that OpenAI's models have made it into the trillions of parameters, but we don't have any concrete evidence. The closest alternative would be DeepSeek's R1, which has 671B parameters. But of course, these are mostly vanity metrics – what really matters is performance.
Of course, each "expert" isn't like a sub-LLM that's amazing at math or coding – I sometimes see the architecture described as "8 LLMs in a trenchcoat." Rather, they're clusters within the massive neural network that wind up better at disparate, sometimes esoteric inputs.
LMArena itself stated that it was unhappy about "Meta's interpretation" of its policy, and it would be updating policies to avoid this type of confusion in the future.