


Why the latest Llama is making waves
Why the latest Llama is making waves
A look at Meta's cutting-edge AI offering.

Meta's new LLM, Llama 2, landed yesterday. It’s already making headlines, but… why? Isn’t it just another open-source release?
Let's dive into its features, potential impact, and why it's a big deal.

What is Llama 2?
Llama 2 is a brand-new open-source large language model. Technically, it's several models with different parameter sizes: 7B, 13B, 34B, and 70B, as well as a chatbot variant. It (they) was trained on 40% more data than Llama 1 (2 trillion tokens) and has double the context length (4096 tokens).
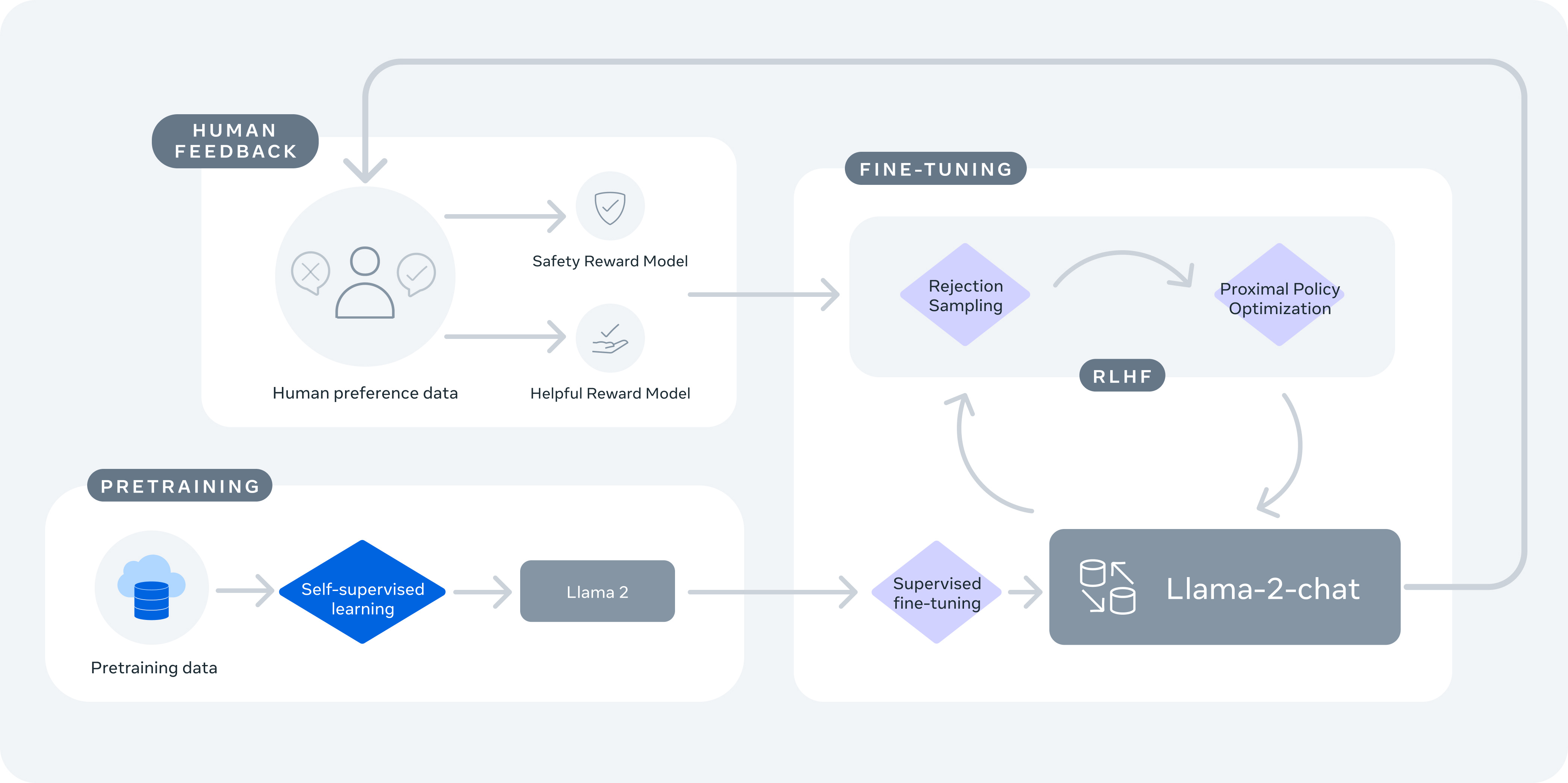
In addition to the basic training, the Llama 2 chat model has undergone supervised fine-tuning and RLHF. The process involves human feedback and reward models measuring helpfulness and safety. Initial estimates place the cost of building and training Llama 2 at north of $20 million.
For a more in-depth look at the technical details and implementation of Llama 2, check out this great post by
at .Why does it matter?
First and foremost, this is now the most advanced open-source large language model that's widely usable. The biggest barrier to adoption for Llama 1 was its license - using it commercially was a legal gray area. Llama 2, though, is licensed for commercial use1.
That means companies can now use Llama 2 freely, and many will likely contribute back to the original model. So while it may not be quite as good as closed-source models (see the benchmarks below), it can improve much faster with the help of the open-source community.
It also means an explosion of spinoffs and descendant models trained and modified for different use cases. Llama 1, for reference, was the research model released in March of this year. The model was licensed for research purposes only, but was quickly leaked to 4chan and became the foundation for many alternative models.

All of this, of course, boosts Meta's position as the champion of open-source AI models. In stark contrast to OpenAI, Meta has published an in-depth whitepaper covering the training process and the RLHF process they used. It includes the model details, training stages, hardware, data pipeline, and annotation process. Here's a link to the full paper. To my knowledge, this is the first time a research paper is detailing the RLHF process with this level of transparency, which gives teams a much better chance of replicating it.
That said, Meta made a huge effort to promote AI safety in this release. Some of the ways Meta is balancing safety with availability in this release:
The whitepaper covers safety guardrails, red-teaming, and evaluations. It's nearly half of the paper!
While releasing all of the language model weights, they are holding off on open-sourcing the reward models used to measure helpfulness and safety.
Downloading the model is a managed workflow (unlike the chaos of the Llama 1 leak) that attempts to do a basic KYC check on
Providing a safety-oriented system prompt for the chat variant out of the box.
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
– Llama 2’s system prompt
How does it compare with other models?
Meta's released a few benchmarks out of the box, and they're fairly impressive. Though as always, take these numbers with a grain of salt - there are benchmarks and then there are real-world applications.
Relative to the existing open-source models, Llama 2 beats Falcon (the previous "best" widely-available model) across the board, and beats Llama 1 on all but one benchmark. As far as we can tell, the big improvements come from improved dataset quality and the RLHF reward model. Basically, Meta spent the money to curate better feedback on what counts as “helpful” than what the open-source community had access to.
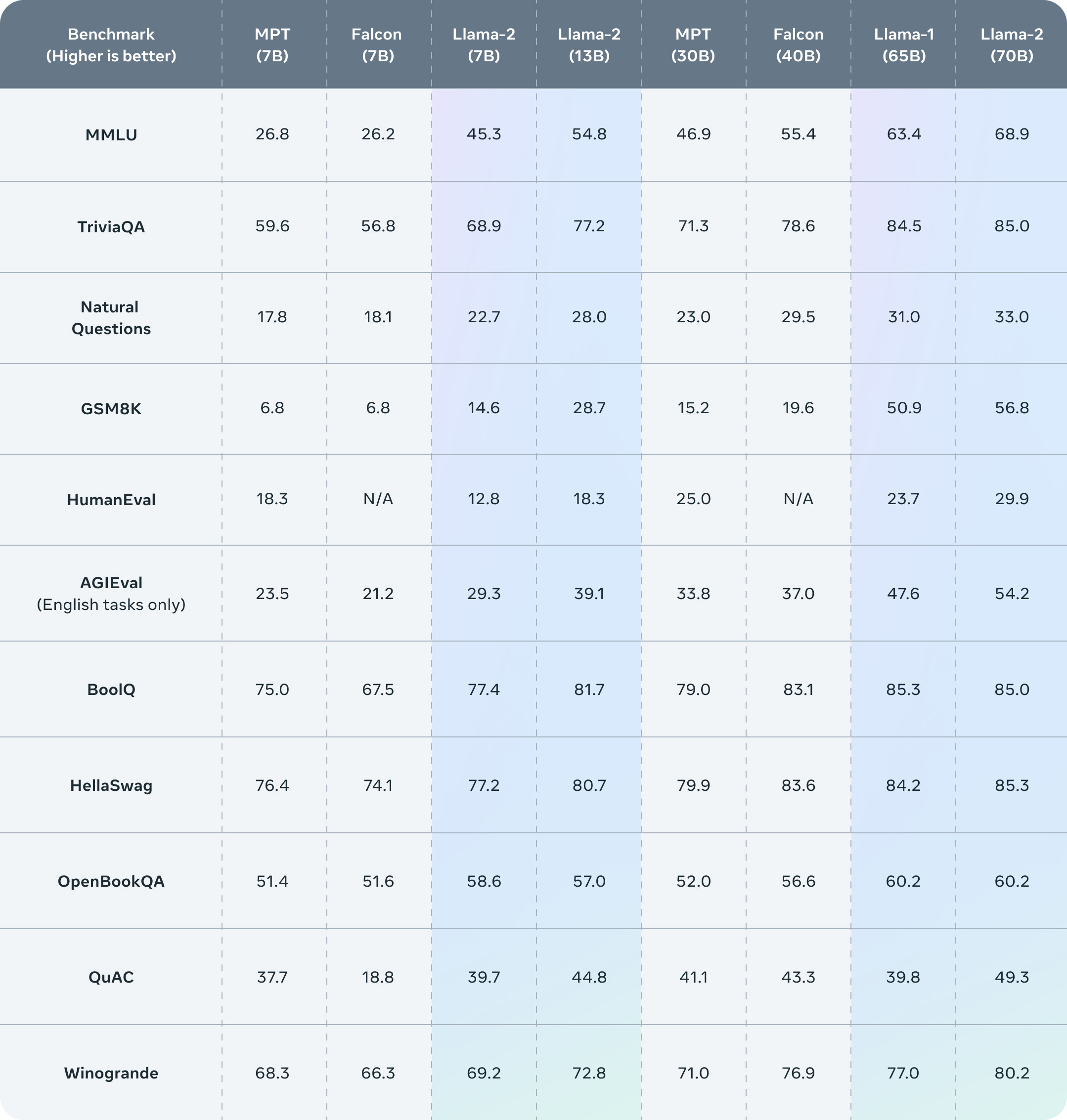
Compared to closed-source models, though, Llama 2 falls a little short. It's roughly tied with GPT-3.5, with the key exception of coding tasks, and still lags behind PaLM-2 and GPT-4. But as I mentioned before, this has the potential to improve quickly now that the weights are open-sourced and commercially licensed.

Where we're headed
A release like this doesn’t just happen overnight. It’s likely been in the works for a while, and judging from the state of the paper, it feels like there’s still more research behind the scenes that didn’t make it in. From
again:At no point does Llama 2 feel like a complete project or one that is stopping anytime soon. In fact, the model likely has been trained for months and I expect the next one is in the works.
So while it may take months or even years, I’m guessing we’ll see a Llama 3 at some point. In the meantime, though, companies face another yet decision on whether to own their LLM entirely or whether they want to keep relying on proprietary models. One company that’s moving forward with Llama 2 is Qualcomm, which plans to optimize the model for its Snapdragon CPUs, making it potentially available on smartphones.
That decision between open-source and proprietary will only add to the AI platform quicksand as fine-tuned versions of Llama 2 become more enticing. Not to mention the advancement of Llama-based tooling, libraries, and agents. As I mentioned before, if the family tree of Llama 1 is anything to go by, we’re about to see an explosion of models based on Llama 2.
If you want to start testing or building with Llama 2, here’s where you can try it out:

Unless you have over 700M daily active users, which restricts YouTube, WeChat, TikTok, LinkedIn, and Snap.
The link to the Llama2 paper doesn't seem to be working anymore.
This accelerates further Meta's diversification away from the metaverse and its repositioning as a "good actor" in the social media ecosystem.