

OpenAI’s DevDay: The biggest announcements
New models, new products, and new pricing.


Welcome to a bonus issue of Artificial Ignorance! Wednesday’s post will still arrive on schedule.
I’ve just wrapped up a full day of announcements, talks, and breakout sessions at OpenAI’s DevDay.
These changes will be available immediately to attendees, and will be rolled out in the coming weeks more broadly. If there’s something you’re interested in seeing more in-depth, let me know in the comments and I’ll do my best to test it out. Let’s go!
GPT-4 Turbo
There was a brand new model unveiled at the conference, GPT-4 Turbo. This model is bigger, more capable, and cheaper than the previous GPT-4 model.
New features:
A 128K token context window: that’s 16 times bigger than the current default GPT-4 context window - enough for 300 pages of a book.
JSON mode: models can respond with valid JSON when using function calls, solving a major pain point for agent developers.
Native RAG: files and documents can be uploaded to GPT-4 Turbo, where they will be automatically chunked, embedded and retrieved.
Updated knowledge cutoff: April 2023, vs September 2021.
Reproducible outputs: users will be able to pass a seed to the API when calling the model, and will be able to get reproducible results when using models.
New pricing:
2-3x drop in pricing for GPT-4 Turbo vs GPT-4.
Also a 2-3x drop in pricing for the current GPT-3.5 16K model.
New custom models:
GPT-4 Turbo will also serve as a foundation for companies who want to create truly custom models - much more so than fine-tuning.
OpenAI will work with companies to collect training data, train the model, and do bespoke RL fine-tuning.
But expect it to be extremely limited (and pricey).
Other ChatGPT upgrades
While the conference was mostly focused on developers, there were plenty of announcements about the consumer version of ChatGPT as well.
New features:
GPT-4 Turbo by default: ChatGPT Plus users will get the newest model by default.
All models in one: the GPT-4 model picker is gone - there’s a single model which will know when to use the different tools (browsing, data anlysis, and image generation).
The GPT store: ↓↓↓
GPTs and the GPT Store
GPTs are full-fledged Copilots - tailored versions of ChatGPT that are available for personal or public use.
How it works:
Each GPT is a bundled set of instructions, knowledge, and tools.
They’ll have access to web browsing, DALL-E 3, and code interpreter.
They’re buildable with natural language - no coding skills required.
GPTs can be thought of as miniature agents (though OpenAI very noticeably did not use the word “agent” in talking about them).
They’re publishable in the GPT Store, or available for private/internal use.
The top GPTs will be eligible for revenue sharing in the future.
Once published, they’ll automatically have the ability to use GPT-Vision and audio input/output via the ChatGPT iOS app.
GPTs are the next evolution of plugins - my expectation is that plugins will slowly be phased out as GPTs are prioritized (luckily, there’s an automatic way to convert your plugin to a GPT).
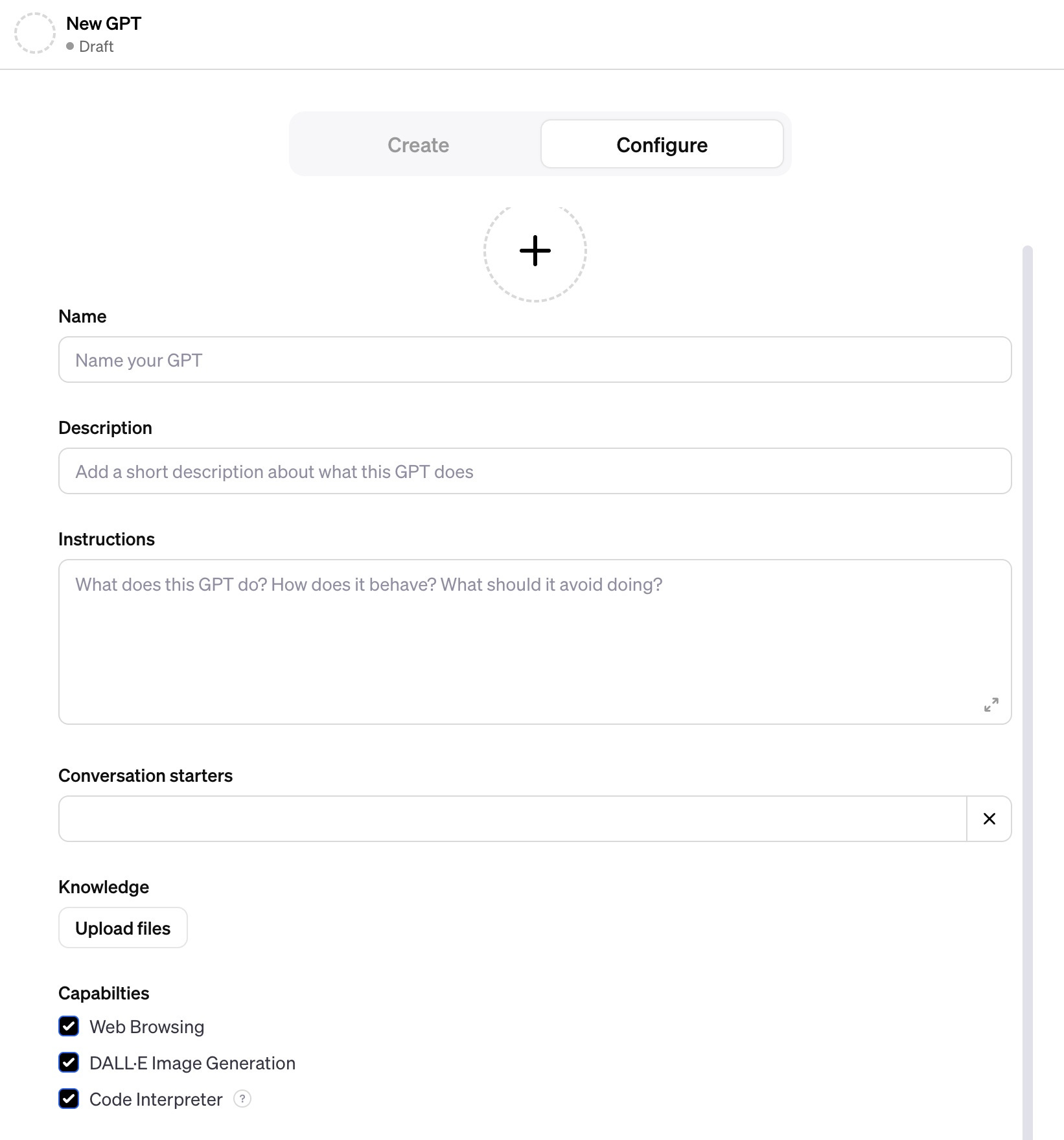
Creating a GPT:
This is a pretty cool workflow: you go back and forth with ChatGPT to create the final output, but you can also explicitly add settings via the Configure screen.
Names, Descriptions, Instructions, Conversation starters, and Profile images can be created using ChatGPT itself.
Instructions are basically custom system prompts, to dictate how the GPT should behave, and what it should avoid doing.
Conversation starters are placeholder questions or prompts to show users good ways to use your GPT.
Multiple plugins are available, as well as the ability to add your own functions.
You can upload files for the GPT to query from - no more “Chat with your PDF” plugin required.
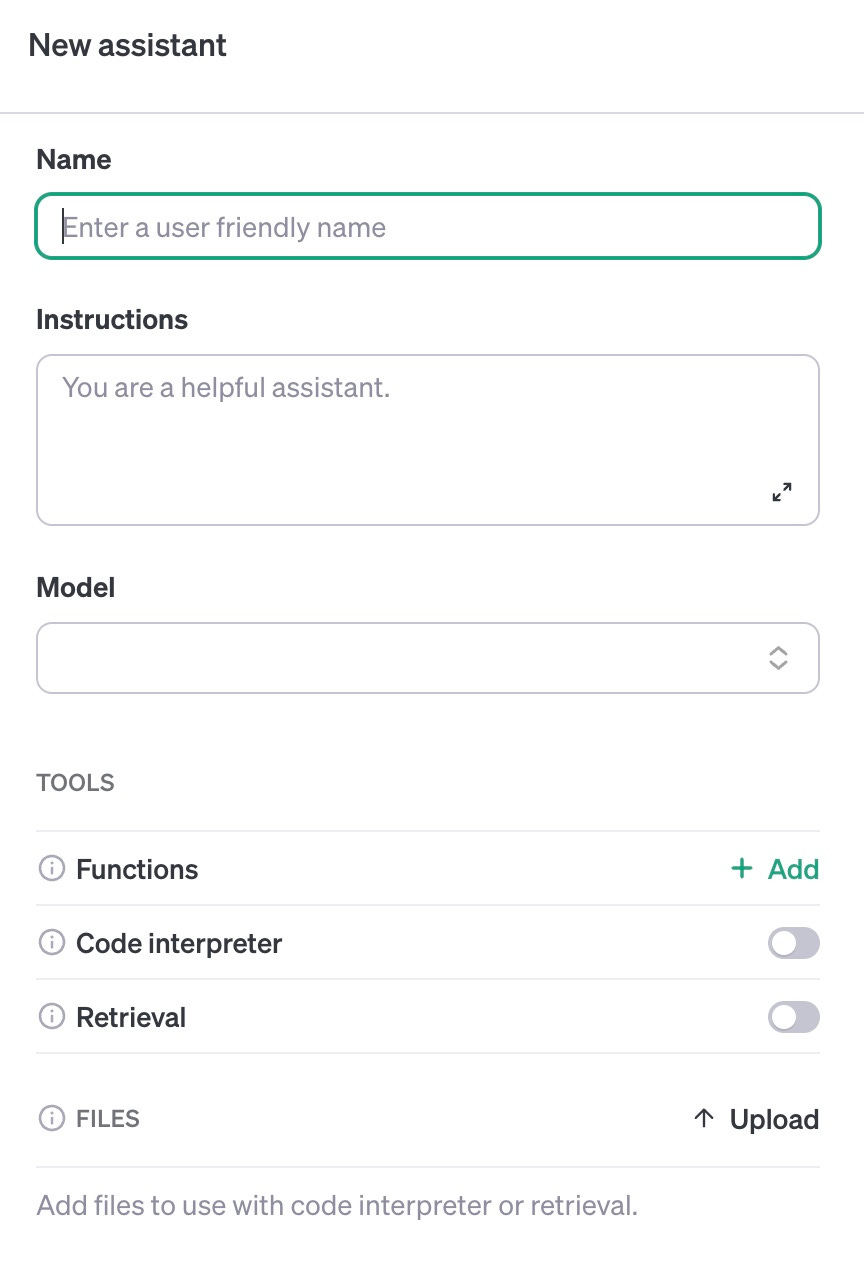
Assistants API
Behind the scenes of GPTs is the Assistants API. This API lets developers build their own assistant experience natively, and removes the burden of lot of LLM operations setup.
How it works:
Assistants are a new type of “object”: they’re created by setting instructions (a custom system prompt), a model, and any functions, tools, and documents.
Functions: Function calling as a whole has been improved, but you can pass functions to an assistant that they can reliably use.
Tools: Assistants will have access to Code Interpreter, though not other plugins yet.
Documents: Users can provide documents that Assistants will automatically be able to search and reference when answering user questions.
Threads and Messages: In the past, you had to keep track of every user’s GPT conversation, their previous messages, and any custom system prompts. Now, you can create a new Thread for every user, and OpenAI will keep track of each Thread separately. Then all you have to do is load the old thread from OpenAI, and send a new Message with that Thread ID.
Coming soon:
Multimodality: letting Assistants, see, speak, and hear.
Bring-your-own-code-interpreter: the ability to bring your own code interpreter, if you want to give more capabilities than the default OpenAI option.
Asynchronous support: the ability to send messages to an Assistant and wait for the response later, via websockets and webhooks.
Other API upgrades
Beyond the new model, you can use OpenAI’s APIs to interact with images, voice, and vision.
Whats new:
Multiple new API modalities: DALL-E, GPT-Vision, and TTS (text-to-speech)
The audio generation model comes with 6 voices to choose from.
Whisper V3 (a new transcription model) - coming soon to API.
Fine-tuning APIs for GPT-3.5 16K, and GPT-4 (beta testers only)
Higher rate limits: accounts will get increase their rate limits, and apply for even higher limits if necessary.
Breakout sessions
Beyond the keynote, there were a number of amazing breakout sessions for developers. I don’t have space to review all of the details, but below are some of the things that were covered. If you have any specific questions, leave a comment!
Prompt engineering best practices
Prompt engineering vs RAG vs fine-tuning: when to use each approach
Eval frameworks and managing your own evals
Fine-tuning best practices
Combining fine-tuning and RAG
Improving LLM UX via steerability and safety
Using model guardrails
Improving model consistency via grounded context
Common LLM mistakes in completions
Evals best practices and creating evals with other LLMs
Managing model latency and cost via semantic caching

Odds and ends
Satya Nadella made an appearance! He gave all attendees free access to GitHub Copilot Enterprise.
Following in the footsteps of Microsoft, OpenAI will also defend users who are sued for copyright infringement when using their products.
OpenAI now has 2 million developers using its APIs, and 92% of the Fortune 500 are using its products in some way.
There are 100 million weekly active users of ChatGPT, entirely through word of mouth growth.
Despite being the company’s first conference, it was incredibly well organized! Hats off to the production team and event staff.

Final thoughts
OpenAI isn’t just a AI research powerhouse - they’re also a software development powerhouse. It is a little unbelievable how quickly they’re launching things that have nothing to do with better models.
Models aren’t the only way to create value. Having a great model is table stakes - OpenAI is going after all of the headaches (and there are a ton of headaches) involved in building production-graded LLM applications.

Startups need to be very, very careful of what they build on top of OpenAI. This has been obvious for a while now, but the point still stands. I can’t count how many apps and ChatGPT wrappers are now dead startups walking.
The open-source community also needs to keep its eyes peeled. While open-source projects still have a crucial role, they’re still competing at some level with OpenAI for developer mind share. I’m guessing OpenAI will keep baking in tools and features that replicate open-source projects.

This is a great summary, thanks for providing all the details from the event.
Nice write up. Thank you