

How to build an AI search engine (Part 2)
VC funding, here we come.

Welcome back to part 2 of our series on building an AI-powered search engine! In the previous tutorial, we created a working command-line app that combined search results with an LLM to generate comprehensive, cited answers to user queries. This time, we're going to take that backend and create a user-friendly web interface.

The plan
Here's a high-level overview of what we're going to tackle in this tutorial:
Creating a Flask app to serve our frontend and handle API requests
Implementing streaming responses for real-time updates
Building a responsive UI that displays search results, sources, and related queries
Adding some aesthetic improvements to enhance the user experience
Making a Flask app
The first major change we need to make is converting our Python script into a proper web application using Flask. If you don't already have it installed, run:
pip install flaskWe're going to work with two endpoints:
An
index.htmlpage to house our UIAn
/askAPI route to handle user queries (which will take the place of our command-lineaskfunction)
Here's what that looks like in code (using all of the functions from part 1 of our tutorial):
app = Flask(__name__)
@app.route("/")
def index():
# Home page
return render_template("index.html")
@app.route("/ask", methods=["POST"])
def ask():
# Ask page (takes a query and returns a response)
query = request.json["query"]
unique_urls = set()
full_results = []
# Generate related queries
print("Getting search results...\n")
related_queries = generate_related_queries(query)
for related_query in related_queries:
print(f"Related query: {related_query}")
print("\n")
for related_query in related_queries:
search_results = get_search_results(related_query)
for search_result in search_results:
if search_result["url"] not in unique_urls:
print(f"Reading {search_result['title']}")
unique_urls.add(search_result["url"])
search_result["content"] = get_url_content(search_result["url"])
search_result["id"] = len(full_results) + 1
full_results.append(search_result)
return Response({"response": generate_response(query, full_results)})However, this approach has a big issue - we're not taking advantage of the streaming responses from our LLM!
Besides, we've also lost the helpful "thinking" messages that helped break up the wait time in the command-line interface, since our print statements don't ever make it to the user.
Yielding to the front-end
To solve said problems, we can start working with streaming responses with Flask's built-in stream_with_context helper. We're also going to move the bulk of our ask route into a new stream_response function, to easily replace our print statements with yield:
@app.route("/ask", methods=["POST"])
def ask():
# Ask page (takes a query and returns a response)
query = request.json["query"]
return Response(
stream_with_context(stream_response(query)), content_type="text/plain"
)And here's the new stream_response function:
def stream_response(query: str):
unique_urls = set()
full_results = []
yield (f"Searching for {query}...\n")
related_queries = generate_related_queries(query)
for related_query in related_queries:
yield (f"Related query: {related_query}\n")
yield ("\n")
for related_query in related_queries:
search_results = get_search_results(related_query)
for search_result in search_results:
if search_result["url"] not in unique_urls:
yield (f"Reading {search_result['title']}\n")
unique_urls.add(search_result["url"])
search_result["content"] = get_url_content(search_result["url"])
search_result["id"] = len(full_results) + 1
full_results.append(search_result)
yield from generate_response(query, full_results)I hadn't used yield in this way before, but it provides an elegant way to send progress updates to the user as the LLM is working. Each "thinking" message can be sent individually, helping to keep the user engaged while they wait for the final response.
We'll also need to make some similar changes to our generate_response function. Luckily, yield works through multiple layers of function calls (thanks to the yield from keyword we used above), so we can stream the LLM's tokens directly back to the user as they're generated.
def generate_response(query: str, results: List[Dict]) -> str:
# Format the search results
formatted_results = "\n\n".join(
[
f"{result['id']}. {result['title']}\n{result['url']}\n{result['content']}"
for result in results
]
)
# Generate a response using LLM (Anthropic) with citations
prompt = ANSWER_PROMPT.format(QUESTION=query, SEARCH_RESULTS=formatted_results)
# Make an API call to Anthropic (using Claude 3.5 Sonnet)
with client.messages.stream(
model="claude-3-5-sonnet-20240620",
max_tokens=1000,
temperature=0.5,
messages=[
{"role": "user", "content": prompt},
{"role": "assistant", "content": "Here is the answer: <answer>"},
],
stop_sequences=["</answer>"],
) as stream:
for text in stream.text_stream:
yield (text)
yield ("\n")
yield ("Sources:\n")
for result in results:
yield (f"{result['id']}. {result['title']} ({result['url']})\n")On the front end, we need to send an AJAX request when the user submits their query, then catch each response chunk as it's sent to display it on the page:
<body>
<div class="search-container">
<h1>AI-Powered Search</h1>
<form id="search-form">
<input type="text" id="query" class="search-box" placeholder="Ask me anything..." required>
<br>
<button type="submit" class="search-button">Search</button>
</form>
</div>
<div id="response-container"></div>
<script>
document.getElementById('search-form').addEventListener('submit', function(e) {
e.preventDefault();
const query = document.getElementById('query').value;
const responseContainer = document.getElementById('response-container');
responseContainer.innerHTML = 'Searching...';
fetch('/ask', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ query: query }),
}).then(response => {
const reader = response.body.getReader();
const decoder = new TextDecoder();
responseContainer.innerHTML = '';
function readStream() {
reader.read().then(({ done, value }) => {
if (done) {
return;
}
const chunk = decoder.decode(value, { stream: true });
responseContainer.innerHTML += chunk;
responseContainer.scrollTop = responseContainer.scrollHeight;
readStream();
});
}
readStream();
}).catch(error => {
responseContainer.innerHTML = 'An error occurred: ' + error;
});
});
</script>
</body>Here's what that looks like in action:
Data vs text
This is a good start, but we can make some improvements. The first is differentiating between the metadata (like sources and related queries) and the actual response text.
To accomplish this, we're going to have to make some changes that, to be honest, feel a bit hacky:
We'll wrap each response chunk in either
<data>or<text>tagsOn the front end, we'll parse
<data>tags as JSON and store that information, while<text>blocks will be displayed immediately
def stream_response(query: str):
unique_urls = set()
full_results = []
related_queries = generate_related_queries(query)
for related_query in related_queries:
search_results = get_search_results(related_query)
for search_result in search_results:
if search_result["url"] not in unique_urls:
# yield (f"Reading {search_result['title']}\n")
unique_urls.add(search_result["url"])
search_result["id"] = len(full_results) + 1
full_results.append(search_result)
yield f"<data>{json.dumps({'type': 'source', 'data': search_result})}</data>\n"
for search_result in full_results:
search_result["content"] = get_url_content(search_result["url"])
yield from generate_response(query, full_results)
yield f"<data>{json.dumps({'type': 'related_queries', 'data': related_queries})}</data>\n"There's also a decent bit of new logic required to parse this on the front end:
We're now tracking related queries and sources separately
In case the response doesn't make it in its entirety, we're also keeping track of the last seen opening tag and a content buffer
<script>
let responseContainer = document.getElementById('response-container');
let relatedQueries = [];
let sources = {};
let jsonBuffer = '';
let currentTag = '';
document.getElementById('search-form').addEventListener('submit', function(e) {
e.preventDefault();
const query = document.getElementById('query').value;
responseContainer.innerHTML = 'Searching...';
fetch('/ask', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ query: query }),
})
.then(response => {
responseContainer.innerHTML = '';
const reader = response.body.getReader();
const decoder = new TextDecoder();
function readStream() {
reader.read().then(({ done, value }) => {
if (done) {
processBuffer(); // Process any remaining data in the buffer
displaySources(sources);
displayRelatedQueries(relatedQueries);
return;
}
const chunk = decoder.decode(value, { stream: true });
processChunk(chunk);
readStream();
});
}
readStream();
})
.catch(error => console.error('Error:', error));
});
function processChunk(chunk) {
let remainingChunk = chunk;
while (remainingChunk.length > 0) {
if (currentTag === '') {
const openingDataTag = remainingChunk.indexOf('<data>');
const openingTextTag = remainingChunk.indexOf('<text>');
if (openingDataTag !== -1 && (openingDataTag < openingTextTag || openingTextTag === -1)) {
currentTag = 'data';
remainingChunk = remainingChunk.slice(openingDataTag + 6);
} else if (openingTextTag !== -1) {
currentTag = 'text';
remainingChunk = remainingChunk.slice(openingTextTag + 6);
} else {
break; // No opening tag found, wait for next chunk
}
} else {
const closingTag = `</${currentTag}>`;
const closingTagIndex = remainingChunk.indexOf(closingTag);
if (closingTagIndex !== -1) {
const content = jsonBuffer + remainingChunk.slice(0, closingTagIndex);
if (currentTag === 'data') {
handleJsonData(content);
} else {
appendToResponse(content);
}
jsonBuffer = '';
currentTag = '';
remainingChunk = remainingChunk.slice(closingTagIndex + closingTag.length);
} else {
jsonBuffer += remainingChunk;
break; // Closing tag not found, wait for next chunk
}
}
}
}
function processBuffer() {
if (jsonBuffer && currentTag) {
if (currentTag === 'data') {
handleJsonData(jsonBuffer);
} else {
appendToResponse(jsonBuffer);
}
jsonBuffer = '';
currentTag = '';
}
}
function handleJsonData(jsonString) {
try {
const jsonData = JSON.parse(jsonString);
if (jsonData.type === 'related_queries') {
relatedQueries = jsonData.data;
} else if (jsonData.type === 'source') {
sources[jsonData.data.id] = jsonData.data;
}
} catch (error) {
console.error('Error parsing JSON:', error);
}
}
function displayRelatedQueries(queries) {
// Update UI with related queries
queries.forEach(query => {
appendToResponse(`- ${query}\n`);
});
}
function displaySources(sources) {
// Update UI with sources
sources.forEach(source => {
appendToResponse(`- ${source.title}: ${source.url}\n`);
});
}
function appendToResponse(text) {
responseContainer.innerHTML += text;
responseContainer.scrollTop = responseContainer.scrollHeight;
}
</script>In hindsight, there's probably a more elegant way to architect this!
Highlighting sources
One of the features I really love about Perplexity is the ability to see citations in-line with direct links to the original source. In our V1 Python script, we included the citation numbers directly in the response, but the links themselves were listed at the bottom and not clickable.
To get clickable in-line citations, we're going to check the incoming text chunks for closing square brackets (]), then look backwards to annotate the HTML with footnote links.
if (text.includes(']')) {
const footnoteRegex = /\[(\d+)\]/g;
const htmlText = responseContainer.innerHTML.replace(footnoteRegex, (match, footnoteNumber) => {
const source = sources[parseInt(footnoteNumber)];
if (source) {
return `<sup><a href="${source.url}" target="_blank">${match}</a></sup>`;
}
return match;
});
responseContainer.innerHTML = htmlText;
}Adding follow-ups
And since we're already storing the related queries and sources in the front end, we can generate nicer-looking HTML elements to display them.
function displayRelatedQueries(queries) {
const container = document.querySelector('#related-queries-container');
const queriesContainer = container.querySelector('.related-queries');
queriesContainer.innerHTML = '';
queries.forEach(query => {
const queryElement = document.createElement('span');
queryElement.classList.add('related-query');
queryElement.textContent = query;
queryElement.addEventListener('click', () => {
document.getElementById('query').value = query;
document.getElementById('search-form').dispatchEvent(new Event('submit'));
});
queriesContainer.appendChild(queryElement);
});
container.style.display = 'block';
}
function displaySources(sources) {
const container = document.querySelector('#sources-container');
const sourcesContainer = container.querySelector('.sources');
sourcesContainer.innerHTML = '';
Object.entries(sources).forEach(([index, source]) => {
const sourceElement = document.createElement('p');
sourceElement.innerHTML = `${source.id}. <a href="${source.url}" target="_blank">${source.title}</a>`;
sourcesContainer.appendChild(sourceElement);
});
container.style.display = 'block';
}Here’s what that looks like:
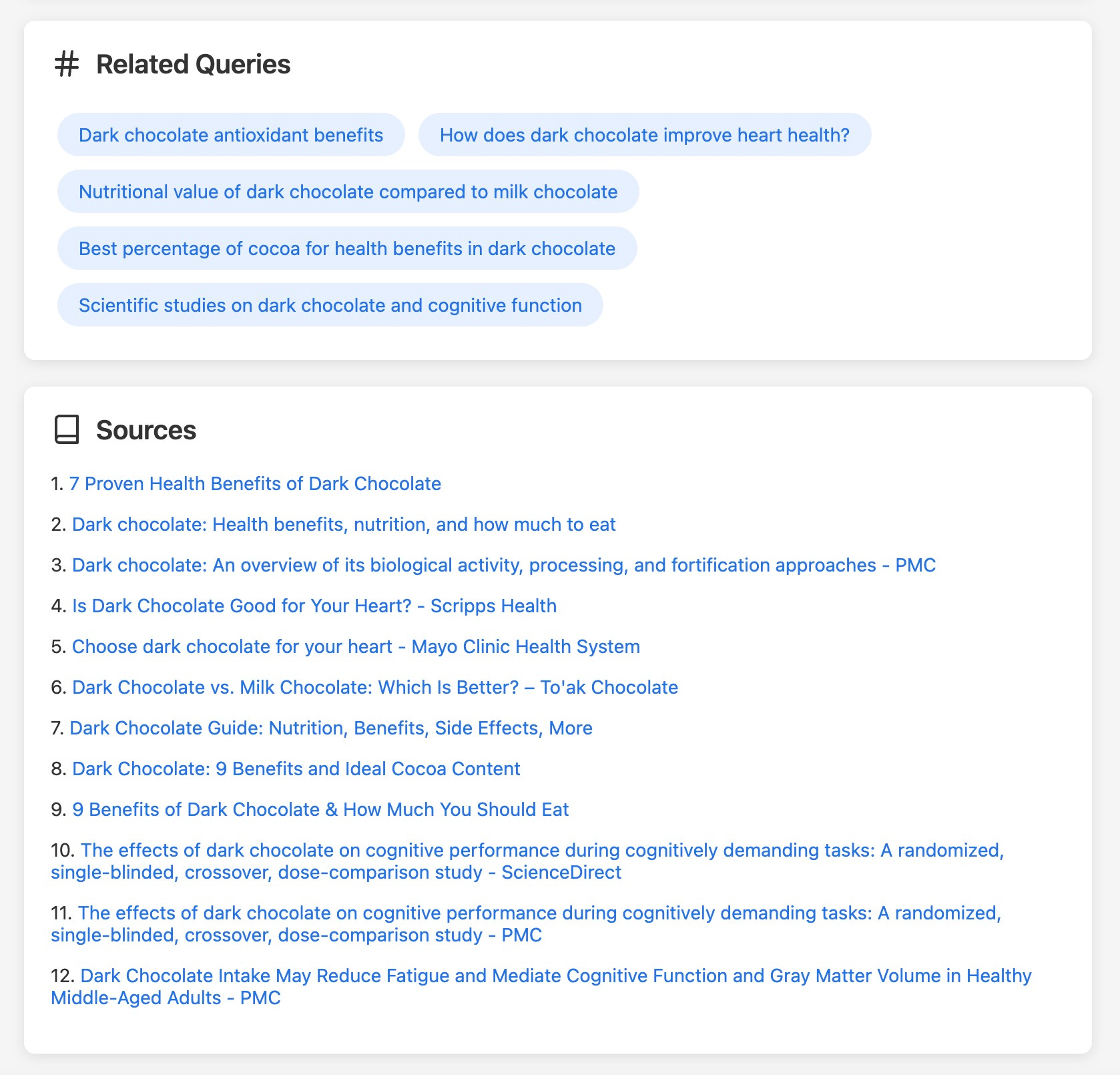
Style points
With all of these pieces in place, the app is functionally complete. But I wanted to try making it a bit more user-friendly as well.
Throughout this process, I worked with Claude to iterate on the CSS - and honestly, it's still not mind-blowing, but it's better than what I had originally.
But I also really wanted to improve the perceived wait time for the user.
The Python script would print out each step as it was running so you could see the progress being made. For the web version, I wanted to dynamically update a loading screen based on the data coming from the backend.
We have all the pieces necessary to do this - it was just a matter of setting up the right loading events. After a few iterations, I landed a set of functions to update the loading icon while the user waits for the final response:
function addToLoadingQueue(message) {
loadingQueue.push(message);
updateLoadingDisplay();
}
function clearLoadingQueue() {
loadingQueue = [];
updateLoadingDisplay();
}
function startLoadingInterval() {
if (!loadingInterval) {
loadingInterval = setInterval(updateLoadingDisplay, 4000);
}
}
function stopLoadingInterval() {
if (loadingInterval) {
clearInterval(loadingInterval);
loadingInterval = null;
}
}
function updateLoadingDisplay() {
if (loadingQueue.length === 0) {
hideLoading();
stopLoadingInterval();
} else if (loadingQueue.length === 1) {
showLoading(loadingQueue[0]);
} else {
loadingQueue.shift();
showLoading(loadingQueue[0]);
}
}
function showLoading(text) {
loadingText.textContent = text;
loadingContainer.style.display = 'flex';
}
function hideLoading() {
loadingContainer.style.display = 'none';
}And here’s the final version (along with a bit of a cheeky rename):
Final thoughts
Overall, this AI-powered search engine is still pretty slow compared to Perplexity. Check out their site for an example of what a truly polished UX feels for this kind of application.
That said, we've learned a lot about how to augment an LLM with real-time search results and build towards a usable product. There are some clear areas for further optimization, such as:
Paying for a Brave plan to remove the rate limits on searches
Performing the internet searches in parallel to save time
Using smaller and/or locally hosted models to speed up generation times
If you want to see these optimizations in action, or if you have an idea for a future tutorial, leave a comment!
If you’re interested in learning more about building with LLMs, I’m working on an AI engineering course, and I want your feedback to help tailor the content. Sign up for updates here.
Really Informative. It would be really great if you could share the github repo link.
Thank you so much