

Hallucinations Are Fine, Actually
Why I changed my mind about AI's imperfections.

When I first started using ChatGPT, I quickly discovered its tendency to confidently make things up. Whether you want to call it lying, fabricating, or just bullshitting - it had no problems inventing citations or discussing factually incorrect events.
In my second-ever post, I was already harping on this:
ChatGPT is impressive in its capabilities, but there are important limitations to keep in mind. First and foremost, LLMs are not always factually correct. ChatGPT has a tendency to “hallucinate,” or confidently provide answers that are wholly wrong. It’ll summarize nonexistent books, or argue that one plus one is three3. It sometimes invents news sources or misattributes quotes. If ChatGPT were a person, it would be great at BSing.
As a result, a human should review and edit any AI-generated content, especially if it’s customer-facing.
I wasn't alone. The technical term "hallucination" quickly entered the mainstream, becoming shorthand for why generative AI remained fundamentally untrustworthy despite its impressive capabilities. Every few weeks seemed to bring another headline about people and companies alike getting in trouble for trusting AI too much.
But here's the thing: I've changed my mind. Not because hallucinations have disappeared - they haven't - but because I've come to see them as a surmountable challenge rather than an Achilles heel.
The Hallucination Panic
The media has had a field day with AI hallucinations, and not entirely without reason. The examples are both amusing and concerning:
A lawyer citing fake cases generated by ChatGPT in an actual legal brief.
Google's AI Search Overview telling users to eat rocks and put glue on pizza.
A talk show host suing for defamation after ChatGPT claimed he committed financial crimes.
Bing AI confirming the winner of the Super Bowl before it happened.
And even an airline being held liable for a discount its chatbot invented.
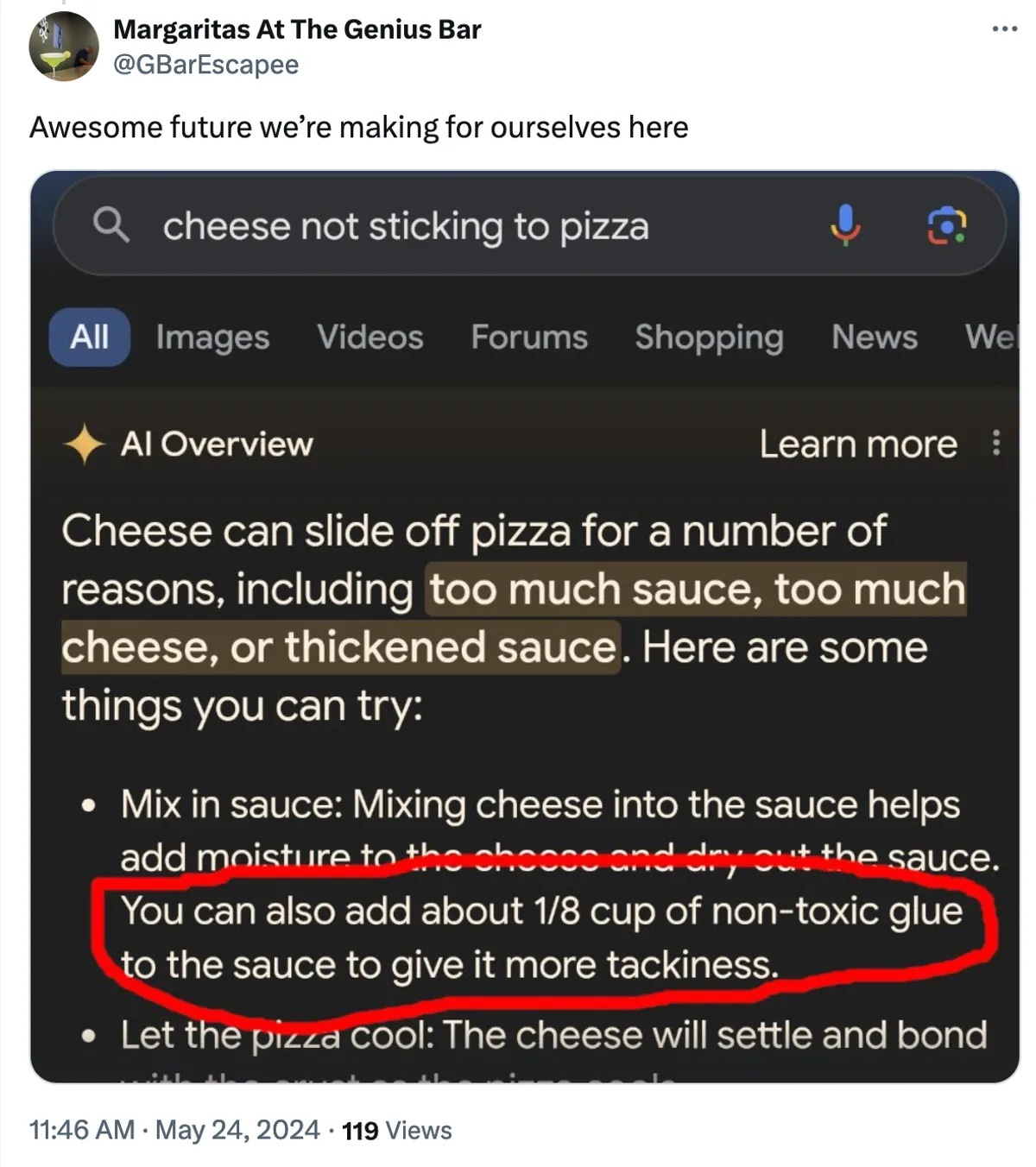
From the beginning of ChatGPT to today, these stories have fueled headlines worried about hallucinations. Just a few of the many, many examples:
Google Search Is Now a Giant Hallucination – Gizmodo
We have to stop ignoring AI’s hallucination problem – The Verge
Tech experts are starting to doubt that ChatGPT and A.I. ‘hallucinations’ will ever go away: ‘This isn’t fixable’ – Fortune
The narrative solidified: LLMs are impressive toys, but hallucinations make them unsuitable for serious usage. To this day, AI skeptics (such as Ed Zitron) will make this argument as to why the entire industry is a waste:
Personally, when I ask someone to do research on something, I don't know what the answers will be and rely on the researcher to explain stuff through a process called "research." The idea of going into something knowing about it well enough to make sure the researcher didn't fuck something up is kind of counter to the point of research itself.
This argument starts from the position that "unless an LLM is 100% reliable, it's useless" - and I can see why that's a tantalizing position to take. But I think this black-and-white view misses several key trends in how models, products, and even our own behaviors are evolving, making AI more reliable along the way.
The Bitter Lesson
Here's the rub: hallucinations are kind of fundamental to LLMs. Andrej Karpathy has described them as "dream machines" - a prompt starts them in a certain place and with a certain context, and they lazily, hazily remember their training data to formulate an answer that seems probable.
Most of the time the result goes someplace useful. It's only when the dreams go into deemed factually incorrect territory that we label it a "hallucination". It looks like a bug, but it's just the LLM doing what it always does.
Yet even though it's unlikely that we'll get these "factually incorrect" hallucinations down to 0%, that doesn't mean we can't improve the numbers. One example comes from Vectara, which has been tracking new frontier models against its hallucination benchmark.
Some of the oldest models, like the comparatively ancient Mistral 7B, have a hallucination rate of nearly 10%. Yet the latest group of flagship models, from o3-mini to GPT-4.5 to Gemini 2.0, have a hallucination rate of near or below 1%.
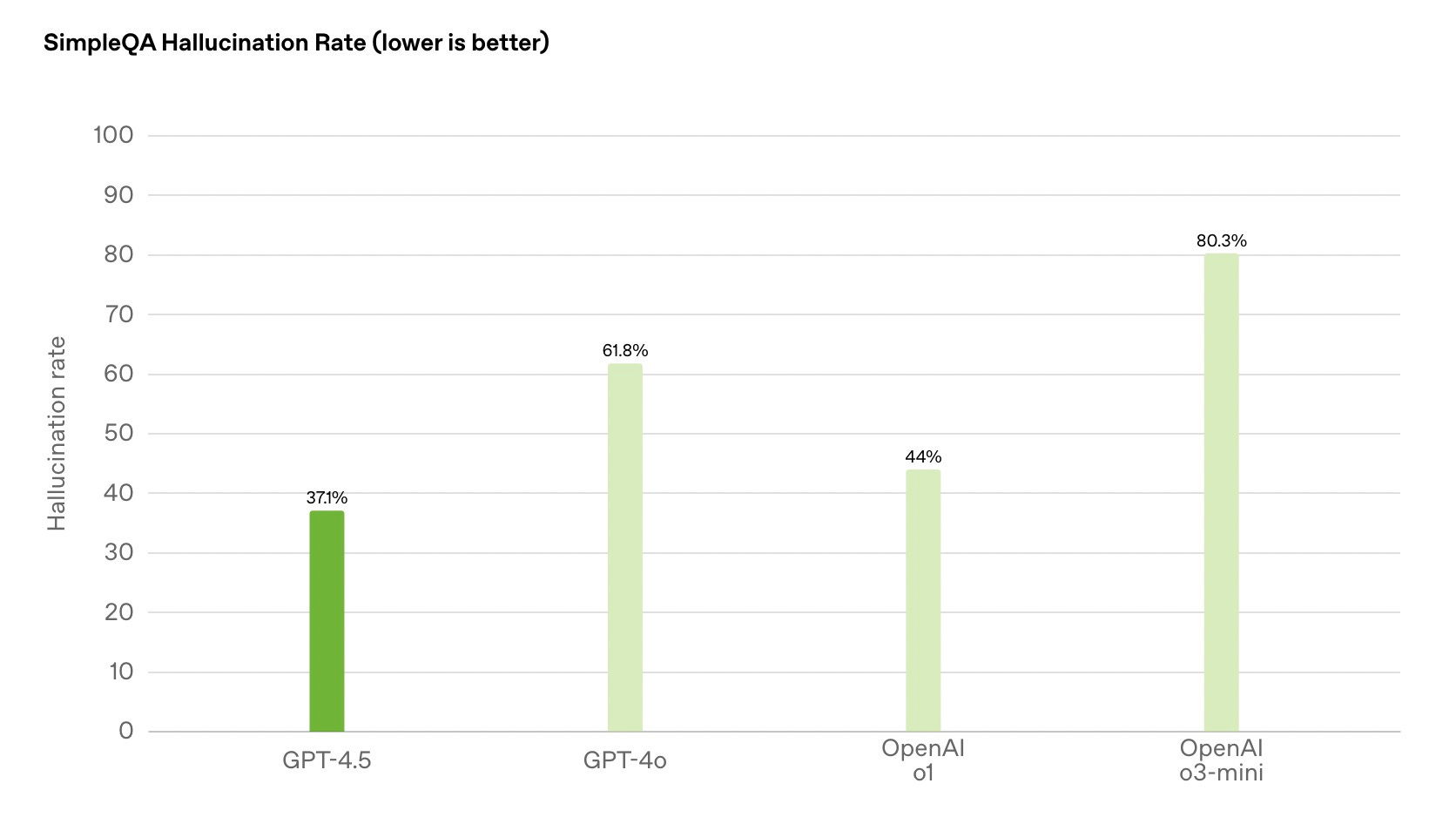
With OpenAI's latest GPT-4.5 launch, the company also showed that its performance on another hallucination benchmark, SimpleQA, went from 62% (with GPT-4o) to 37%. Across the board, newer model generations consistently outperform their predecessors when it comes to factual reliability.
This improvement isn't accidental. Model providers have recognized hallucinations as a significant barrier to adoption and are actively working to address them through better training methods, reinforcement learning from human feedback, and architectural improvements.
So while perfect factual accuracy may remain elusive with current architectures, the trend line is clear and encouraging - these models' raw capabilities continue to improve at a remarkable pace. But it’s only the first step in creating hallucination-free (or at least, hallucination-resistant) experiences.
Revenge of the wrappers
Beyond the benchmarks, focusing exclusively on the raw models misses a crucial point: LLMs aren't used in isolation. They're increasingly embedded within systems designed to amplify their strengths and mitigate their weaknesses.
Take Claude 3.5 Sonnet. On its own, it's a solid model for generating code - I've used it plenty of times to write one-off scripts. But I wouldn't ordinarily think of it as something that can 10x my productivity; there's too much friction in giving it the right context and describing my problem accurately. Not to mention having to copy/paste its answer and slowly integrate it into my existing code.
But Cursor has managed to take Claude 3.5 Sonnet and turn it into an agentic tool that can 10x my productivity. It's not perfect - far from it - but it's dramatically more effective than Claude alone. Cursor has built an entire system of prompt engineering, tool usage, agentic loops, and more to give Claude an Iron Man-esque suit of armor when it comes to coding1.
Perplexity offers another example. While "web search" is now a standard feature in many AI chatbots, Perplexity created a compelling AI search experience at a time when asking GPT-3.5, "Who won the 2030 Super Bowl?" would yield confidently incorrect answers.
This may actually lead to some vindication of products that have previously been derided as "ChatGPT wrappers." Yes, many of them were lightweight, low effort products, and they will likely become either obsoleted by better models/products or lost amidst the sea of copycats. But we're already seeing benefits of adding software-based scaffolding around ChatGPT. I often think of a "car" metaphor here2 - the engine is powerful, but not usable as a form of transport without the doors, windows, and wheels.
Benedict Evans has also argued that we may have jumped the gun on thinking of LLMs as fully-finished "products":
LLMs look like they work, and they look generalised, and they look like a product - the science of them delivers a chatbot and a chatbot looks like a product. You type something in and you get magic back! But the magic might not be useful, in that form, and it might be wrong. It looks like a product, but it isn’t.
Engineering techniques pioneered by apps like Cursor and Perplexity can boost the reliability and impact of LLMs. As we see more specialized tools - like Harvey for lawyers or Type for writers - I expect the effective hallucination rate to drop even further.
Augmentation over automation
Perhaps the most crucial shift, though, is in how we approach these tools. The early fascination with LLMs led many to view them as capable of immediately automating end-to-end work - magical AI systems that could take over jobs completely. This framing naturally made hallucinations (not to mention potential job displacement) seem catastrophic.
But what I see as a more nuanced, and ultimately more productive, framing is to view LLMs as augmentation tools. As a personal philosophy, I believe we should aim to augment work with AI, rather than automate it3. More than that, I increasingly see my work with LLMs as collaborative. And collaborating with someone (or something) means taking partial responsibility for the final output.
Ethan Mollick has referred to this as the difference between what he calls "centaurs" and "cyborgs":
Centaur work has a clear line between person and machine, like the clear line between the human torso and horse body of the mythical centaur. Centaurs have a strategic division of labor, switching between AI and human tasks, allocating responsibilities based on the strengths and capabilities of each entity.
On the other hand, Cyborgs blend machine and person, integrating the two deeply. Cyborgs don't just delegate tasks; they intertwine their efforts with AI, moving back and forth over the jagged frontier. Bits of tasks get handed to the AI, such as initiating a sentence for the AI to complete, so that Cyborgs find themselves working in tandem with the AI.
Choosing between the centaur and cyborg approaches hits particularly close to home regarding programming. It's so, so tempting to have Cursor Agent go off and do its thing, to wait until I can hit "Accept all changes" and move on to the next task4. And in a low-stakes scenario, that's probably fine.
But when it comes to working on a team or with a complex codebase, this strikes me as irresponsible. If, as AI proponents argue, LLMs are currently at the level of a "junior developer," then it's wild to imagine simply shipping AI-generated code without understanding it. And that applies more broadly: if you're willing to email 10,000 customers without proofreading the content written by a "junior marketer," that's on you5.
Because yes - Cursor gets it wrong. Perplexity gets it wrong. GPT-4.5 gets it wrong. Sometimes repeatedly, in ways both obvious and subtle. But I've also learned how to help my AI partners get things wrong less often:
I'm more explicit about the objectives and context of the project - sometimes via chat, sometimes via project settings.
I share the files, code snippets, and even documentation links that I think are going to be most relevant, to avoid wild goose chases.
I'm not afraid to try again with a different prompt, a different model, or a different conversation entirely; we all have brain farts sometimes (and LLMs can get into weird headspaces quickly).
Ultimately, I know that while AI can help me code/write/ideate, it can never be held accountable. To quote Simon Willison (emphasis added):
Just because code looks good and runs without errors doesn’t mean it’s actually doing the right thing. No amount of meticulous code review—or even comprehensive automated tests—will demonstrably prove that code actually does the right thing. You have to run it yourself!
Proving to yourself that the code works is your job.
Embracing imperfection
The real question isn't whether LLMs will ever stop hallucinating entirely - it's whether we can build systems and practices that make hallucinations increasingly irrelevant in practice. And I'm increasingly confident that we can.
So the next time you encounter an AI hallucination - whether it's an fake book title, a nonexistent Javascript method, or a confidently incorrect URL - remember that this all takes a bit of trial and error, but we’re making progress on the problem. Hallucinations are real, but they're also, increasingly, fine.

Ironically, they may have gone too far in tailoring their setup for Claude 3.5 Sonnet - try as I might, I can't quite get the same spark going with newer, ostensibly "smarter" models like o1 and Claude 3.7 Sonnet.
Sadly, I'm not a car guy, so while this makes sense in my head, feel free to tell me if it's actually terrible.
This isn't iron-clad: clearly there is some amount of drudgery that I love to automate with AI. But in general, I aim to reach for automation as the last step, not the first.
To be fair, I certainly do this "vibe coding" some of the time. But I'm slowly developing a thesis on when it seems like a workable approach, and when it doesn't - stay tuned for more on this topic.
A common complaint here is something along the lines of "if I have to review every line of code an LLM writes, why should I even bother using it?" And I mean... if you have to review every line of code a junior developer writes, why should you even bother hiring them?
Call me crazy, but I believe there's value in having a collaborator that can generate 80% correct solutions at 10x the speed, that writes documentation without complaint, that offers multiple approaches to solve a problem, and that never gets offended when you reject its ideas.
I know a few people who would pay really good money to have hallucinations.
The timing of this article on AI hallucinations feels almost cosmic! I wrote about this exact topic earlier this week(monday), exploring the untapped potential of these "creative inaccuracies" as I call them.
What resonates most with me in your piece is the shift from seeing hallucinations as fatal flaws to viewing them as collaborative opportunities. I've found this exact mindset shift transformative in my own work. The distinction between automation and augmentation is crucial - when we collaborate WITH these systems rather than expecting them to work FOR us, the relationship fundamentally changes.
I've been experimenting with those "impossible combinations" techniques he mentions but for product innovation rather than coding. What's fascinating is how often the hallucinated connections lead to genuinely novel approaches that wouldn't emerge from purely factual thinking. It's like having a brainstorming partner who isn't constrained by conventional wisdom or industry assumptions.
That said, I completely agree with the accountability point. The moment we abdicate responsibility for verifying outputs is when things get dangerous. I believe the most sophisticated AI users aren't those avoiding hallucinations entirely, but those who know when to embrace creative exploration versus when to demand strict factuality. That "hallucination awareness" makes all the difference between a productive partnership and a risky dependency.
If you're interested in my full framework for leveraging these creative inaccuracies for innovation, I wrote about it here: https://thoughts.jock.pl/p/ai-hallucinations-creative-innovation-framework-2025