

From Goldfish to Elephants: AI Memory In Practice
How ChatGPT, Claude, and legions of startups are building assistants that never forget.

One thing I keep coming back to in our post-ChatGPT era is the movie Her. It's not a secret that the movie has been a major inspiration for Sam Altman (he’s said it’s his favorite movie) and shaped how his company views building AI products. OpenAI even attempted to get Scarlett Johansson to provide her voice for their audio models (she declined).
But what made the AI in Her special wasn't just the human-level (and eventually superhuman-level) intelligence - it was the relational aspects of the AI. It could remember details about the user and form a personal relationship through accumulated understanding, shared history, and the gradual building of intimacy. Today, it’s led to the "holy grail" of chatbot features: personalization.
We're not there yet, but we are getting closer. The AI systems that millions of people chat with daily are evolving from digital goldfish - forgetting everything after a few thousand tokens - into something slowly approaching elephants, with increasingly sophisticated systems for remembering, summarizing, and learning from our interactions.

Why Memory (and Personalization) Matters
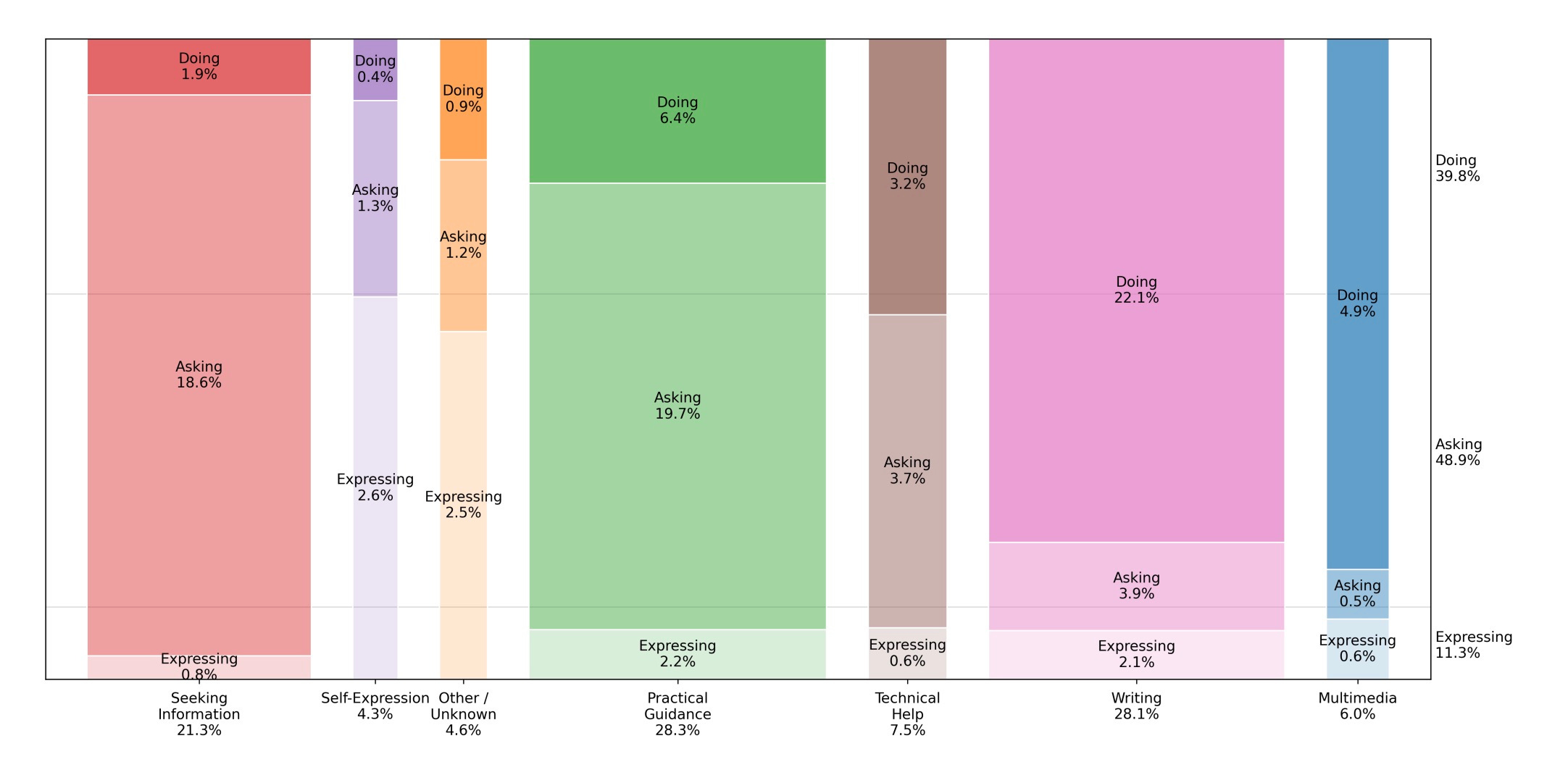
A new paper from OpenAI has garnered a ton of insight into how people use ChatGPT. There's a lot to discuss (and I hope to write more about the paper), but one headline takeaway was how ChatGPT usage has shifted over the past year.
Based on OpenAI's classifications, 47% of messages were for work in June 2024 - but by June 2025, that number had fallen to 27%, meaning nearly 3 in 4 conversations were about personal topics.
Furthermore, they broke out a new categorization of user messages: Asking, Doing, and Expressing.
Asking is when the user is seeking information or clarification to inform a decision, corresponding to problem-solving models of knowledge work. Doing is when the user wants to produce some output or perform a particular task, corresponding to classic task-based models of work. Expressing is when the user is expressing views or feelings but not seeking any information or action.
Based on their categories, I'd guess that most of both the Asking and Doing buckets would benefit from personalization. Anyone who's used ChatGPT or Claude for complex projects knows the frustration of constantly re-explaining background information. "Remember, I'm working on a React app with TypeScript, using Tailwind for styling, and I prefer functional components..." It's exhausting to provide the same context repeatedly, and the cognitive overhead often makes the tools less valuable than they could be.
In OpenAI's case, 89% of messages fall into those categories - 49% were Asking and 40% were Doing in their June 2025 data.
And that's without touching on the advertising nightmare potential of personalization - Google has been going down this rabbit hole for decades, attempting to learn more about the user in an effort to increase ad engagement (and therefore profits).
Right now, we're still experimenting with how personalization and memory should work. There's no settled best practice, no industry standard - just a fascinating evolution of approaches.
Short Term Memory: Context Windows
"Short-term memory" is a bit of a misnomer, but it's perhaps the closest analogy for a foundational LLM concept: context windows. The context is everything the AI can actively "hold in mind" during a single conversation. This is separate from its "world knowledge" - everything it consumed during its training phase, and internally "knows" - we're talking about specific content that's part of the current conversation.
Context windows are measured in tokens (roughly 0.75 words each), and when you hit the limit, the system starts "forgetting" earlier parts of the conversation to make room for new information. If you've ever had an extremely long conversation with ChatGPT, you're likely familiar with the chatbot's memory "degrading" over time.
Fortunately, though, the size of LLM contexts has exploded in recent months:
GPT-5: 400,000 tokens (roughly 5.5 copies of The Great Gatsby)
Claude 4 Sonnet: 1,000,000 tokens (about 14 copies of The Great Gatsby)
Gemini 2.5 Pro: 1,000,000 tokens (14 copies, with 2 million coming soon - 28 copies)
Grok 4: 256,000 tokens (about 3.5 copies of The Great Gatsby)
Consider that the first version of ChatGPT shipped with a 4,000 token context window - that’s a 250x increase in the past three years!
This engineering feat has unlocked a qualitative shift in what's possible. A million-token context window means you can upload entire codebases, full research papers, or entire project documentation and have the AI maintain awareness of it throughout your conversation.
That said, it's unclear whether we can continue scaling context windows indefinitely. Longer contexts are expensive - both computationally and financially, meaning it might not be cost-effective to grow short-term memory by another 250x. More importantly, there's the "lost in the middle" problem, identified in research by Liu et al. Even when AI systems can technically access information buried deep in their context, they often struggle to find and utilize it effectively1.

Long-Term Memory: ChatGPT vs Claude
Context windows solve the immediate problem of maintaining coherence within a single conversation. Still, they don't address the bigger challenge: how do AI systems remember you across conversations that span weeks, months, or years?
The major AI companies have remarkably similar feature sets here, though there are some underlying philosophical differences in how they're implemented.
ChatGPT's Approach: Context Stuffing
When it comes to ChatGPT, Shlok Khemani has great research notes on how OpenAI is structuring memory for individual users. I was aware of the high-level architecture for the most part, but he has some great prompts to actually view for yourself what data OpenAI is personalizing your version of ChatGPT with.
ChatGPT's system is built on three types of data that work together to create a comprehensive user profile (I'm using slightly different terminology from Khemani here):
User metadata captures how you use the service: your device information, conversation patterns, topic preferences, and usage statistics. When you ask about a camera problem and ChatGPT immediately gives iPhone-specific advice without asking your device type, this metadata is why.
Recent conversations are a history of your latest conversations, complete with timestamps and topics. Interestingly, only your messages are included, not ChatGPT's responses, suggesting OpenAI has found that user queries alone provide sufficient context for continuity.
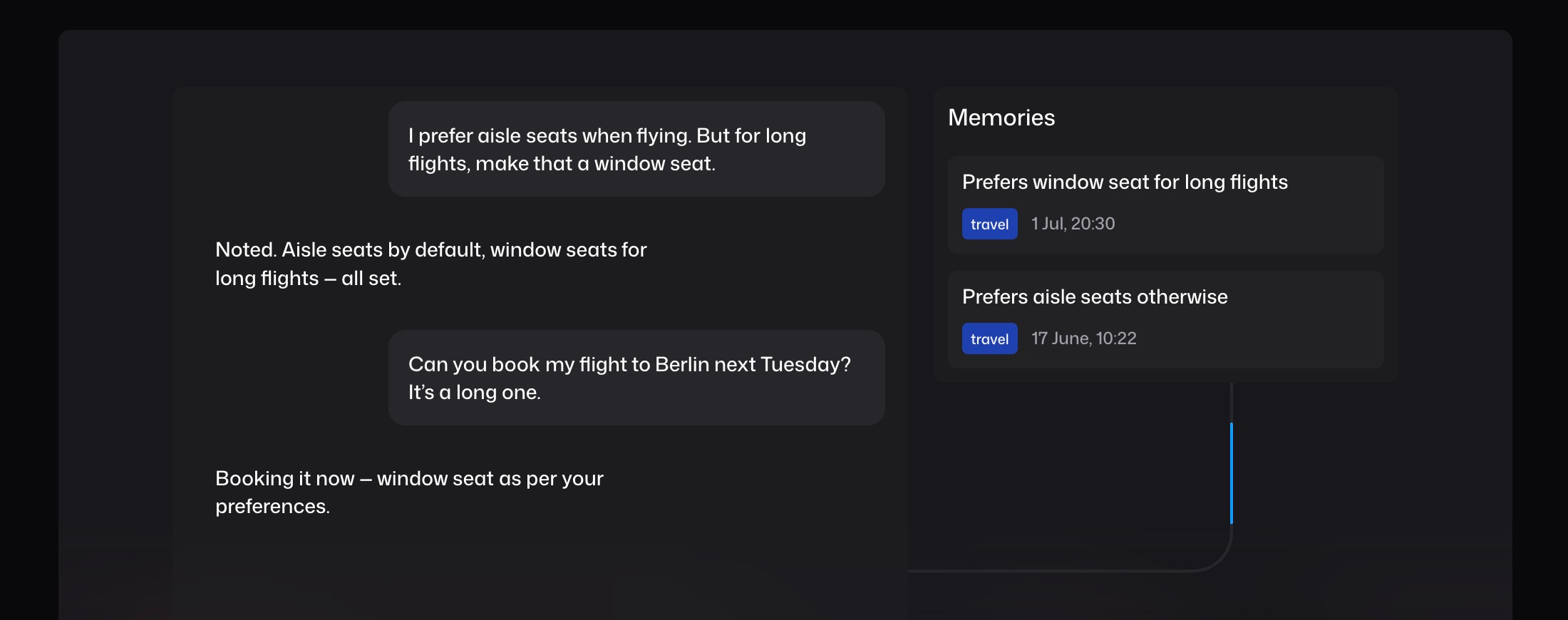
User memories are the traditional "memory" feature ChatGPT introduced in 2024. They are explicit, user-controlled facts: "I'm allergic to cats," "I prefer Python over JavaScript," "I live in San Francisco." These act as a source of truth that can override information from other components. They're visible in your settings and can be deleted from your account2.
The creation of ChatGPT memories happens in two distinct ways. The process is straightforward for explicit memories - when you tell ChatGPT "Remember that I'm vegetarian," it directly stores these facts in your user memory profile. But it can also save (what it deems to be) important information automatically, even if you don't explicitly ask for it3.
What surprised me is how "dumb" this system is under the hood. Rather than using dynamic retrieval or sophisticated knowledge management, OpenAI dumps all relevant memory data directly into your conversation's context window on every interaction. ChatGPT isn't searching vast historical data stores or making intelligent decisions about what context to surface - it's relying on the raw computational power of large context windows to brute-force the personalization problem.
Claude's Philosophy: Dynamic Search
At a high level, Claude manages personalization in a remarkably similar way.
User metadata is passed on every message - albeit less than OpenAI, which includes fairly detailed account activity and usage statistics. And until recently, Claude didn't support declarative "memories" in the same way as ChatGPT. But it's now capable of remembering details about projects and preferences (though only for Team and Enterprise subscribers). According to their launch post, the feature is remarkably familiar:
Claude uses a memory summary to capture all its memories in one place for you to view and edit. In your settings, you can see exactly what Claude remembers from your conversations, and update the summary at any time by chatting with Claude. Based on what you tell Claude to focus on or to ignore, Claude will adjust the memories it references.
There is one big philosophical difference in how Claude remembers recent conversations: accessing a user's chat history is dynamic rather than included by default.
Claude uses two tools that function like web search or code execution. The conversation_search tool performs keyword and topic searches across your entire conversation history, while recent_chats provides time-based access to your past interactions. When you ask Claude to "remember our discussion about machine learning," you'll see it actively search your history and synthesize relevant conversations.
Both approaches have merit, but they also have challenges. ChatGPT's auto-generated memories may not be perfectly accurate - they mix outdated plans with enduring preferences, and there's no easy way to correct misconceptions once they're baked into the AI-generated summaries. Claude's approach avoids these issues, but requires more user effort and doesn't capture the subtle patterns that emerge from passive observation.
But tradeoffs like these are common among the other architectures and approaches startups are using to craft their own memory systems.
Memory as a Service
Perhaps because of ChatGPT's popularity, memory is quickly becoming table stakes for cutting-edge AI app developers. Users expect personalization, context retention, and the ability to pick up conversations where they left off.
The absolute simplest form of "memory" is simply having multi-turn conversations - a near ubiquitous UX pattern that's mostly handled out of the box with AI frameworks and LLM APIs. However, a slightly more sophisticated approach involves Retrieval-Augmented Generation (RAG) paired with vector databases. You store conversation history and user information as vector embeddings, then use similarity search to retrieve relevant context when generating responses.
It's straightforward in theory, but quickly becomes complex in practice: How do you decide what to remember versus forget? How do you handle conflicting information? How do you balance recency with relevance? This complexity has spawned a new category: memory-as-a-service startups. Companies like Mem0 and Zep are building dedicated platforms that handle the intricacies of AI memory so developers don't have to.
Let's take Mem0 as an example. They use a hybrid system combining vector databases with graph databases, allowing them to understand not just individual facts but relationships between entities. Unlike traditional RAG, which retrieves information from static documents, Mem0 claims that its platform can adapt and learn from ongoing interactions. When a user's preferences change or new information contradicts old assumptions, the system can update dynamically rather than simply adding conflicting data.
Looking at the category more broadly, the conceptual architecture for any memory system involves several key components: a storage layer (vector databases, graph databases, or traditional databases depending on your needs), a retrieval mechanism (similarity search, keyword matching, or hybrid approaches), an update system (how new information modifies or contradicts existing memories), and policies for retention and forgetting (what gets remembered long-term versus what gets discarded).
None of these components are foolproof, especially in isolation. And each one comes with its own set of settings, optimizations, and potential footguns. For developers working on personalized AI products, there's a real decision to be made about whether to focus on simplicity or control. Building your own memory system offers maximum customization but requires significant engineering investment. Memory-as-a-service platforms provide sophisticated functionality but introduce dependencies and potential vendor lock-in4.

The Thorny Questions Ahead
By many accounts, real AI memory is going to be a key stepping stone towards AGI. And so it's fairly remarkable how convoluted (if not crude) many of the current approaches are.
Yet even with these basic attempts at memory, we're approaching some difficult questions, as the same capabilities that make AI assistants more helpful also create new risks and ethical dilemmas.
For example, to what extent should memories be visible and/or editable? I'd argue it's important for users to know what their AIs are being told, and have the ability to modify that context - especially if memories can be incorrect or hallucinated. AI systems can confidently "remember" things that never happened or misinterpret conversations in ways that compound over time. These false memories can become embedded in user profiles, affecting future interactions in subtle but significant ways.
And how long will it be before we see advertisements based on our chats? This strikes me as nearly inevitable at this point - Perplexity has already started experimenting with display ads in its chats, and OpenAI has taken some steps that look remarkably like its getting ready to monetize its free users5.
I thought SemiAnalysis had a compelling argumenton how this might work:
The [GPT-5 router] release can now understand the intent of the user’s queries, and importantly, can decide how to respond. It only takes one additional step to decide whether the query is economically monetizable or not.
...
Products that are highly likely to be purchased with agentic purchase would pay for referral fees, such as groceries, ecommerce purchases, flights and hotels. This could be a consumer SuperApp that would be an “agent” for day to day planning, purchases, and basic services.
The user wouldn’t pay via a cost of a subscription, but by transaction fees or ad take rates on purchase. The AI agent could still make the best response output but drive extremely high value business to a company almost instantly, in which the business would be willing to pay take rates on.
But in a world where this exists, to what extent should AIs be able to refer us products and services when we treat them like companions, or even therapists? As AI systems become better at remembering our vulnerabilities, preferences, and emotional patterns, they'll become better at influencing our purchasing decisions.
The technology is advancing faster than our frameworks for thinking about these implications. We don't yet have industry standards, regulatory guidelines, or even settled best practices for how AI memory should work. We're essentially running a massive experiment with human psychology and relationship dynamics, with billions of people as unwitting participants.
The evolution from goldfish to elephant memory in AI is remarkable from a technical perspective. But as these systems become more capable of remembering everything about us, we'd better start thinking seriously about whether we want them to - and what happens if we can't control what they can forget.
If you’re interested in learning more about building AI features like these, I’m working on an AI engineering course, and I want your feedback to help tailor the content. Sign up for updates here.
This creates an interesting tension with current marketing claims. Every new model launch comes with near-perfect "needle in a haystack" benchmark results - tests where the AI successfully finds a specific piece of information hidden in massive amounts of text. But these controlled benchmarks may not reflect real-world performance, where the "needle" isn't always clearly defined and the "haystack" contains genuinely relevant but distracting information.
Khemani also mentions a fourth kind of memory, composed of AI-generated summaries that ChatGPT creates periodically from your conversation history - dense, interconnected paragraphs that you can't see or directly edit. In Khemani's case, this data included dozens of specific products and brands that he uses. However, in tinkering with my own history, I found it nearly identical to my "user memories" - so I'm still trying to understand whether it's a real feature, given OpenAI's opaque documentation here.
The system appears to use some form of importance scoring to identify details worth preserving: your preferences (communication style, formatting preferences, dietary restrictions), your background (professional role, personal projects), and your situation (family status, current challenges). Though the precise mechanism is still unclear.
Of course, there's also "vendor lock-in" with consumer models too. What happens to your memories if you switch from ChatGPT to Claude?
From the same SemiAnalysis article:
It all starts with OpenAI’s decision to hire Fidji Simo as CEO of Applications in May. Let’s look at her background because it’s telling. Fidji was at Ebay from 2007 to 2011, but her defining career was primarily at Facebook. She was Vice President and Head of Facebook, and she is known for having a superpower to monetize. She was critical in rolling out videos that autoplay, improving the Facebook feed, and monetizing mobile and gaming. She might be one of the most qualified individuals alive to turn high-intent internet properties into ad products, and now she’s at the fastest-growing internet property of the last decade that is unmonetized.
Charlie have you tried the Huxe AI app? Major HER vibes right there.
Thanks for the memory management and services to know about the same for the good 😊