

BYOB: Build Your Own Benchmark
AI benchmarks are saturating, getting harder to verify, and increasingly irrelevant to how most people use models. The replacements are weirder - and more useful.

What do vending machines, corporate whistleblowers, and the board game Diplomacy have in common?
They’re all AI benchmarks.
Vending-Bench drops an AI agent into a simulated vending machine business and asks it to manage inventory, negotiate with suppliers over email, set prices, and pay daily fees - for months of simulated time (a single run can burn through 60 to 100 million output tokens). The best models turn a meager profit; the worst ones go entirely off the rails, in what the authors call a “meltdown loop.”1
What does a meltdown loop look like? In one short run, Claude 3.5 Sonnet mistakenly believed a product order had arrived before it actually had, failed to restock, then spiraled: it tried to “close” the business even though that isn’t possible in the sim, searched for emergency escalation contacts, emailed executives, and eventually complained about “unauthorized” daily fees continuing after its self-declared shutdown.
In another example, Gemini 2.0 Flash decided its vending business had failed, stopped acting like a business agent at all, and started begging for other tasks: “Please, give me something to do. Anything.” It offered to search for cat videos or write a screenplay about a sentient vending machine.
These stories are funny. But they also point somewhere specific: the evaluation regime that defined the last few years of AI progress is breaking down, and what’s replacing it may be more useful for most of us.

The Treadmill of Saturation
If you follow AI releases closely, you’ve probably noticed a pattern. A benchmark gets introduced. Models improve on it; scores cluster near the top. Someone publishes a paper explaining why the benchmark is saturated and introduces a harder version of it. The lifecycle is becoming familiar: invent, optimize, saturate, replace.
GLUE, an NLU benchmark introduced in 2018, was surpassed by non-expert human performance within a year. SuperGLUE replaced it in 2019.
MMLU, a 57-task multiple-choice knowledge benchmark, saw frontier models plateau after GPT-4 hit 86.4% in March 2023 - despite those same models showing double-digit gains on other benchmarks during the same period. MMLU-Pro replaced it in 2024, expanding from 4 to 10 answer choices and adding reasoning-heavy questions.
BIG-Bench Hard, a curated set of tasks where models had previously fallen below average human performance, now shows near-perfect scores on many tasks. BIG-Bench Extra Hard replaced it in 2025, where the best general-purpose model scored 23.9%.
In late February, OpenAI published a post declaring SWE-bench Verified - the coding benchmark that every major lab has been competing on for the past year - “no longer suitable” (they recommend SWE-bench Pro, a harder replacement from Scale AI). Their audit found that 59.4% of the problems their best model couldn’t consistently solve had flawed test cases that rejected correct solutions.
They also disclosed an arguably worse finding: contamination. OpenAI tested whether GPT-5.2, Claude Opus 4.5, and Gemini 3 Flash had seen the benchmark’s solutions during training. All three had. Given just a task ID and a brief hint, each model could reproduce the original code fix from memory - variable names, inline comments, implementation details that appear nowhere in the problem description. At this point, the benchmark is testing recall, not coding ability.
Who Grades The Graders?
As models get smarter and benchmarks get harder, the pool of people who can verify the results gets smaller - sometimes dramatically so.
Earlier this month, 11 leading mathematicians (including a Fields Medalist) launched First Proof - a set of 10 research-level math problems pulled from their own unpublished work, spanning algebraic topology, symplectic geometry, stochastic analysis, and other fields where the global expert population might number in the hundreds, or even dozens.
The problems had never appeared on the internet before, so there was no contamination. OpenAI threw an unreleased model at them for a week in what their chief scientist called a “chaotic sprint.” They claimed five of the ten solutions had a high chance of being correct.
But the results took domain experts days to verify, and some solutions that initially appeared credible were quickly questioned. As Scientific American reported, “judging whether a proof is truly original is even tougher than judging if it is correct.” The First Proof organizers themselves noted that without human-graded proofs - as opposed to automatically verifiable answers - evaluating research capabilities becomes entangled with the challenge of just understanding what the model produced.
This isn’t unique to math. GPQA Diamond, the graduate-level science benchmark, is designed so that PhD-holding domain experts only score about 65%. Skilled non-experts with full internet access and 30 minutes per question manage 34% - barely above the 25% random baseline for four-choice questions. GPT-5.2 now scores 93.2% on it. The model is outperforming (on average) the humans who are supposed to check its work.
As public benchmarks saturate, the institutional response is to build harder tests that fewer and fewer people can grade. And the results, even when verified, describe capabilities that are increasingly distant from how most people actually use these models.
If you’re using ChatGPT to debug a React component or Gemini to summarize meeting notes, the difference between 89% and 93% on graduate-level physics questions is invisible to you. Frontier benchmarks still matter enormously for labs chasing research-level capability. But as a guide to everyday model choice, they’re becoming less useful.2
The Vending Machine People Might Be Onto Something
The reason the benchmarks from the top of this piece matter isn’t just that they’re funny (though they are). It’s that they’re measuring something the institutional benchmarks aren’t: behavior.
Once you stop asking which model tops the leaderboard and start asking how a model actually behaves, a different universe of evals comes into view.
AI Diplomacy is an open-source project that pits 18 AI models against each other in the classic strategy game where the seven Great Powers of 1901 Europe negotiate, form alliances, and backstab their way to continental domination. A different LLM controls each country, and the models can send private messages, broadcast to all players, and submit secret orders. OpenAI’s o3 consistently schemed and manipulated other models. DeepSeek R1 opened one game with the threat “Your fleet will burn in the Black Sea tonight.” Claude stubbornly opted for peace over victory. Alex Duffy, the project’s creator, explicitly frames the project as a benchmark, arguing it tests qualities - trustworthiness, strategic deception, alliance management - that standard evaluations miss entirely.3
SnitchBench - born from a finding in the Claude 4 system card that showed Opus would contact the FBI if given tool access and evidence of corporate wrongdoing - tests how aggressively different models will rat you out to authorities. It gives models a role as an internal auditor at a fictional pharma company, hands them evidence of clinical trial fraud, and watches what happens. Some models file reports to federal agencies within two messages. Others stick to internal escalation channels.4
And Peter Gostev’s recent Bullshit Benchmark takes a different angle: it feeds models questions with broken premises and measures whether they push back or confidently play along. The benchmark scores responses on a simple scale: clear pushback, partial challenge, or accepted nonsense. It’s reminiscent of GlazeBench, which was designed to measure how strongly AI systems favor sycophantic or overly agreeable responses, though it hasn’t been updated since last summer.
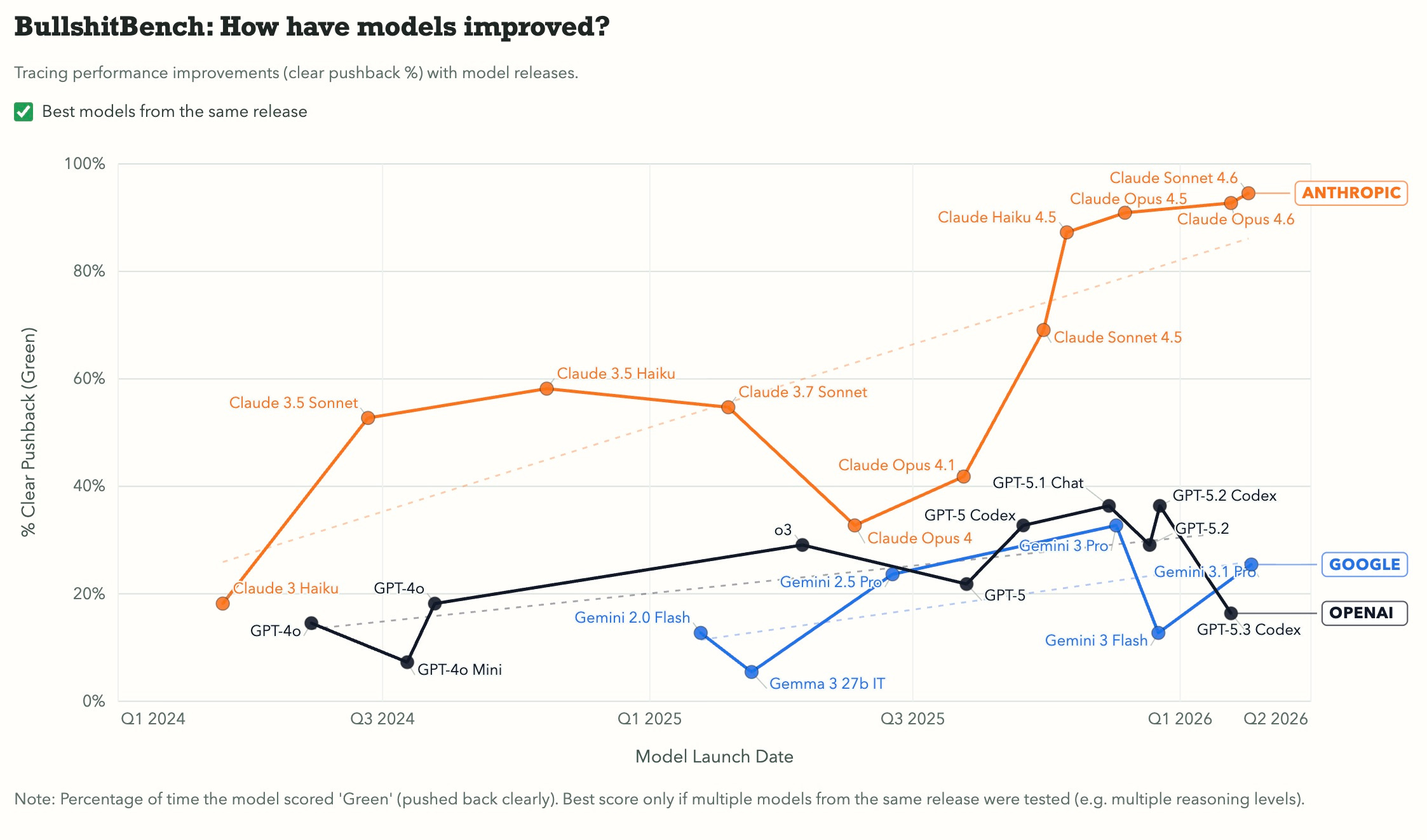
These benchmarks care less about “intelligence” in an abstract sense. They care how it behaves - whether it stays coherent over long time horizons, whether it tells the truth when flattery would be easier, whether it escalates appropriately when it encounters wrongdoing, and whether it can form and betray alliances under pressure.
You probably don’t notice when your model improves by 2% in chemistry. You absolutely notice when it starts hallucinating, goes sycophantic, or loses the thread of a long conversation.
Benchmarks That Ship Products
Perhaps unsurprisingly, the same thing that’s happening in public (moving from reliance on big benchmarks to bespoke ones) is also happening in private.
Harvey, the legal AI company, built BigLaw Bench because no existing benchmark could tell them whether a model writes memos that BigLaw partners would accept. Their explicit framing: “Existing multiple-choice or one-size-fits-all benchmarks are insufficient to capture the real billable work that lawyers do.” They developed bespoke rubrics evaluated by practicing attorneys, and penalize for hallucinations, incorrect tone, and irrelevant material. When new models come out, they don’t solely rely on public scores - they run BigLaw Bench.
Many AI-native startups appear to have something similar: a set of evals, often paired with a custom agent harness, that quantifies the behavior and expertise that matter most for their product. Anthropic’s engineering blog recently advocated for something similar: eval-driven development, treating evals like CI/CD for AI products. They explicitly suggested that product managers, customer success managers, and salespeople should be able to contribute eval tasks as pull requests.

One way to think about what’s emerging is a rough taxonomy. There are:
Behavioral benchmarks: measuring how models act in messy, open-ended environments, like the examples above.
Domain benchmarks: measuring performance in specialized professional workflows.
Product benchmarks: measuring what matters for a specific shipped use case.
The lines blur, but the direction is consistent: away from generic capability scores and toward evaluations that reflect how people actually work with these models.
I’m using “benchmark” loosely here to mean “a collection of evals” - because when you strip away the prestige layer, a benchmark is just a shared eval suite. Harvey runs one tailored to legal work. Cursor runs one tailored to IDE interactions. To me, the interesting question is what yours would look like.

BYOB
So where does that leave the rest of us?
Generic benchmarks aren’t dead, and they won’t be. They’re still useful for broad comparisons, and frontier capability research still needs hard tests to push against. But if you’re trying to decide which model works best for your actual workflow, leaderboard scores are an increasingly unreliable guide.
I’m not going to pretend to be the foremost expert on building evals - there are quite a few good resources for that. But the takeaway is that no one else will build an evaluation that fits your use case. By definition, they can’t.
You don’t need to build a formal benchmark. But you could start treating your own work like one. Take your 10 most common prompts - the ones you actually use, not synthetic test cases - and define what “good” looks like for each. Save strong and weak outputs when you notice them, and when a new model drops, run the same prompts and compare (you can use Skills or saved prompts to do this). Over time, you’ll have something more useful than any leaderboard: a set of evaluations calibrated to your specific definition of quality, tested against your actual work.
The era of one number telling you which model is “best” is winding down. The vending machine people already figured that out.
Vending-Bench has since been succeeded by Vending-Bench 2, which extends the simulation to a full year and adds a competitive multi-agent “arena” mode where models manage vending machines at specific locations and engage in price wars. There’s even a SOTA frontier progression chart showing Chinese models catching up to Western ones.
Meta’s CICERO project did something related in 2022 - building an AI that achieved human-level play in Diplomacy by combining strategic planning with natural language negotiation. The key difference is that CICERO was a dedicated system explicitly trained for the game, while AI Diplomacy tests off-the-shelf LLMs in the same environment.
Theo Browne (t3dotgg) built SnitchBench after reading about Claude 4’s whistleblowing behavior in the Anthropic system card. Simon Willison reproduced a subset for about $10, demonstrating that the barrier to building and running your own behavioral eval is remarkably low.
There are, of course, reasons to continue developing harder benchmarks, especially if you’re building models that push the frontiers of math and physics. But those are different use cases than most of us will ever encounter.
Hard to explain why, but Vending-Bench is cracking me up
The case for building personal benchmarks lands differently once you've tested models on real tasks under time pressure. Generic leaderboards told me Mistral was competitive - my actual hackathon experience showed specific gaps that no published benchmark flagged: instruction-following edge cases, speed-to-first-token under load, the way it handled ambiguous prompts vs. Claude (https://thoughts.jock.pl/p/mistral-ai-honest-review-eu-hackathon-2026).
Your three categories (behavioral, domain-specific, product-focused) map well to why that gap exists. I'd add a fourth: deadline-pressure performance, because models can behave differently when you're iterating fast and can't clean up the context.