

AI Zoology: Why are there so many animal models?
Inside the emerging model menagerie.


If you've spent any time reading research papers on large language models, you've seen a handful (or more) of models named after animals: Llama, Alpaca, Vicuna, Falcon, Orca, and more. And if you're like me, you probably wondered what they were, and how they were different.
The short answer: they're mostly descended from Llama, Meta's original foundation LLM. The ones that aren't are choosing to keep the meme going.
The long answer: using Llama as a base, researchers have experimented with new data sources, new training techniques, and new ways of building chatbots for a fraction of the usual price. Let's dive in and trace the lineage of the LLM "animal kingdom."
The evolution of LLaMa
Meta released the first version of Llama (originally named LLaMa) in February 2023 in a blog post and paper detailing the model's training and architecture. Four model sizes were trained at release: 7, 13, 33, and 65 billion parameters. Unlike OpenAI, which has only made its models accessible via API, Meta released Llama's weights to the research community under a non-commercial license. However, Llama's weights were publicly leaked via 4chan within a week of the release.
However, Llama gained a lot of attention because of how compact it was - the 13B parameter model performed better than GPT-3 on most benchmarks, despite the latter having 175B parameters. And the open-source community quickly figured out how to make Llama run on almost any device. This meant it was an excellent choice for building open-source projects (except for the non-commercial license).
Then in July, Meta announced Llama 2, the second generation of Llama. Like its predecessor, the model was trained in multiple sizes: 7, 13, and 70 billion parameters. While the architecture remained largely the same (see below), there was a much greater focus on training data, fine-tuning, and safety with Llama 2. Case in point: the release also included Llama 2 - Chat, a model fine-tuned on conversational use cases.
We previously covered many of the details of Llama 2:

Welcome to the jungle
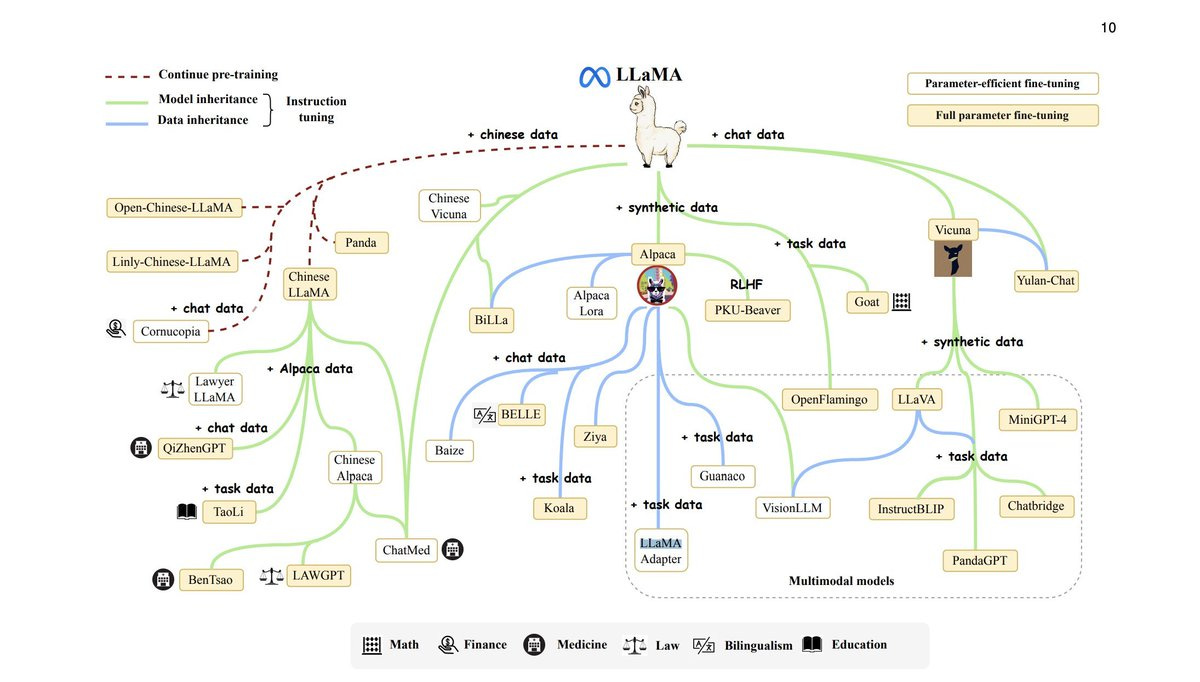
After Llama 1's release, the machine-learning community took the model and ran with it. It was converted to C/C++, then other languages. It was ported to a Raspberry Pi. It was integrated into tools like Langchain and LlamaIndex.
But it was also fairly limited, as modern LLMs go. It wasn't fine-tuned for helpfulness or safety. And unlike ChatGPT, it wasn't designed for conversations or instructions. So researchers and developers started layering fine-tuning on top, which led to its many descendants.

Alpaca
In March 2023, Stanford researchers released Alpaca, the first major Llama descendant. Since the world was (and continues to be) dazzled by ChatGPT, Alpaca was the first model to add instruction-following capabilities to Llama.
The fine-tuning strategy was novel: the researchers took a shortcut by re-training Llama using examples of instruction-following from an OpenAI model (text-davinci-003). Instead of spending thousands for workers to perform RLHF, Alpaca was trained with about $600 worth of API calls.

Vicuna/StableVicuna
Two weeks after Alpaca, the LMSYS Org team took the approach a step further with Vicuna. Using 70,000 ChatGPT conversations, the Vicuna team fine-tuned Llama for a cost of about $300.
The original Vicuna model was a simple demo, and by the authors admission not particularly well tested. But Stability AI used Vicuna as a base to build StableVicuna, a significantly better trained model. StableVicuna used multiple new datasets (including Alpaca's examples and an Anthropic training set) to improve Vicuna's instruction-following and safety capabilities. The result was a model that could do basic math and programming when asked, improving its predecessors.
Koala
Not to be outdone by Stanford, Berkeley AI Research (BAIR) released Koala in April 2023. Like its cousins, Koala is a fine-tuned version of Llama focused on conversation data. It used dialogue data scraped from the web (including ChatGPT conversations) and public datasets.
Orca
Over time (and by time, I mean a few months), using publicly available instruction examples to fine-tune a language model became more structured. Using ChatGPT and GPT-4 data, Microsoft released its fine-tuned variant, Orca. Orca used a much larger ChatGPT dataset than previous iterations. Instead of relying on publicly scraped examples, it used the ChatGPT/GPT-4 APIs to generate examples in a standardized way.

Stable Beluga
Following in Microsoft's footsteps, Stability AI then released Stable Beluga 1 and 2. Using Llama 1 and 2 as a base, the two models use a much smaller training set than Orca. Unlike Orca, Stability AI released Stable Beluga as a model on Hugging Face for people to download and run themselves.

Falcon
While not actually a descendant of Llama, it's worth mentioning Falcon as it's easily confused for one. Falcon is a family of models (7B and 40B) that were built with “custom tooling and a unique data pipeline.” Before Llama 2, Falcon 40B was the first truly open model that came anywhere close to ChatGPT’s capability.
Falcon was also released with fine-tuned variants, meaning companies could go straight to running their own ChatGPT-like model. The Technology Innovation Institute, a research organization funded by the Abu Dhabi government, is behind the model, and also plans to release a chatbot.
Extinction is the rule. Survival is the exception.
– Carl Sagan
Natural selection
Before researching this, I didn't know much about the family tree of LLMs. What surprised me was how limited they were - most were built as research experiments and weren't designed for commercial or production usage. They mostly showed how to mimic ChatGPT using examples from ChatGPT.
But they weren't reliable tools to build with. They were mainly released under non-commercial licenses, and were only tested in narrow benchmark situations. And while many claimed to approach the quality of GPT-3.5, GPT-4 still outperforms all of them by a decent margin. Ultimately though, most have been put on the path to extinction by Llama 2. The newest version of Llama is better trained, more capable, more freely licensed, and even has a native chat variant.
That said, Llama 2 will become the next platform for experimentation. Expect many more fine-tuned versions (though maybe without the animal names). As we discussed previously:
That decision between open-source and proprietary will only add to the AI platform quicksand as fine-tuned versions of Llama 2 become more enticing. Not to mention the advancement of Llama-based tooling, libraries, and agents. If the family tree of Llama 1 is anything to go by, we’re about to see an explosion of models based on Llama 2.